刚开始部署分布式计算的时候,常常会遇到这样的问题;如何搭配不同软件的版本呢?我们来梳理一下他们的关系。
1首先hadoop的底层开发是基于java开发的,自然是依赖于java的版本。
2另外spark的底层开发是基于scala开发的,而scala是一种范式语言,两者的共同点是都需要在JVM上运行。范式语言的好处是可以支持java,或者python。不会受到开发语言的过分限制。
3目前hadoop有两个大版本,hadoop2.x 和 hadoop3.x;关于两者的区别,可以移步了解下。对于新手自然推荐先使用hadoop2.x;当熟练之后再考虑搭建hadoop3.x提升效率。这里要特别注意的是hadoop2.x都是基于java7开发的,这是最大的前提,hadoop3.x是基于java8开发的。这也是版本之间最大的区别。虽然都是java,但是他们之间的区别还是需要注意的。
4选择好hadoop版本之后,就是选择相搭配的scala+spark;在spark官网有这样一句话,非常清楚告诉我们选择的遵循规律。
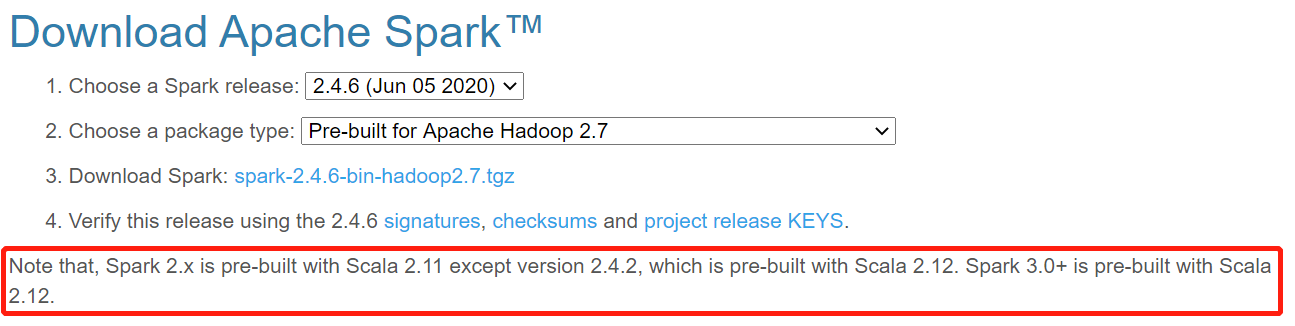 总结一下如下表所示,这里我依然推荐新手选择低版本配置,情况1最佳。这样遇到问题也好解决。
总结一下如下表所示,这里我依然推荐新手选择低版本配置,情况1最佳。这样遇到问题也好解决。
| 版本号 | scala | spark |
| 情况1 | 2.11 | 2.x(不包括2.4.2) |
| 情况2 | 2.12 | 2.4.2 |
| 情况3 | 2.12 | 3.0+ |
综上所述我们基本上就确定了版本的配置问题。
可能还会有人问具体的版本配置没有限制要求么?我们先看一下大神的版本配置:
java7--Hadoop2.6.4(2016年2月12日)--scala2.11.6(2015年2月26日)--spark2.0.0(2016年7月26日)
java8--Hadoop3.1.1(2019年)--scala2.11.x(2016年2月12日)--spark2.3.2(2016年2月12日)
由上可见,这个集群配置还是相对非常宽松的。注意好上面提出的点,可以大胆选择配置。
补充1:
当我配置hadoop2.10.0+scala2.11.6+spark2.4.6的时候,打开spark会出现如下错误。可见我们安装的spark版本过高,导致JVM无法适配。应该将spark改装低版本的才行。
