----------------------------------------------------------
----------------------------------------------------------
网络结构论文摘要
之前大部分的论文都是基于深度图像的,这篇论文提出了一个从RGB图像中估计三维节点的方法,并提出了一个大规模的3D手部姿态的RGB数据集。
论文框架
论文一共用了三个网络结构进行手部节点的位置预测,首先用一个网络提取手部区域,并重新resize手部区域的大小,然后用一个网络定位2D手部关节点的位置,在根据2D的节点位置和先验知识恢复出3D节点位置。
相关工作
论文主要借鉴了 2D Human Pose Estimation, 3D Human Pose Estimation 和 Hand Pose Estimation的主要方法, 感觉之后视野应该要放开阔一些,熟悉 Pose Estimation 的各种方法, 重点掌握尝试并应用 Hand Pose Estimation 的各种方法。
现在主要存在的问题有两个:一个是还是依赖于深度图像,另一个是和数据集相关度比较大, 对数据集相关的手势预测的较为准确。
Hand pose representation
这一部分主要是为了解决大小手,坐标等问题。之前也考虑过这些问题,但是确实没有系统地区解决这个问题,看论文里面主要考虑了两个方面。
第一个方面是手的scale 问题,即使是分割出手的部分再进行resize,手的大小也会对预测结果产生影响,所以论文里面利用食指的第一根手骨的长度对手节点位置进行正则化。其次,绝对坐标系的使用会给预测带来困难,所以论文里采用了相对坐标系,以手掌节点的位置作为坐标原点对各个节点坐标进行平移。
HandSegNet
前两部分的网络借鉴了Wei论文中的网络结构,后者在论文中将2D人体检测问题转化为人体中心点分布的热图估计问题,而本文则是将2D手部检测问题转化为一个分割问题,最后得到了Hand mask,再对手部区域提取和正则化(Q1:没有预测得到各个节点的位置,如何进行正则化)
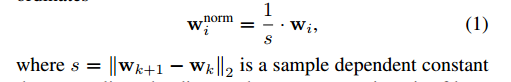
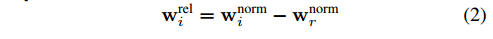
实现细节:

网络结构,(Conv+ReLu)+MaxPool+Bilinear Upsampling(上采样了四倍)
Loss 函数, standrad softmax + cross entropy loss
Learning rate 初始化为 1e-5,2W次迭代后变为1e-6,3W次迭代后变为1e-7
做了简单的数据増广,random color hue augmentation of 0:1 (待查)
PoseNet
这部分是对手部的每一个节点预测出一个二维的热图。也是采用 encoder-decoder的结构。
实现细节:
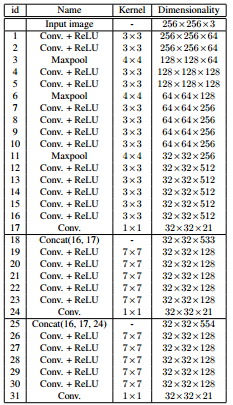
网络结构,(Conv+ReLu)+MaxPool,最后的预测利用了17,24和31层的feature map
Loss 函数,L2 Loss
需要注意的是对于Ground Truth的处理,利用了均值为关节点位置,方差为25个像素的高斯分布。而对于不可见的节点,所有的概率值设为0。
对于数据crop这部分,采用了两个方法进行,一个是对bounding box的中心加了0均值,方差为10的高斯噪声,另一个是对节点热图加了0均值,方差为1.5的高斯噪声。训练过程初始学习率1e-4,每一万次缩小十倍。
PosePrior
这部分应该是这篇论文的核心。在得到了21个节点的分布热图后,如何推出3D位置信息是需要考虑的问题。当然,手部区域是多视角的,所以有必要先对手部区域的视角进行一下限制,从而使预测过程对视角有一定的不变性。论文中采用了坐标变换,利用两部分对视角的坐标变换进行估计,从而使得某一个特点的节点的z坐标为0(这一块儿的坐标变换目的不是很理解,只是感觉为了使模型的坐标得到统一)。然后对左右手坐标进行了区分(不知道是否会有影响)。所以这部分网络同时有了两个任务,一个是预测节点位置信息,一个是估计视角角度,这两个任务用了接近相同的网络框架。再将预测结果进行融合得到最后的坐标。
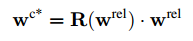
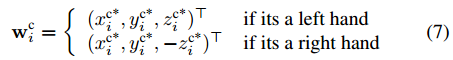
实现细节:

这部分的网络结构很简单。
Loss 函数, 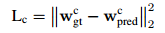 +
+
整体网络结构:
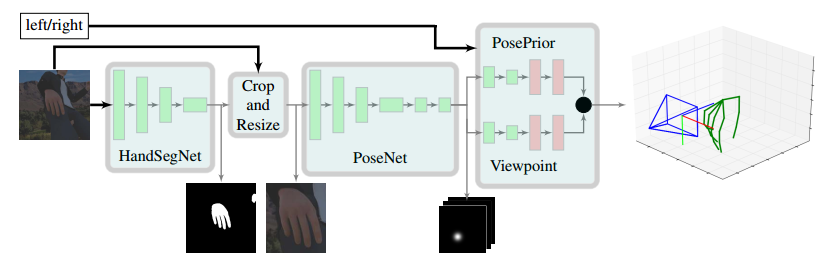
相关拓展实验
数据集:RGB with 3D pose annotation
Stereo Hand Pose Tracking Benchmark (15000+3000) , Dexter , New DataSet(41258+2728)
1. HandSegNet性能比较

第一行是不用HandSegNet,直接利用Gt提取区域,可以看出来带来的影响还是比较大的。不同数据及也会有不同的影响。
2. 学习到的先验知识的作用
这部分的实验做的很有意思,由于第三个网络是根据2D热图恢复3D节点位置信息,可以认为通过训练,网络学到了一定的先验知识,现在我们可以考虑一下这种先验

第二行代表了没有热图信息输入,此时存在着一定的先验分布,随着节点热图信息的加入,可以看出手指节点位置的预测越来越接近真实值,和贝叶斯估计有一定的相似性。
3.和既利用depth图像也利用RGB图像进行对比
只利用Depth图像进行scale的放缩和平移,利用RGB训练,并和二者都用的模型效果进行对比。实验效果如图
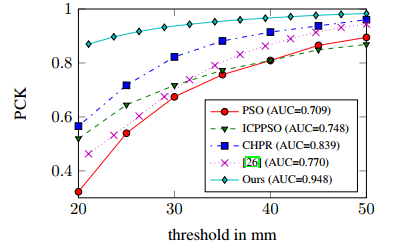
这个实验的设计感觉有些奇怪,对于其他模型而言,主要还是为了估计depth image,而RGB难免效果不好,只在RGB上进行测试并利用了depth的真实数据,很难说是真的效果好。