SQLFlow深度解析
SQLFLow介绍
SQLFlow是阿里巴巴蚂蚁金服开源的一个AI On SQL的项目, 目标是SQL 引擎和 AI 引擎连接起来,让用户仅需几行 SQL 代码就能描述整个应用或者产品背后的数据流和 AI 构造
SQLFlow 最早的初衷,就是希望解决分析师既要操作数据又要使用 AI、往往需要在两个甚至更多的系统之间切换、工作效率低的窘境。
目前业界已有的AI ON SQL的方案:
- Microsoft SQL Server:Microsoft SQL Server 支持机器学习服务,可以将 R 或 Python 编写的机器学习程序作为外部脚本运行.缺点: 需要编写R或者Python程序代码
- Teradata SQL for DL:Teradata 也提供了 RESTful 服务,可以通过扩展的 SQL SELECT 语法调用. 缺点: 语法耦合了它的Rest服务
- Google BigQuery:Google BigQuery 通过引入 CREATE MODEL 语句让用 SQL 实现机器学习成为可能. 缺点: 支持的模型有点少, 深度学习还不支持.
针对以上三个方案的缺点, SQLFlow的定义了自己的三个设计目标:
- 这一解决方案应与许多 SQL 引擎都兼容,而不是只能兼容特定版本或类型的 SQL 引擎。
- 它应该支持复杂的机器学习模型,包括用于深度学习的 TensorFlow 和用于树模型的 XGBoost。
- 能够灵活地配置和运行前沿机器学习算法,包括指定特征交叉,无需在 SQL 语句中嵌入 Python 或 R 代码,以及完全集成超参数估计等。
目前阶段来说, SQLFlow已经支持MySQL/MaxCompute/Hive, 机器学习框架已经支持TF和XGBoost.
资源:
