将腾讯视频本地化的方法
第一步查找视频的地址
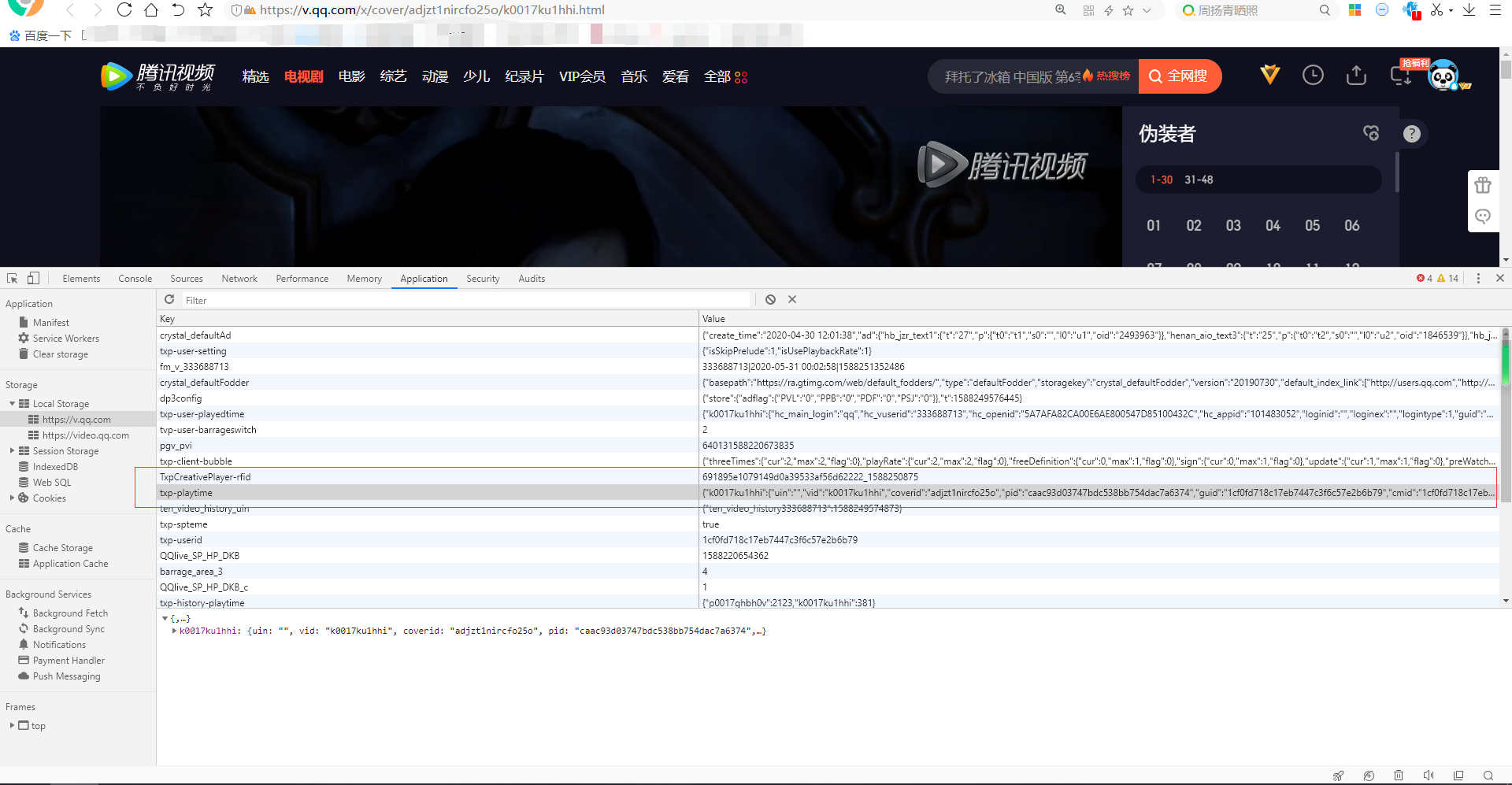
视频的真实地址 保存session中 如上图

找到视频地址后,使用python下载腾讯视频
2.这里使用的解释器python3.5
需要安装request 和 moviepy
安装request
pip install requests
安装moviepy
pip install moviepy
安装ffmpeg
如果之前没安装过 ffmpeg , 这个时候导入 moviepy 开始使用会报错的, 所以我们可以先用 imageio 自带的方法下载 ffmpeg
新建install_ffmpeg.py,并执行
文本文件
import imageio import ssl # 下面这一句不是必须的, 但是某些情况下访问 https 会报SSL证书不受信任, 加上这一句可以允许通过 ssl._create_default_https_context = ssl._create_unverified_context # 下载 ffmpeg 组件 imageio.plugins.ffmpeg.download()
3.下载视频文件
# -*- coding:utf-8 -*-
import os
import sys
import requests
import datetime
from moviepy.editor import *
def LoadVideo(url):
"""
腾讯视频下载
:param url: 视频m3u8地址
"""
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36"
}
download_path = os.getcwd() + "download"
if not os.path.exists(download_path):
os.mkdir(download_path)
# 新建日期文件夹
download_path = os.path.join(download_path, datetime.datetime.now().strftime('%Y%m%d_%H%M%S'))
os.mkdir(download_path)
# 获取第一层M3U8文件内容
all_content = requests.get(url).text
if "#EXTM3U" not in all_content:
raise BaseException("非M3U8的链接")
if "EXT-X-STREAM-INF" in all_content: # 第一层
file_line = all_content.split("
")
for line in file_line:
if '.m3u8' in line:
# 拼出第二层m3u8的URL
url = url.rsplit("/", 1)[0] + "/" + line
all_content = requests.get(url, headers=headers).text
file_line = all_content.split("
")
file_index = 0
for index, line in enumerate(file_line): # 第二层
if "#EXT-X-KEY" in line: # 找解密Key
method_pos = line.find("METHOD")
comma_pos = line.find(",")
method = line[method_pos:comma_pos].split('=')[1]
uri_pos = line.find("URI")
quotation_mark_pos = line.rfind('"')
key_path = line[uri_pos:quotation_mark_pos].split('"')[1]
key_url = url.rsplit("/", 1)[0] + "/" + key_path # 拼出key解密密钥URL
res = requests.get(key_url)
key = res.content
# 找ts地址并下载
if "EXTINF" in line:
unknow = False
# 拼出ts片段的URL
pd_url = url.rsplit("/", 1)[0] + "/" + file_line[index + 1]
