使用google翻译自:https://software.seek.intel.com/dealing-with-outliers
数据分析中的一项具有挑战性但非常重要的任务是处理异常值。我们通常将异常值定义为与其余数据群1不一致的样本或事件。异常值通常包含有关影响数据生成过程2的系统和实体的异常特征的有用信息。
异常检测算法的常见应用包括:
入侵检测系统
信用卡诈骗
有趣的传感器事件
医学诊断
在本文中,我们将重点介绍异常检测 - 信用卡欺诈的最常见应用之一。通过一些简单的离群值检测方法,可以在真实世界的数据集中找到75%到85%的欺诈性交易 - 误报率低于1%的时间。
定义方法
检测异常值有两种基本方法:
监督,我们使用欺诈性和非欺诈性的例子来预测新观察的类别
无监督,我们没有标记示例,并检测欺诈性示例为异常值或异常
进一步细分,有三种基本的监督方法:
神经网络
SVM
逻辑回归
无监督的方法包括:
基于统计的技术,如BACON *离群检测
多变量异常值检测
基于聚类的技术类似于k均值,期望最大化(EM)和DBSCAN ,这是一种检测数据中可被视为异常值的噪声的算法。
我们将比较这些技术并根据某些设计标准评估每种方法。准确度指标包括检测率和误报率7。
重要的是要记住欺诈检测不仅仅是捕获欺诈事件。它还需要尽快捕获这些活动 - 因此算法的性能是一个重要的指标8。在我们的测试中,我们将使用一些流行的机器学习库,包括英特尔®数据分析加速库(英特尔®DAAL),它们实现异常值检测算法,以比较精度和性能的结果。
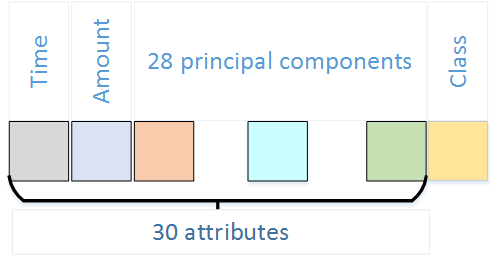
图1.数据集属性
数据集描述
我们使用了来自Kaggle *的数据集9,这是一个预测建模和分析竞赛的平台,公司和研究人员发布他们的数据,来自世界各地的统计人员和数据挖掘者竞争生产最佳模型10。我们从Kaggle11中选择了最受欢迎的关于信用卡欺诈检测的真实数据集。它包含31个数字输入变量(图1)。
time属性表示每个事务与数据集中第一个事务之间经过的秒数。金额代表交易金额,顾名思义。其余28个特征是PCA获得的主要组件。由于机密性问题,未提供原始功能。
Class是响应变量。它在欺诈的情况下等于1,否则为0。数据集高度不平衡,因为欺诈交易远不如普通交易。欺诈仅占所有交易的0.172%(284,807笔交易中有492起欺诈)。
让我们看一些主要组件的条件分布(图2和图3)。主成分不是相关的,因此删除具有类似条件分布的欺诈和正常示例可以帮助我们构建更准确的模型。我们将使用点 - 双线相关系数来测量每个主成分和目标变量之间的关系(表1)。稍后我们将使用此信息进行特征工程。
信用卡欺诈检测方法
现在,我们将对数据应用不同的离群检测技术,评估其准确性和性能,并进行比较。对于信用卡欺诈检测,我们将使用有监督和无监督的方法。
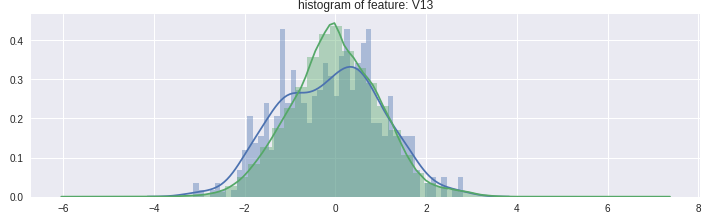
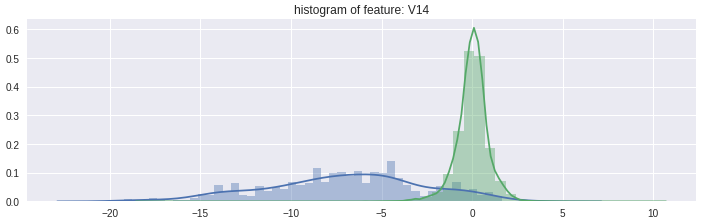
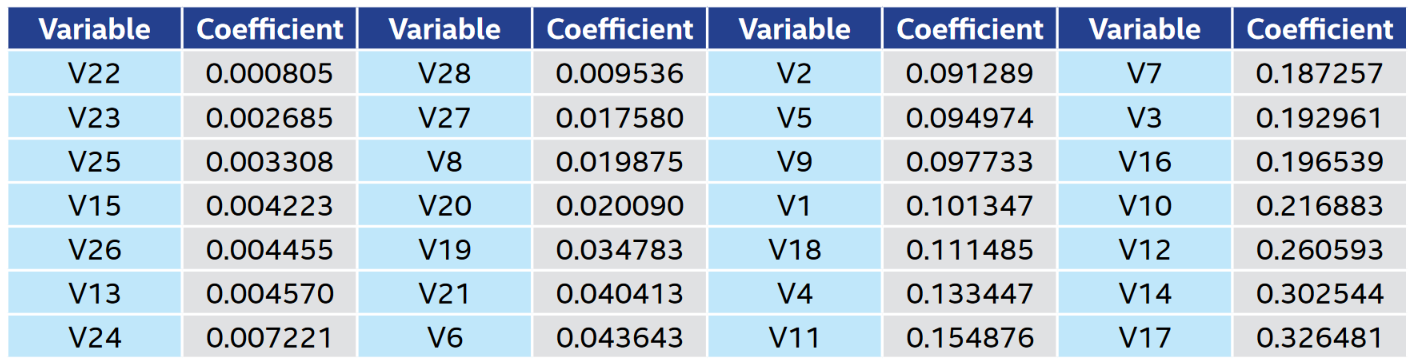
图2.两种类型的事务之间具有类似分布的属性
图3.两种类型的事务之间具有不同分布的属性
表1.主成分的点 - 双相关系数
无监督的方法
统计方法是用于离群检测的最早算法。我们将从异常检测特定算法开始 - 多变量离群检测和BACON *离群检测。这些方法的一个很大的优点是它们的计算效率非常高,因此很容易将它们应用于大型数据集14。我们用六个主要成分获得了最佳结果,其中高点 - 双相关系数(V11,V12,V14,V16,V17,V18)为特征。我们使用了英特尔DAAL和R *包robustX *的实现。与BACON异常值检测相比,多变量离群值检测可获得更好的准确度结果(表2)。

