1. Adversarial Logit Pairing
本文[1]主要研究的问题是以前面有提到过的对抗训练的防御方法为基础,探讨该方法能否在大规模数据集上实现好的防御效果。之所以要研究这个问题,一方面,是因为在提出对抗训练的时候,并没有扩展到大规模数据集上。另一方面,之前几乎所有在ImageNet上尝试过的防御措施都会被特定的白盒攻击设置所打破。所以就考虑将对抗训练应用到大规模数据集上,并且引入对抗逻辑配对的策略以增强防御。
首先先来说一下对抗训练。本文主要以[2]提出的对抗训练策略为基础来展开,并沿用该文在小规模数据集上采用的攻击方式来进行测试。之所以采用他们的方法,是因为在最新的针对几种白盒设置防御措施的测试中,该方法是唯一经受住考验的。他们将使用的攻击方法称为"投影梯度下降"(projected gradient descent, PGD),主要就是先在允许的范围内随机初始化搜索对抗样本,然后进行迭代生成攻击的对抗样本,然后利用产生的对抗样本进行对抗训练,因为嘈杂的初始点带来了更强的攻击,从而也使得防御更加成功。这大概就是对抗训练的思路。
接下来来看一下数学模型。PGD是一种典型的一阶攻击(直接利用梯度进行攻击),针对PGD进行防御,也意味着很可能能抵抗其他的一阶攻击。所以本文中采用PGD的对抗训练作为方法的基础。其数学描述如下式
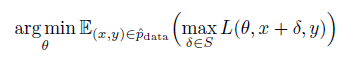
其中 表示基础训练集的数据分布,
表示原始任务的损失函数,
表示原始样本,
表示真实的类别,
表示模型参数,
表示引入的对抗扰动。
要注意的是,上式中只对对抗样本进行了对抗训练,作者对此进行了改进,将干净的样本也加入了对抗训练,实现了更好的性能。优化
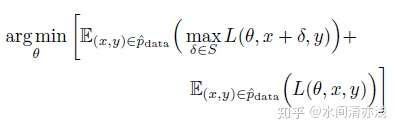
这个改进的好处是有助于模型在干净样本上保持良好的准确性。作者将这种方法称为混合小批量PGD(mixed-minibatch,M-PGD)。
前面也讲过,对抗训练的思想比较简单粗暴,但由于数据集的规模会影响训练结果,所以作者进一步提出了logit配对(logit pairing)的策略来增强防御,这是一种鼓励来自两个图像的logits彼此相似的方法。对于输入 ,计算逻辑向量
,然后在上面的模型基础上增加logit配对的损失项
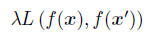
其中 为原始样本,
为对抗样本,
为logits配对强度的惩罚系数,
是
范数形式的损失函数,
。
另外,作者在除了将logit配对用到了对抗样本上,还探索了这种方法对干净样本分类有没有什么影响。所以,一共考虑了两种配对方式。一种是干净样本和对抗样本配对,另一种干净样本和另一个干净样本配对。
首先来看对抗logit配对(adversarial logit pairing,ALP)。假设一个小批量的样本集为 ,对应的对抗样本为
。
为输入到模型logits的函数映射。
表示对抗训练的目标函数。那么整体的损失函数为
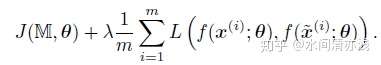
再来看干净logit配对(clean logit pairing,CLP)。这里配对的样本为两个随机选择的干净样本,可以不是来自同一类。其他的参数都与上面一样,然后假设 是干净样本分类训练时的目标函数。那么整体的损失函数为
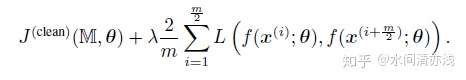
定义好模型以后,作者设置了实验来了解logit配对对干净样本和对抗样本对进行分类的贡献。
家下来我们来看实验。首先还是在小规模数据集上测试,分别在MNIST和SVHN数据集上进行实验。在MNIST数据集上的表现如下表所示。
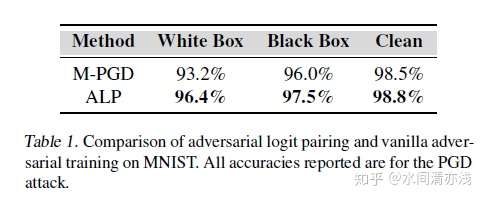
