Fork-Join框架
分而治之:Fork/Join框架
分而治之是一种有效处理大量数据的方法,简单地说,如果你要处理1000个数据,但是又不具备处理它们的能力,那么你可以只处理其中的10个数据,再分阶段处理100次,将它们的结果进行合成,就是最终想要的结果。
在实际使用过程中,如果毫无顾忌的使用fork()方法开启线程进行处理,可能会导致线程过多而严重影响性能。所以在JDK中提供了一个ForkJoinPool线程池,对于fork()方法不急于开启线程,而是提交给这个线程池进行处理,以节省系统资源。
由于线程池的优化,实际的任务数量和线程数量并不会是一一对应的关系,一个物理线程需要处理多个任务,因此也需要任务队列。实际处理过程中,可能会有这种情况:
A线程的任务已经处理完成,B线程堆积了许多任务,这时候A线程就会帮助B线程,从B线程的任务队列中获取任务来处理,尽可能的达到平衡,同时,处理自己的任务的时候,从任务队列的顶部开始获取数据,帮助别的线程的时候,从底部获取数据,尽量避免竞争。
看一下ForkJoinPool线程池的一个重要的方法:
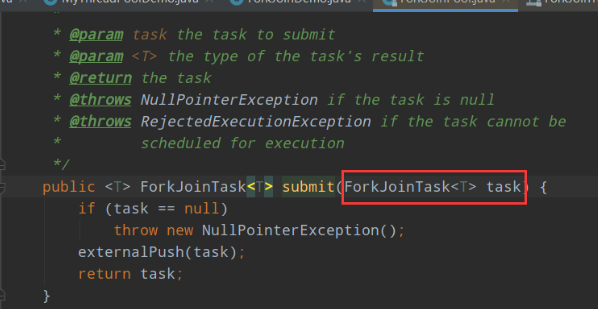
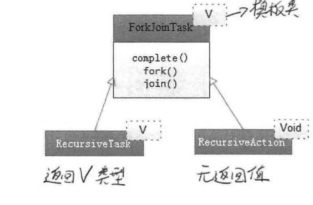
通过submit方法可以向线程池提交一个ForkJoinTask任务,所谓ForkJoinTask任务就是支持fork()方法分解及join()方法等待的任务。ForkJoinTask有两个重要的子类:带返回值和不带返回值的两个抽象类。我们可以自定义任务,根据需要选择继承抽象类!
计算0加到90000000L


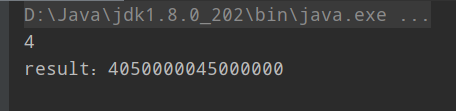
1 public class CountTask extends RecursiveTask<Long> { 2 private static final int THRESHOLD = 10000; 3 private long start; 4 private long end; 5 6 public CountTask(long start, long end) { 7 this.start = start; 8 this.end = end; 9 } 10 11 @Override 12 protected Long compute() { 13 long sum = 0; 14 if (end - start <= 10000) { 15 for (long i = start; i <= end; i++) { 16 sum += i; 17 } 18 } else { 19 //将任务先分成100个部分 20 long step = (end - start) / 100; 21 long pos = start; 22 List<CountTask> taskList = new ArrayList<>(); 23 for (int i = 0; i < 100; i++) { 24 long last = pos + step; 25 if (last > end) 26 last = end; 27 CountTask task = new CountTask(pos, last); 28 task.fork(); 29 taskList.add(task); 30 pos = last + 1; 31 } 32 33 for (CountTask task : taskList) { 34 sum += task.join(); 35 } 36 } 37 return sum; 38 } 39 40 /** 41 * 计算0加到90000000L 42 * @param args 43 * @throws ExecutionException 44 * @throws InterruptedException 45 */ 46 public static void main(String[] args) throws ExecutionException, InterruptedException { 47 long start = System.currentTimeMillis(); 48 CountTask task = new CountTask(0, 90000000L); 49 ForkJoinPool pool = new ForkJoinPool(); 50 ForkJoinTask<Long> result = pool.submit(task); 51 long end = System.currentTimeMillis(); 52 System.out.println(end-start); 53 System.out.println("result:"+result.get()); 54 } 55 }
结果如下:
如果使用单线程累加计算:
1 public class CountDemo { 2 public static void main(String[] args) { 3 long start = System.currentTimeMillis(); 4 long sum = 0L; 5 for (long i = 0; i <= 90000000L; i++) { 6 sum += i; 7 } 8 long end = System.currentTimeMillis(); 9 System.out.println(end-start); 10 System.out.println("result:"+sum); 11 } 12 }
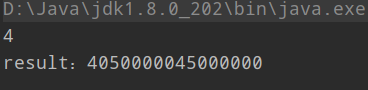
还是可以看到明显的差别的。
另外还有一点需要注意的是:fork方法会让子任务调用compute方法:
1 /** 2 * Fork/Join框架 3 */ 4 public class ForkJoinDemo { 5 public static void main(String[] args) throws ExecutionException, InterruptedException { 6 ForkJoinPool pool = new ForkJoinPool(); 7 MyFork task = new MyFork(1, 100); 8 ForkJoinTask<Integer> result = pool.submit(task); 9 System.out.println(result.get()); 10 pool.shutdown(); 11 } 12 } 13 14 /** 15 * 使用Fork/Join计算1加到100 16 */ 17 class MyFork extends RecursiveTask<Integer> { 18 private static final Integer JUDGE_VALUE = 10; 19 private int start; 20 private int end; 21 22 public MyFork(int start, int end) { 23 this.start = start; 24 this.end = end; 25 } 26 27 @Override 28 protected Integer compute() { 29 Integer result = 0; 30 if (end - start <= JUDGE_VALUE) { 31 for (int i = start; i <= end; i++) { 32 result += i; 33 } 34 } else { 35 System.out.println("fork"); 36 int mid = (end - start ) / 2 + start; 37 MyFork task1 = new MyFork(start, mid); 38 MyFork task2 = new MyFork(mid + 1, end); 39 task1.fork(); 40 task2.fork(); 41 result = task1.join() + task2.join(); 42 } 43 return result; 44 } 45 }
虽然在compute中只分成2个子任务,但是最终fork打印了15次,说明task1和task2实际上还被划分成了多个子任务执行。