表2.基于统计的离群值检测方法
聚类和异常检测具有互补关系。在聚类中,目标是将点划分为密集子集。在异常值检测中,目标是识别似乎不适合这些密集子集的点2。一些聚类算法,如DBSCAN *,提供子产品,可被视为异常值。
有许多基于聚类的异常检测方法2,3,4,15。我们将在测试中应用其中一些。集群是信用卡欺诈中固有的,因为犯罪者通常会产生一组欺诈性交易16。
有两种类型的异常值,局部和全局。不同的基于聚类的算法可以检测这两种类型。全局异常值的属性值与大多数数据点所采用的值相比是偏离的。当局部异常值的属性值与其邻居的属性值相比是极端的17。
为了检测全局异常值,我们可以对数据集执行聚类,并将一些聚类定义为异常值18(表3)。我们将使用k-means和EM执行聚类,将小聚类视为异常值19。 k和n_components的值是通过从范围[2,3,...,50]的网格搜索获得的。我们使用相同的初始质心用于英特尔DAAL和Scikit-learn *的k-means,使用英特尔DAAL中的实现通过k-means ++初始化获得它们。我们使用具有高点 - 双相关系数作为特征的17个主成分获得了最佳结果。通过这些方法,我们实现了相对较低的误报率。

表3.用于全局异常检测的基于聚类的方法
我们还将应用可以检测局部异常值的聚类技术20。一种天真的方法是使用k-means算法21对事务进行聚类,并将远离聚类中心的点视为异常值(表4)。
我们获得了很好的检测率。但是,误报的数量很多。原因是k-means算法对异常值极为敏感,这对集群配置有很大影响。因此,应声明为异常值的数据点将被群集屏蔽。因此,我们需要使用一个强大的k-means版本,它可以优雅地处理异常值-k,l-means15(表5)的存在。像k-means一样,这种算法需要初始质心。我们将使用英特尔DAAL-random,k-means ++ 22和k-means || 23中提供的不同初始化算法来计算它们,并比较结果。