结果表明,本文中的方法比单独的对抗训练方法要好,不管是针对白盒攻击,黑盒攻击,还是原始任务,准确率都有所改善。
再来看SVHN数据集的结果,如下表所示。
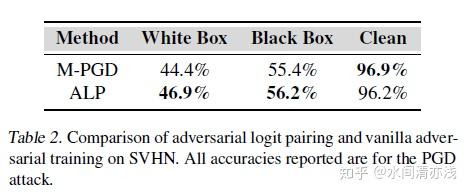
与MNIST的结果类似,白盒黑盒设置的准确性有所改善。
另外这里两个实验中作者还对logit配对损失项的系数 进行了试验,来观测该参数对实验结果的影响。发现logit配对权重的确切值对于MNIST数据集来说并不重要,只要它大致在0.2和1之间,就能对性能有所改善。对SVHN来说,只要添加了一些logit配对,它就提高了准确性。而且,使logit配对值太大(例如任何大于2的值)并没有带来任何好处。
在小规模数据集上实验完了以后,我们来看本文的核心工作,在大规模数据集ImageNet上的实验。在本文工作之前,针对PGD的对抗训练尚未扩展到ImageNet。
另外,有人指出,在ImageNet上,目标攻击的准确性比使用非目标攻击的准确性更有意义。这是因为非目标攻击可能导致非常相似的类别(例如两个非常相似的犬类的图像)的错误分类,这是没有意义的。因此,本文中采用目标攻击来评估防御性能,对抗训练所使用的对抗样本也是使用目标攻击产生的。实验结果如下
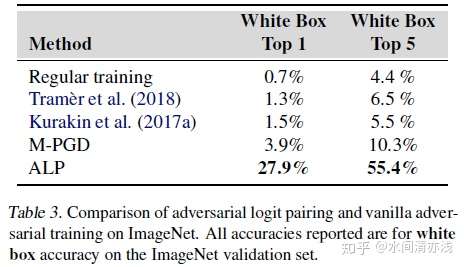
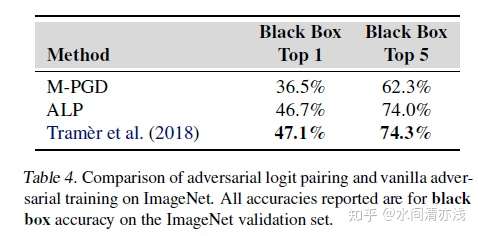
上表中的准确率都是指在所考虑的两种威胁模型(白盒和黑盒)中所尝试的所有攻击中防御表现最差的准确率。结果表明前面讲到过的集成对抗训练(Tram`er et al.)的方法在这里几乎无效,准确率甚至低到1.3%。而本文中的对抗logit配对的方法表现出较好的性能,白盒攻击,将目前最高的3.9%提升到了27.9%,对抗logit配对还提高了M-PGD基线的黑盒准确率,从36.5%提高到了47.1%。
这里我们来对该方法的原理简单的分析一下,首先假设对抗logit配对运作良好,因为它提供了一个额外的正则项,使模型正则化以更准确地理解类。如果我们仅使用交叉熵损失函数训练模型,则很容易学习适合训练集分布的伪函数,但是在训练流形之外具有不确定的行为。对抗训练增加了有关空间结构的额外信息。而添加小扰动不应改变类的假设,无论扰动方向如何,对抗训练通过引入另一个正则项,迫使模型选择在更大的样本空间上更适合的函数。但是,对抗性训练不包括有关干净样本与同一样本的对抗样本之间关系的任何信息。而对抗logit配对迫使干净样本和对抗样本在映射后相似。
以上的实验的目的是测试对抗logit配对在防御对抗样本攻击时的防御效果。在本文中,作者还对干净样本之间的logit配对可能会产生的影响进行了考虑。实验中,首先使用高斯噪声增强图像,然后应用干净样本的logit配对。在SVHN数据集上的结果如下所示。
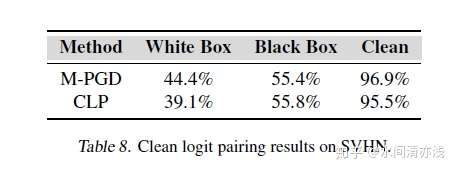
实验表明,采用CLP来进行防御的准确率和对抗训练具有可比性,在这种前提下,CLP的计算成本大大降低。这样的结果给我们带来的启发是,既然只需要较少的资源,可以达到差不多的效果,那么是否可以用它来代替对抗训练呢,在实际中,是更希望采用计算成本较低的防御措施的。如果可以在性能不损失的情况下实现成本较低的安全性,机器学习安全性的未来将更加光明。
最后总结一下,本文以前所未有的规模实施对抗性训练,并引入logit配对增强防御,实验结果表明,对目前的防御方法的性能有所改善,并在大规模数据集取得的较好的效果。
本文主要的贡献包括:1)回答了关于对抗性训练是否适用于ImageNet的开放性问题;2)引入了对抗logit配对(ALP),这是对抗训练的延伸,可大大提高其有效性;3)引入了干净的logit配对,这有可能是对抗训练的低成本替代方案,可以增加强大机器学习的应用;4)实验结果表明,特征配对(匹配对抗和干净样本的中间特征而不是对数)也可能在将来会证明是有用的。