Alluxio : 开源分布式内存文件系统
Alluxio is a memory speed virtual distributed storage system.Alluxio是一个开源的基于内存的分布式存储系统,现在成为开源社区中成长最快的大数据开源项目之一。
公司简介:
-
由项目的创建者李浩源以及来自UC Berkeley, Google, CMU, Palantir, Stanford, Yahoo等不同公司和学校的项目核心开发者组成。
-
完成750万 dollars 的A轮融资,由Andreessen Horowitz投资(硅谷最著名的VC之一,主要成员为网景公司创始人之一)。
背景介绍:
-
2012年诞生于UC Berkeley AMPLab,此前这个实验室孵化了Apache Mesos和Apache Spark等著名开源项目。
-
2013年4月开源,现在由最初的Tachyon改名为Alluxio,基于Apache License 2.0开源标准,最新版本为Version 1.0 (Feb 23rd, 2016)。

-
在分布式系统的开源项目中,相比于同级别项目,Alluxio的增长非常迅速
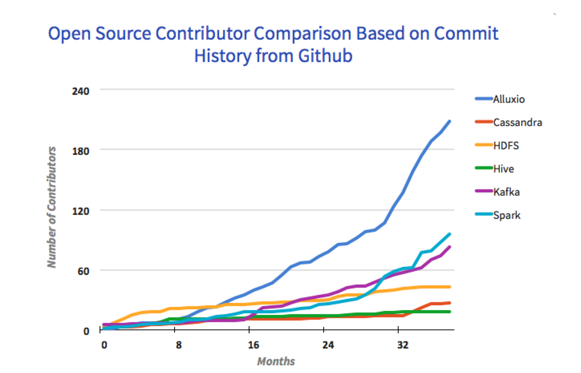
-
吸引了来自超过50个组织的200+个contributors。

主要特性:
-
数据存储与计算分离,两部分引擎可以进行独立的扩展。计算引擎(如Hadoop, Spark)可以访问不同数据源(Amazon S3, HDFS)中的数据。
问题:与Redis,Memcached等分布式in-memory key-value缓存的的区别:
-
答:(1) Alluxio可以同时管理多个底层文件系统,将不同的文件系统统一在同一个名称空间下,让上层客户端可以自由访问统一名称空间内的不同路径,不同存储系统的数据。(2)Alluxio提供文件接口,并存储且维护文件的metadata(比如记录文件分成哪几个block, 每一个block在哪台server上)。并提供fault tolerance的metadata服务。而Redis/Memcached为Nosql的key-value分布式缓存,并不提供文件接口。