Spark社区既有MLib这样的机器学习框架, 也有一些基于深度学习的扩展, 例如Uber的horovod还有Yahoo的TensorFlowOnSpark, 但是这些框架都是基于的是Spark DataSet的接口联通的, 你可以在DataSet API上使用SQL, 也可以使用AI接口, 你可以认为是
AI + SQL的模式, 而不是AI ON SQL的模式
SQLFlow试用
社区提供了一个官方的试用的Docker镜像, 只要键入以下命令启动容器即可:
1
|
docker run -d -p 8888:8888 sqlflow/sqlflow:latest
|
试用浏览器打开容器机器所在的8888端口, 可以看到一个notebook的页面, 默认已经有一个example.ipynb的样例文件了

打开这个example.ipynb文件, 这个镜像里面已经安装了mysql, 同时也把部分测试数据导入到数据库里面, 你不需要做任何数据处理的工作, 就可以直接运行Notebook里面的Cell. 蚂蚁的开发人员真的很贴心啊
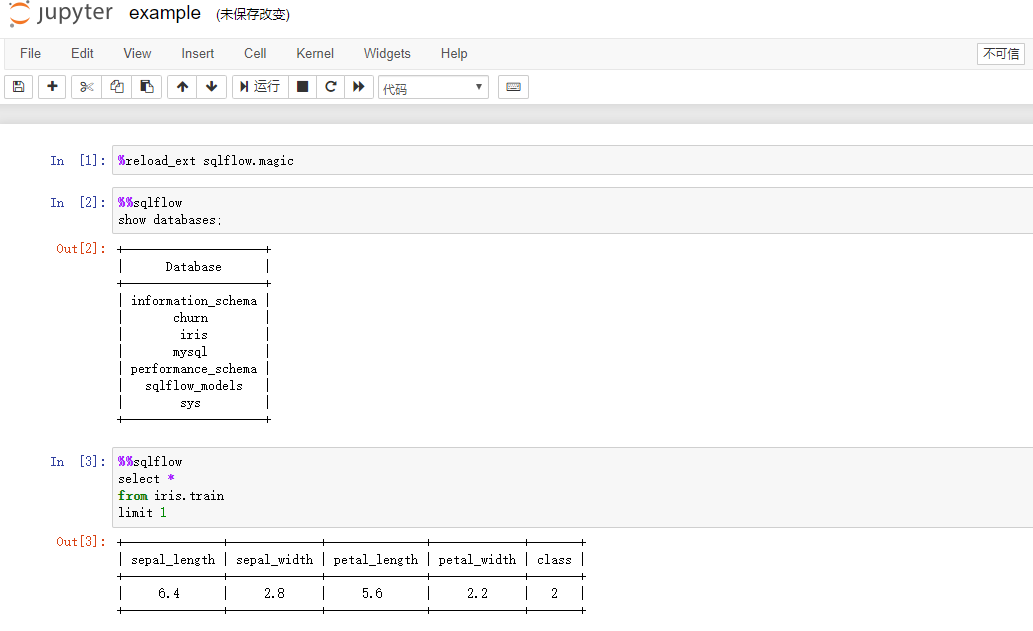
执行推理过程, 使用DNNClassifier算法模型, 并将结果写入到sqlflow_models.my_dnn_model表中, my_dnn_model只有两个字段: ID和BLOB(存放模型序列化后的字节流)
执行对于测试集(iris.test)进行推理, 并写入到预测结果表之中(iris.predict.class)
最后展示推理结果集iris.predict
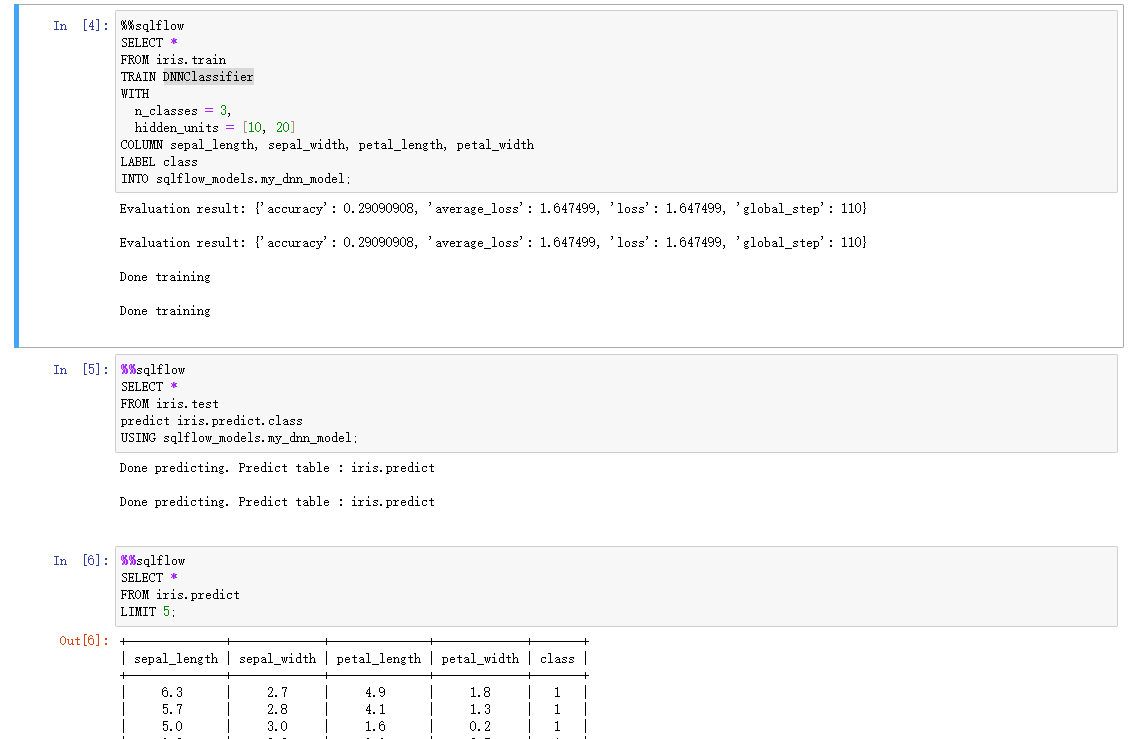
架构解析
这个AI ON SQL系统里面, 首先要回到的一个问题是, AI系统的计算层和SQL系统的计算层是什么关系?
例如Spark(BigQuery大概率也是, 但是因为闭源不能确定)AI引擎代码是内嵌于SQL计算系统之中的, 并行执行的能力由Spark管理, AI系统就像代码库一样被Spark系统所调用而已.
