原文链接:http://www.cnblogs.com/blog5277/p/8580007.html
原文作者:博客园--曲高终和寡
*********************分割线**********************
由于新入职了一家公司,准备把我放进大数据的组里面
我此前对大数据,仅仅停留在听说过这个名词上,那么这次很快就要进入项目,一边我自己在学习,一边也把教程分享出来,避免后来之人踩我所踩过的坑
*********************分割线**********************
前面两篇文章讲了如何配置Hadoop,Scala,spark,那么这一篇就开始写第一个基于spark的数据分析小项目了(我也是照搬教程的,可能跟很多人的相同)
一.待分析数据来源
你们可以自己准备,也可以跟教程一样直接用spark目录下的README.md
我的文件的绝对路径就是 :
/Library/Spark/spark-2.3.0-bin-hadoop2.7/README.md
二.在IDE里面新建一个maven项目,引入这个包:
<!-- https://mvnrepository.com/artifact/org.apache.spark/spark-core --> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-core_2.11</artifactId> <version>2.3.0</version> </dependency>
三.开始两个练手小程序
1.统计类型的:统计包含X的行数
每一句的意义我都标了详细的注释,看注释就OK了
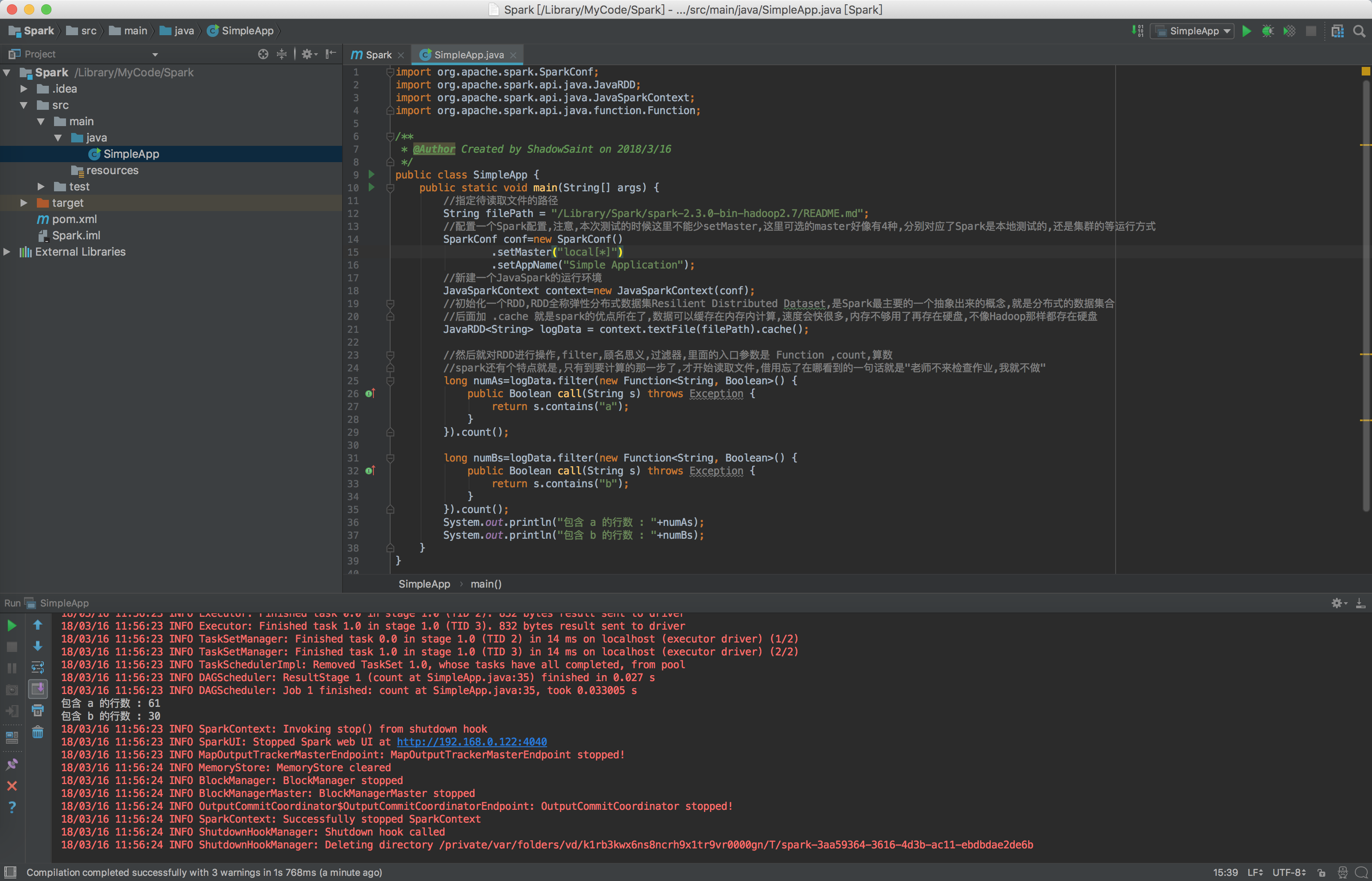
import org.apache.spark.SparkConf; import org.apache.spark.api.java.JavaRDD; import org.apache.spark.api.java.JavaSparkContext; import org.apache.spark.api.java.function.Function; /** * @Author Created by ShadowSaint on 2018/3/16 */ public class SimpleApp { public static void main(String[] args) { //指定待读取文件的路径 String filePath = "/Library/Spark/spark-2.3.0-bin-hadoop2.7/README.md"; //配置一个Spark配置,注意,本次测试的时候这里不能少setMaster,这里可选的master好像有4种,分别对应了Spark是本地测试的,还是集群的等运行方式 SparkConf conf=new SparkConf() .setMaster("local[*]") .setAppName("Simple Application"); //新建一个JavaSpark的运行环境 JavaSparkContext context=new JavaSparkContext(conf); //初始化一个RDD,RDD全称弹性分布式数据集Resilient Distributed