内存与硬盘比较
硬盘内存增长率曲线:
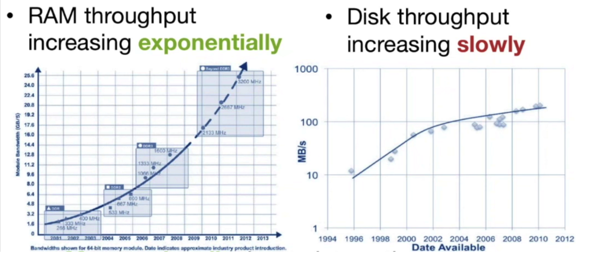
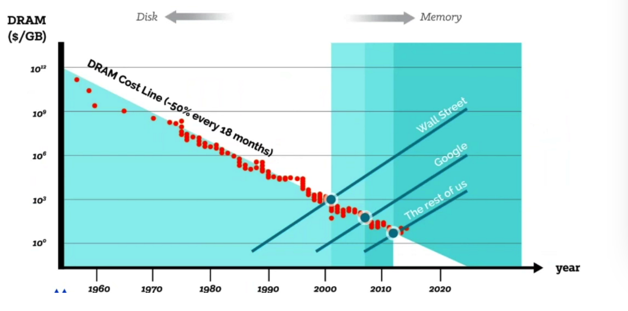
因此,充分利用内存,成为趋势,而Memory locality成为影响相应时间最重要的因素之一。硬盘内存价格曲线:
Alluxio with Spark
-
Spark是一种基于内存的运算框架。
-
在JVM的内存中存储一份,以保证较少的网络通信和读写。
-
记录存储数据的世代(lineage),当数据丢失时,基于世代将job重新运行,得到相应数据。
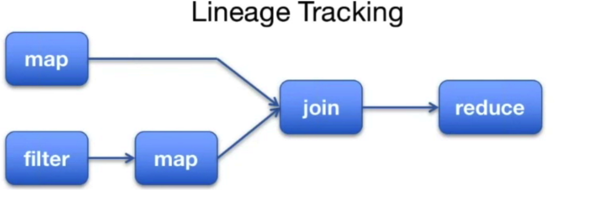
Issue 1:数据分享(Data Sharing)在analytics pipeline中成为瓶颈。
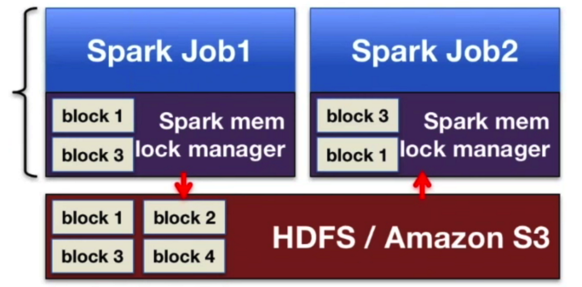
在Spark中,如果job2需要Job1运算的数据,Job1首先需要将数据写入到HDFS的block中,会产生硬盘甚至跨网络的读写,同时在HDFS中默认数据需要写三份,因此造成性能的损失。
Issue 1 的解决方案:内存数据在不同的job和framework中进行分享。
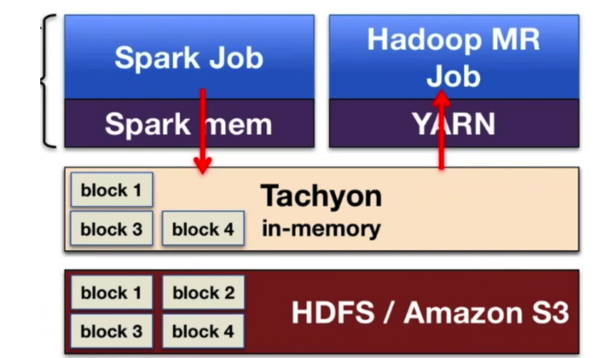
Alluxio在HDFS/ Amazon S3和计算引擎中间提供了中间层,Spark的Job1不需要写到HDFS中,而只需要写到Alluxio的内存中,Job2可以从内存中读取相应数据。
Issue 2: 当计算引擎的进程损坏,Cache 丢失,Spark只能重新启动并计算恢复数据。
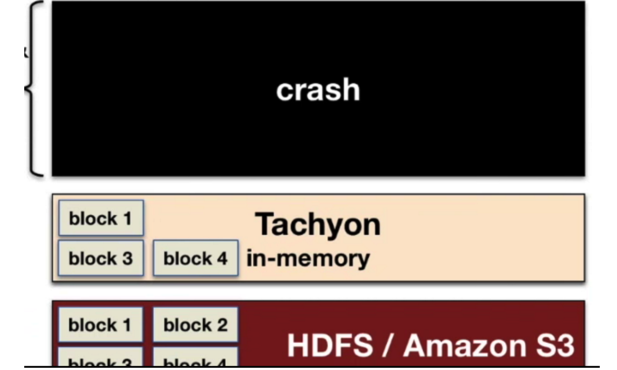
Issue 2 解决方案:
当计算引擎损坏,由于中间由Alluxio存储数据,可以保证内存中的数据安全。
问题1:因为在传统计算引擎中,数据存储在同一个JVM中,而基于Alluxio的中间件将数据存到了不同的JVM中,跨JVM读写会不会影响性能?