但SQLFlow明显不是这种模式的:
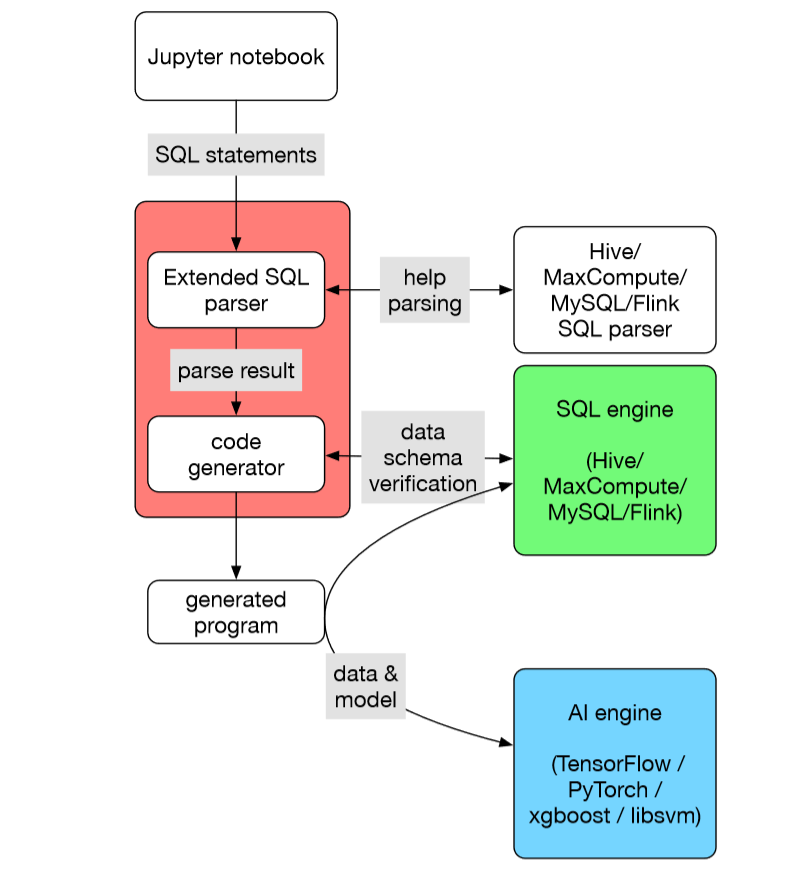
从SQLFlow的架构图上看的出来, AI Engine和SQL Engine之间是独立的, 两者通过RPC交互数据和模型
- AI Engine训练或者推理计算的时候, 从SQLEngine获取数据
- AI Engine完成训练过程, 将模型写入到SQL Engine; 推理过程从SQL Engine读取模型
整个SQLFlow的流程大致如下(图上红色部分为SQLFlow):
- Notebook输入SQL之后, 送入到
Parser之内, 这儿的语法解析借用了Hive/MaxCompute等引擎 - 解析完SQL语法后, 进行
Schema Verification - 然后根据SQL语法, 产生对应的Code(根据不同模型和不同引擎产生不同的Code)
- 最后执行Code
源码解析
最后我们来简单过一遍SQLFlow的代码, 提炼一下找代码框架的思路:
SQLFlow代码量目测在1-1.5万行左右, 半天就能看懂基础流程了
找到入口
首先, 找到整个项目的Dockerfile, 就在根目录下
如果项目有Docker镜像, Dockerfile就是个个进程的入口, 比
main函数还在前面
1
|
ADD scripts/start.sh /
|
看到最后一行启动的命令为start.sh, 源码文件在scripts/start.sh
找到启动文件
1
|
function print_usage() {
|
可以看到启动文件启动了三个内容:
-
mysql: 默认的SQL Engine, 已经初始化了数据
-
sqlflow_server: 我们要找的程序, 找到里面真正的执行命令
sqlflowserver --datasource=${DS} -
sqlflow_notebook: Notebook交互式界面
找到main函数入口
全局搜索function main(), 发现只有cmd/sqlflowserver/main.go有.