Dataset,是Spark最主要的一个抽象出来的概念,就是分布式的数据集合 //后面加 .cache 就是spark的优点所在了,数据可以缓存在内存内计算,速度会快很多,内存不够用了再存在硬盘,不像Hadoop那样都存在硬盘 JavaRDD<String> logData = context.textFile(filePath).cache(); //然后就对RDD进行操作,filter,顾名思义,过滤器,里面的入口参数是 Function ,count,算数 //spark还有个特点就是,只有到要计算的那一步了,才开始读取文件,借用忘了在哪看到的一句话就是"老师不来检查作业,我就不做" long numAs=logData.filter(new Function<String, Boolean>() { public Boolean call(String s) throws Exception { return s.contains("a"); } }).count(); long numBs=logData.filter(new Function<String, Boolean>() { public Boolean call(String s) throws Exception { return s.contains("b"); } }).count(); System.out.println("包含 a 的行数 : "+numAs); System.out.println("包含 b 的行数 : "+numBs); } }
注意,本次测试,在你还没弄清楚spark到底干嘛的时候,一定要在SparkConf那里配置 setMaster,否则的话会报如下错误:
org.apache.spark.SparkException: A master URL must be set in your configuration
好了,照我上面那样整完,项目就可以正常运行了,输出了一大堆东西,如下:
2.分类的:将一个文本拆分,看总共出现了多少单词,每个单词出现了多少次
import org.apache.spark.SparkConf; import org.apache.spark.api.java.JavaPairRDD; import org.apache.spark.api.java.JavaRDD; import org.apache.spark.api.java.JavaSparkContext; import org.apache.spark.api.java.function.FlatMapFunction; import org.apache.spark.api.java.function.Function2; import org.apache.spark.api.java.function.PairFunction; import scala.Tuple2; import java.util.Arrays; import java.util.Iterator; import java.util.Map; /** * @Author Created by ShadowSaint on 2018/3/16 */ public class CountWords { public static void main(String[] args) { //指定待读取文件的路径 