答:跨JVM读写会影响性能,在Alluxio中,使用了RamDisk来模拟本地文件系统的方式。
问题2:如果Alluxio crash,怎么保证数据安全?
答:在Alluxio中,数据不是保存在JVM中,而是保存在RamDisk中,RamDisk为独立的进程,因此可以保证数据安全。
问题3:Alluxio是否可以支持随机读写?
答:可以进行随机读,给定一个offset。新创立的文件一旦关闭,就会变成immutable
Issue 3: 内存数据的重复和Java的垃圾回收。Issue 3 解决方案:
由于计算引擎与存储引擎共享同一个进程,而不是放在自己的JVM中,可以减少垃圾回收和数据重复。
Alluxio 架构: Memory-centric storage architecture
核心思想:将世代(lineage)由计算引擎放到了数据层处理。
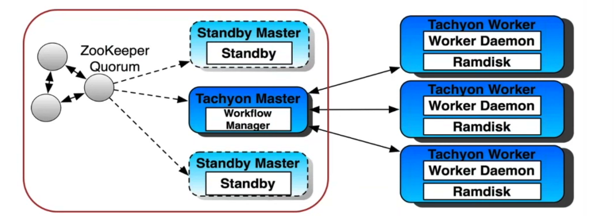
1,存储架构:
master节点负责管理worker节点,数据存储在worker节点中。
对于每一个worker,worker daemon为一个JVM,负责管理Ramdisk,数据存储在Ramdisk中。
如果有高可用性的需求,可以设置standby master和zookeeper来容错,这里会有性能损耗。
2,世代(Lineage) 保证数据的Reliability
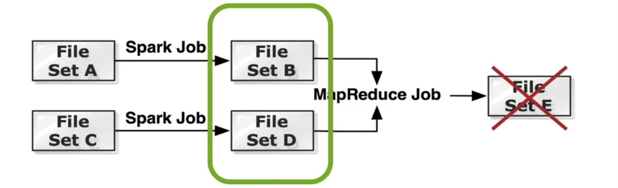
1,当数据E丢失后,通过世代找到相应的之前数据,重新部署一个Job将数据重新计算。
2,将数据在底层文件系统中备份。
问题:HDFS中每个数据块会默认有多个备份, 从而在极端情况下会有更大的读取带宽。 在Alluxio中,由于数据存储在同一份内存中,如何处理多个Job同时读取同一份数据的情况。
答: Alluxio的数据在内存当中,本身可以提供更大的本地读取带宽。另外Alluxio也允许让用户绕过Alluxio直接从底层的持久化文件系统读取数据。
3,分层存储(Tiered Storage):
当数据大小超过内存容量,如何处理?
Alluxio不仅仅管理内存,同样可以管理SSD,HDD等系统资源。保证Alluxio可以正常运行。
One Large Scale deployment:
某公司实现了1000 workder 的Alluxio部署,每个机器几G-几十个G的内存 。
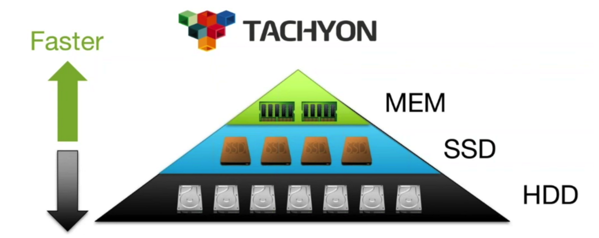
4,可插拔的数据管理(Pluggable Data Management)
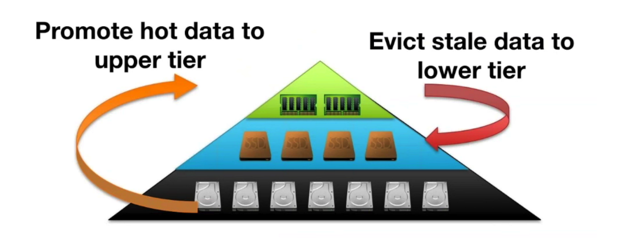
基于每一个worker,暂时没有跨worker。对于计算机系统来说,长期以来人们在不同的场景下反复使用两个经典但行之有效的方案:
1,cache。
2,增加一个中间层(比如增加一层指针,如virtual memory)
Q: Alluxio 有没有全局的分层存储的allocation/eviction管理?