file_index = file_index + 1;
res = requests.get(pd_url)
c_fule_name = str(file_index)
with open(os.path.join(download_path, c_fule_name + ".mp4"), 'ab') as file:
file.write(res.content)
file.flush()
merge_file(download_path)
def merge_file(path):
"""拼接视频
:param path: 相对路劲
"""
# 定义一个数组
video_list = []
# 访问 video 文件夹 (假设视频都放在这里面)
for root, dirs, files in os.walk(path):
# 按文件名排序
files.sort()
# 遍历所有文件
index = 0
for key in range(1, len(files)+1):
for file in files:
if os.path.splitext(file)[0] == str(key):
# 拼接成完整路径
file_path = os.path.join(root, file)
# 载入视频
video = VideoFileClip(file_path)
# 添加到数组
video_list.append(video)
else:
continue
# 拼接视频
final_clip = concatenate_videoclips(video_list)
# 生成目标视频文件
video_path= os.getcwd() + r"video"
if not os.path.exists(video_path):
os.mkdir(video_path)
video_path+=datetime.datetime.now().strftime('%Y%m%d_%H%M%S')+'.mp4'
final_clip.to_videofile(video_path, fps=24, remove_temp=False)
if __name__ == '__main__':
url='https://apd-efee4483a80104df1441e1d8f701e125.v.smtcdns.com/moviets.tc.qq.com/AcJSehqEQQedX5zyfYdOaiIaP5bJA6OKzlhHQuz0B_ks/uwMROfz2r5xgoaQXGdGnC2df64gVTKzl5C_X6A3JOVT0QIb-/GNxCYNllJLj9fPO-_rwnUNxpuWQtjyD_Zjvlivsev-7Juyk91J-Ftx1kClENGySmxH5dxtb84XO54QtHzXfRWdOBlMT5uGHZG5qL-zOWccM1r0pTM8QDCj4jIRr0hv5_RG0pY1zfrq5A9rz0ZOVzcpWRN-VhPiwwgSvwGiu7_3k/o0017ets4aa.321004.ts.m3u8?ver=4'
LoadVideo(url)
#video=VideoFileClip("./download/20200416_140017/1.mp4")
#videoClip = video.subclip(7,)
#videoClip.to_videofile("./download/20200416_140017/01.mp4", fps=20)#输出文件
提供一个可以看全网超前点播,全网免广告的方法,其实也有很多现成的破解网站,也想弄个,奈何扛不住现实(租用服务器费用太高),手机和电脑通用。
其实就是拼接一个动态网址:
固定前缀
https://api.sigujx.com/?url=
加上视频伪地址
https://v.youku.com/v_show/id_XNDYxNjI5Mjk4MA==.html?spm=a2hcb.12701310.app.5~5!2~5!3~5~5~5!7~5~5~5~A
结果:
https://api.sigujx.com/?url=https://v.youku.com/v_show/id_XNDYxNjI5Mjk4MA==.html?spm=a2hcb.12701310.app.5~5!2~5!3~5~5~5!7~5~5~5~A
这样就可以看了