String filePath = "/Library/Spark/spark-2.3.0-bin-hadoop2.7/README.md"; //配置一个Spark配置,注意,本次测试的时候这里不能少setMaster,这里可选的master好像有4种,分别对应了Spark是本地测试的,还是集群的等运行方式 SparkConf conf=new SparkConf() .setMaster("local[*]") .setAppName("Simple Application"); //新建一个JavaSpark的运行环境 JavaSparkContext context=new JavaSparkContext(conf); //初始化一个RDD,RDD全称弹性分布式数据集Resilient Distributed Dataset,是Spark最主要的一个抽象出来的概念,就是分布式的数据集合 //后面加 .cache 就是spark的优点所在了,数据可以缓存在内存内计算,速度会快很多,内存不够用了再存在硬盘,不像Hadoop那样都存在硬盘 JavaRDD<String> input = context.textFile(filePath).cache(); //以空格为界,划分为单词 JavaRDD<String> words=input.flatMap(new FlatMapFunction<String, String>() { public Iterator<String> call(String s) throws Exception { return Arrays.asList(s.split(" ")).iterator(); } }); //转化为键值对并计数 JavaPairRDD<String,Integer> counts=words.mapToPair(new PairFunction<String, String, Integer>() { public Tuple2<String, Integer> call(String s) throws Exception { return new Tuple2<String, Integer>(s,1); } }).reduceByKey(new Function2<Integer, Integer, Integer>() { public Integer call(Integer integer, Integer integer2) throws Exception { return integer+integer2; } }); //输出 Map<String,Integer> map=counts.collectAsMap(); for (String key:map.keySet()){ System.out.println(key+" : "+map.get(key)); } } }
运行后,输出结果为:
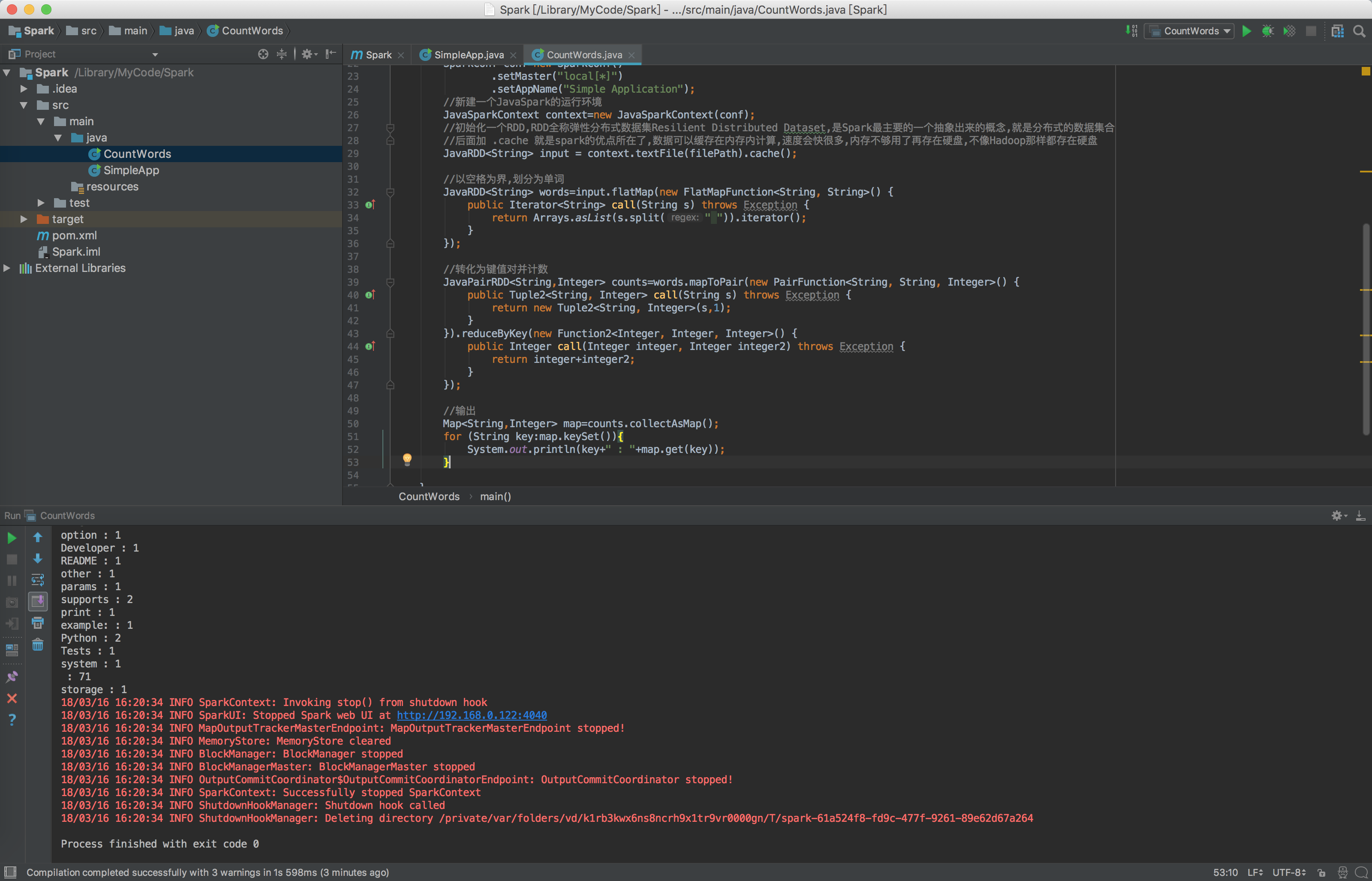
然后根据出现频率,排个序,就能做出单词出现频率热力图了.
再配合已有的数据,比如说爬虫爬一下今天微博的数据(中文的话需要配合中文分词工具),就能知道,今天微博讨论最热的词是什么了(然而我就随便猜一下,频率最高的字是哈,手动滑稽)
那么,现在已经很接近传说中的大数据了,不是么?