概述
北京的冬天刮起风来还是比较冷的,在这2019年的最后一天,我也该回顾一下这一年的时光了,这一年对我来说都是很重要的一年,既是转折也是决定,既是顺势也是波折。当然写一篇随笔来诉苦是没有质量的文章。言归正传,我们依然从技术和其他来完结这篇总结。
技术综述
2019年技术大事记,按照时间顺序。
mongodb的监控change-stream 多线程开发。
kafka运维实践。
hbase运维实践。
spark运维实践。
ESB培训与运维。
MongoDB监控开发
监控主体是mongoDB通过change-stream发送到kafka的数据,对比手段通过mongo的query语句查找op-log的数据,和消费kafka中的数据进行比对,对比过程都放在hbase中对比。逻辑关系间下图。绿色部分就是监控要做的事情。
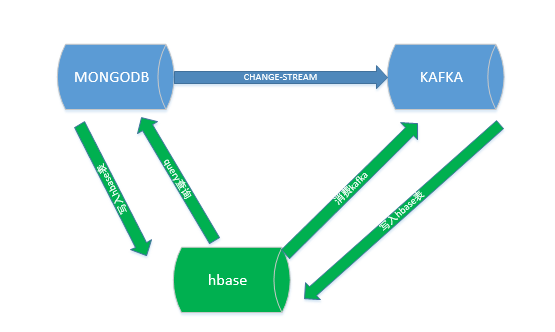
监控是多线程的划分就是根据kafka中的消息队列topic和处理逻辑区分的,比如要消费topic1的数据,就会有如下线程:消费topic1的线程,查找mongodb中topic1中表的数据的线程,处理hbase中topic1先关数据的线程,就是说三个线程监控一个topic,2个线程从mongo和kafka拉取数据,一个线程处理数据,处理数据在hbase的表中,相当于一个topic对应一个队列。现在列一下比较重要的代码。
kafka消费比较简单,使用KafkaConsumer消费者中的低阶API assign方法,其中需要注意的是记录offset到redis,如果redis存在正常offset则使用这个offset,否则从最新位置开始消费。
1 consumer = new KafkaConsumer<String, String>(props); 2 /*consumer.subscribe(Arrays.asList(topic)); 3 consumer.seekToEnd();*/ 4 TopicPartition partitions = new TopicPartition(topic, partition); 5 consumer.assign(Arrays.asList(partitions)); 6 if(RedisCheck==0){ 7 //使用assign方式进行消费 8 consumer.seekToEnd(partitions); 9 }else{ 10 consumer.seek(partitions, RedisCheck); 11 };
mongodb中使用sql语句查找指定表的数据,核心代码是,需要注意要连接secondary的节点:
1 public void init(){ 2 List<ServerAddress> addrs = new ArrayList<ServerAddress>(); 3 String mongoServer = PosterMogo.MongoServer; 4 if(mongoServer==null){ 5 mongoServer="host1:27018,host2:27018"; 6 } 7 if(mongoServer.indexOf(",")>0){ 8 String[] strs = mongoServer.split(","); 9 for(String str:strs){ 10 addrs.add(new ServerAddress(str.split(":")[0], Integer.valueOf(str.split(":")[1]))); 11 } 12 }else{ 13 addrs.add(new ServerAddress(mongoServer.split(":")[0], Integer.valueOf(mongoServer.split(":")[1]))); 14 } 15 16 Builder options = new MongoClientOptions.Builder().readPreference(ReadPreference.secondary()); 17 options.cursorFinalizerEnabled(true); 18 //options.maxConnectionLifeTime(0); 19 options.connectionsPerHost(3); 20 options.connectTimeout(6000000); 21 options.maxWaitTime(6000000); 22 options.socketTimeout(6000000); 23 options.maxConnectionIdleTime(6600000); 24 options.socketKeepAlive(true).heartbeatFrequency(1000).connectTimeout(6000000); 25 options.threadsAllowedToBlockForConnectionMultiplier(300); 26 27 options.build(); 28 String[] identified = null; 29 if(PosterMogo.MongoIdentify==null){ 30 identified="root,admin,842AB52563B13D332916113FB8DFA9BF".split(","); 31 }else{ 32 identified = PosterMogo.MongoIdentify.split(","); 33 } 34 String password = null; 35 try { 36 password = DesUtils.decrypt(identified[2]); 37 } catch (Exception e) { 38 Log4jLog.logError(e,"mongoIdentify","init","init"); 39 } 40 MongoCredential credential = MongoCredential.createScramSha1Credential(identified[0], identified[1], password.toCharArray()); 41 List<MongoCredential> credentials = new ArrayList<MongoCredential>(); 42 credentials.add(credential); 43 44 //通过连接认证获取MongoDB连接 45 mongoClient = new MongoClient(addrs,credentials); 46 //getAdminInfo(); 47 48 }
查找hbase中表的数据进行对比的代码:
1 public void aggreDataNew(String firstCount,String lastCount,String topic){ 2 3 long corDelay=Long.MIN_VALUE; 4 5 String hbaseSub=null; 6 Table table = HBaseUtil.getTable(tableNameCache); 7 8 Scan scan = new Scan(); 9 scan.setStartRow(Bytes.toBytes(firstCount)); 10 scan.setStopRow(Bytes.toBytes(lastCount)); 11 //scan.setBatch(50000); 12 scan.setCaching(1000); 13 scan.setCacheBlocks(false); 14 15 ResultScanner scanner=null; 16 try { 17 scanner = table.getScanner(scan); 18 19 for(Result rs:scanner){ 20 } 21 } catch (IOException e) { 22 e.printStackTrace(); 23 } finally{ 24 if(scanner!=null){scanner.close();} 25 if(table!=null){ 26 try { 27 table.close(); 28 } catch (IOException e) { 29 // TODO Auto-generated catch block 30 e.printStackTrace(); 31 } 32 } 33 } 34 }
在这里需要注意这3个线程需要顺序限制 所以需要加锁的代码,加锁原理,在第三个线程计算mongodb和kafka的数据的线程,需要线程等待。
kafka运维实践
这年kafka运维没有什么值得写的问题,简单来说,包括硬件内存,ISR列表不一致,GC问题等等。
HBASE运维实践
检查一致性:hbase hbck
关闭有问题的表:DISABLE TABLE
更新phoenix索引。
SPARK运维实践
spark也没有什么大问题,基本上是hdfs磁盘问题,或者yarn计算节点重启。
总结
明天就是2020年了,感觉2019过的很快,也许因为自己成长速度太慢,安于现状吧,不激励自己永远也不知道自己会成长到什么地步。共勉!