表4.用于局部异常值检测的基于K均值的方法

表5. K,l-means算法结果
我们可以看到这种方法提供了比天真的k-means更好的准确性。不同初始化的结果不同。随机方法被证明是最好的解决这个问题。
我们还将使用基于密度的聚类算法来检测数据中的噪声(表6)。如果点与其邻居显着不同,则将其检测为噪声。一个自然的假设是将噪声数据视为局部异常值。我们使用与统计方法相同的六个特征。通过网格搜索获得参数值。我们使用R包dbscan *。我们通过适度的错误警报达到了良好的检测欺诈水平。但是,与以前的方法相比,性能明显更差。

表6.用于异常值检测的Dbscan
监督方法
监督学习方法需要包含每个类的示例的训练数据 - 在我们的情况下,正常和欺诈性交易2。我们将数据集划分为训练和评估集,其中80%的数据用于培训,20%用于模型评估。
我们从Kaggle kernel24中提出的神经网络(表7)开始。内核作者使用了一个带有三个隐藏层的简单多层感知器。多层感知器(MLP)是广泛使用的神经网络,用于分类和离群检测25。

表7.神经网络
用于离群值检测的另一种监督学习算法是逻辑回归16(表8和9)。我们将使用17个具有最高点 - 双线相关系数(表1)和数量特征的属性,这些特征是使用Z分数归一化预处理的。从直方图24中,我们可以看到,由于使用了逻辑回归,欺诈和正常观察是线性可分的。我们的数据集是不平衡的,因此使用随机欠采样可以帮助构建更准确地检测欺诈的模型。这省略了培训中的许多非欺诈性示例,因此我们将使用投票分类器26,每个估算器都在随机抽样不足的训练数据集上进行训练。 (正则化参数C在经过多种值的实验后被设置为1)。通过这种技术,我们将检测率提高了3%,几乎相同的误报率。