A: 目前Alluxio的cache策略是基于每一个worker单独的决策,暂时没有实现跨worker的分层存储的协作。
5,Pin Data

对于重要的数据,可以通过Pin来显示的把数据“挂”在内存层
问题:对于Pin的data,怎么保证底层数据修改之后上层数据的更新。
答:给用户提供命令去主动更新数据。
6,透明命名(Transparent Naming)
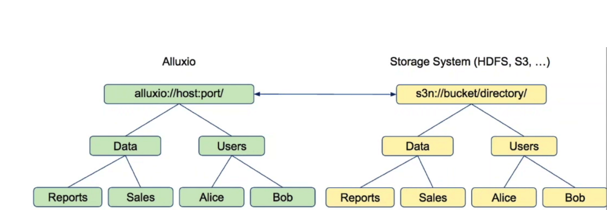
Alluxio可以提供将创建,重命名和删除文件等操作从Alluxio映射到底层存储层(比如上图中的HDFS 或者S3)的对象中,从而实现将底层存储系统中的文件与其Alluxio自身管理的文件系统的完全同步。
7,统一命名空间(Unified Namespace)
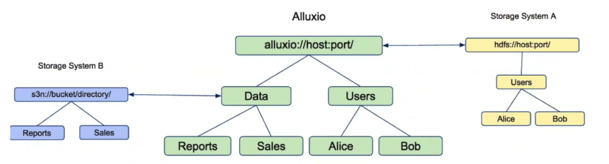
Alluxio可以挂载多个不同的文件系统到一个统一的命名空间当中,如不同的文件系统A和文件系统B可以同时挂载到Alluxio上面的不同目录当中。
在不同的数据文件系统中可以共享数据。
此操作可以on the fly,被管理员进行操作。
Alluxio Case Study:
百度:
性能提升:30x
框架: SparkSQL
存储系统: Baidu’s File System
存储媒介: MEM+HDD
节点数量: 100+
空间管理大小:1PB+
Q: 为什么可以提供30x的性能提升?
A: 百度的一项业务采用计算和存储分离的架构:比如计算集群在一个城市,而数据存储集群在另一个城市。数据存储集群计算资源较少,而计算集群没有足够存储资源。百度将Alluxio部署到了计算集群中。从而将数据存储在了Alluxio中,从而使计算集群可以在本地完成读写。
去哪儿网:
框架:Spark Streaming
存储系统:HDFSS
存储媒介:MEM+HDD
节点数量:200+
Barclays:
框架:SparkSQL
存储系统:None
存储媒介: Memory
某石油公司:
框架: Spark
存储数据:ClusterFS
存储媒介:MEM only
性能提升:在传统文件系统中使用Spark进行数据处理。
某SAAS公司:
框架:Impala
存储系统: S3
存储媒介: MEM+SSD
性能提升:15x
Alluxio新特性:
- Alluxio Key-value (Alpha)
- Native Swift Integration(Openstack下面的文件系统)
- Alibaba Object Storage Service Integration
- Users/Groups in File System
- ACL Permission
- Read/Write Location Preference Policy
- Improved Yarn and Mesos Integration
注:本文系2016年2月29日太阁三人行“一起聊聊Alluxio”的总结分享,感谢Menglei Sun的整理,Dr Bin Fan的校注