表8.逻辑回归
表9.逻辑回归模型的集合
让我们看看支持向量机(SVM),另一种监督学习算法,它也可用于异常值检测16,对同一数据起作用。我们运行SVM 100,000次迭代,线性内核,C = 1。 (这些参数是通过网格搜索获得的。)使用与逻辑回归相同的特征。使用SVM集合可显着提高检测率,同时提供较低的误报率(表10)。
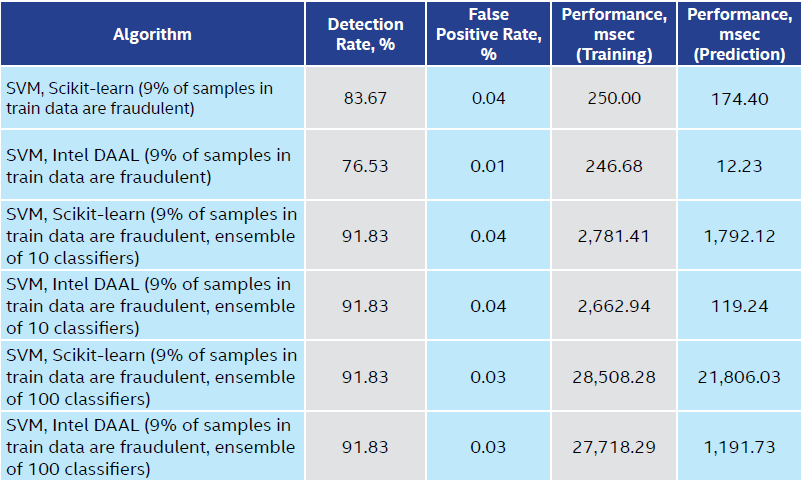
Table 10. SVM
评估不同的异常检测方法
存在各种用于欺诈检测的无监督方法。我们在本文中应用了其中的一些。异常检测特定算法,k,l-means和DBSCAN,实现了最佳检测率,达到了85%的检测到的欺诈,而使用k-means检测欺诈性交易的集群可以提供最少的错误警报。检测到欺诈性交易越早,通过停止使用欺诈性信用卡进行的交易就可以避免更多的损失16-使算法的性能成为另一个关键指标。欺诈检测方法的最终选择将取决于许多因素,包括检测到的欺诈行为的成本以及与停止欺诈行为相关的成本7。在没有观察类别的先验知识的情况下,无监督方法可能是有用的。
当我们事先了解观察类别时,我们可以使用有监督的学习算法。我们使用不平衡分类技术(如欠采样)来帮助增加检测到的欺诈数量。 SVM分类器的集合提供最高的检测率,而随机森林具有最低的误报率。尽管像SVM这样的监督方法与无监督方法相比给了我们更高的准确性,但使用它们会带来问题:
准确标记的训练数据可能非常昂贵,而且数据科学家必须对用于构建模型的训练数据的真实类别充满信心。
根据样本数量和每个样本的特征数量,训练模型的时间可能很长。
与无监督方法不同,监督学习无法在没有再培训的情况下检测到新类型的欺诈16,27。
正如我们所示,为给定的应用程序选择正确的机器学习算法是一个非常重要的问题,需要经过深思熟虑。
References
- Victoria Hodge, “Outlier and Anomaly Detection: A Survey of Outlier and Anomaly Detection Methods.”
- Charu C. Aggarwal, “Outlier Analysis,” Second Edition.
- Vaishali, “Fraud Detection in Credit Card by Clustering Approach.”
- Yogesh Bharat Sonawane, Akshay Suresh Gadgil, Aniket Eknath More, Niranjan Kamalakar Jathar, “Credit Card Fraud Detection Using Clustering Based Approach.”
- Ester, M., H. P. Kriegel, J. Sander, and X. Xu, “A Density-Based Algorithm for Discovering Clusters in Large Spatial Databases with Noise” in Proceedings of the 2nd International Conference on Knowledge Discovery and Data Mining, Portland, OR, AAAI Press, pp. 226-231. 1996.
- Samson Kiware, B.A, “Detection of Outliers in Time Series Data.”
- Elham Hormozi , Hadi Hormozi, Mohammad Kazem Akbari, Morteza Sargolzaei Javan, “Accuracy Evaluation of a Credit Card Fraud Detection System on Hadoop MapReduce.”
- Shraddha Ramesh Bhagwat, Vaishali Londhe, “A Review of Various Credit Card Detection Techniques.”
- Credit card fraud detection dataset.
- Overview of Kaggle on Wikipedia.
- Credit card fraud datasets on Kaggle.
- Point-biserial correlation coefficient on Wikipedia.
- Victoria J. Hodge and Jim Austin, “A Survey of Outlier Detection Methodologies.”
- Nedret Billor, Ali S. Hadi, Paul F. Velleman, “BACON: Blocked Adaptive Computationally Efficient Outlier Nominators.”
- Sanjay Chawla, Aristides Gionis, “k-means: A unified Approach to Clustering and Outlier Detection.”
- Sanjeev Jha, Montserrat Guillen, and J. Christopher Westland, “Employing Transaction Aggregation Strategy to Detect Credit Card Fraud.”
- Marie Ernst and Gentiane Haesbroeck, “Detection of Local and Global Outliers in Spatial Data.”
- Bin-mei Liang, “A Hierarchical Clustering Based Global Outlier Detection Method.”
- Yuan Wang, Xiaochun Wang, Xia Li Wang, “A Spectral Clustering Based Outlier Detection Technique.”
- Zengyou He, Xiaofei Xu, Shengchun Deng, “Discovering Cluster-Based Local Outliers.”
- Stuart P Lloyd, “Least Squares Quantization in PCM,” IEEE Transactions on Information Theory 1982, 28 (2): 1982pp: 129–137.
- Arthur, D. and Vassilvitskii, S, “k-means++: The Advantages of Careful Seeding,” Proceedings of the Eighteenth Annual ACM-SIAM Symposium on Discrete Algorithms, Society for Industrial and Applied Mathematics Philadelphia, PA, USA, 2007, pp. 1027-1035.
- B. Bahmani, B. Moseley, A. Vattani, R. Kumar, and S. Vassilvitskii, “Scalable K-means++,” Proceedings of the VLDB Endowment, 2012.
- Kaggle kernel, use of neural network for fraud detection.
- Varun Chandola, Arindam Banner Jee, and Vipin Kumar, “Outlier Detection : A Survey.”
- Gareth James, “Majority Vote Classifiers: Theory and Applications.”
- Bolton, R.J. and Hand, D.J., “Unsupervised Profiling Methods for Fraud Detection” in Conference on Credit Scoring and cCedit Control, Edinburgh, 2001.
Configuration Information
Hardware:
- Processor: Intel® Xeon® Platinum 8168 processor @ 2.70GHz
- Core(s) per socket: 24
- Socket(s): 2
- Memory: 63 GB
Software
- Intel® Data Analytics Acceleration Library 2018 Gold
- R version 3.4.1
- Scikit-learn version 0.19.1
- robustX package 1.2-2
- dbscan package 1.1-1