在start函数里面找到关键的proto.RegisterSQLFlowServer(s, server.NewServer(sql.Run, nil, modelDir, enableSession))服务启动代码, 其中的sql.Run就整个SQL处理代码.
不太熟悉go语言是怎么出包的
SQL.Run
1
|
func Run(slct string, db *DB, modelDir string, session *pb.Session) *PipeReader {
|
如果是SQL语句, 走入到runStandardSQL分支, 如果有训练或者推理语法, 就会走入runExtendedSQL分支
1
|
func runExtendedSQL(slct string, db *DB, modelDir string, session *pb.Session) *PipeReader {
|
可以看到, 先进行语法解析, 然后进行训练或者推理逻辑, 我们简单看一眼训练过程:
1
|
func train(wr *PipeWriter, tr *extendedSelect, db *DB, cwd string, modelDir string, slct string, ds *trainAndValDataset) error {
|
可以看到, 进入训练过程之后, 先做了语法校验, 然后生成的对应的TF的代码, 然后调用tensorflowCmd执行命令, 最后将模型保存完毕, 完成训练过程.
语法校验先略过, 代码生成过程比较复杂后面再介绍, 我们先关注于命令执行过程:
1
|
func tensorflowCmd(cwd, driverName string) (cmd *exec.Cmd) {
|
tensorflowCmd有两种执行模式: 本地执行和容器执行, 目前这两种方式都是单机执行模型, 实际上这儿就印证了AI Engine和SQL Engine分离的架构
未来这儿可以很方便的将这个扩展为分布式任务, 例如Kubeflow的TFJob,这个这块需要跟代码生成那儿一起修改.
代码生成
让我们在回到genTF这个函数
1
|
func genTF(w io.Writer, pr *extendedSelect, ds *trainAndValDataset, fts fieldTypes, db *DB) error {
|
这儿实际上最关键的是两个训练模板, 这两个模块在template_tf.go里面定义
除了TF的模板, 还有
template_alps和template_elasticdl这两个
模板里面就是Python代码了, 截取里面的一部分说明一下
1
|
import os
|
注意点1是sqlflow_models, 这个是定义在同组织的Model里面, 目前只实现了2个实现dnnclassifier和lstmclassifier, 这里这个dnnclassifier就是试用里面DNNClassifier算法模型的定义所在
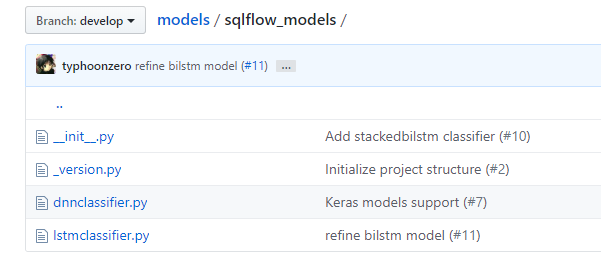
注意点2是sqlflow_submitter这个定义在sql/python/sqlflow_submmiter包目录下, 在这儿你可以执行本地的Python文件, 也可以定义自己的submit将CodeGen的代码当做客户端代码, 给远程的深度学习服务提交自己的学习任务. 同时这儿也定义了与SQL Engine的交互代码逻辑, 就是里面的connect和db_generator
注意点3关注于TensorFlow框架是如何读取从数据库里面的数据的, 使用的接口为tf.data.Dataset.from_generator
至此代码分析已经完成, 主流程已经明确了.
社区动态
蚂蚁对于这个项目的投入还是很大的, 应该由专门的人在投入这个项目, 更新频率还是相当快的
但是贡献者还是比较少的, 应该目前看只有21贡献者, 基本上是蚂蚁金服内部员工.
之前看到他们2019年的路标, 2019年的目标预定是支持各种框架, 例如Calcite支持或者GPU TF支持
总体来说2019年主要在完善功能, 但是后来这个ISSUE关闭了, 不确定19年能否完成这些内容.
总结
SQLFlow目前看还处于原型阶段, 整体支持的能力还非常欠缺: GPU的支持, 模型的定义等功能目前好像都不具备.
就目前整体的设计, 我认为以下三点未来需要加强:
- 模型定义接口太复杂了: 1. 实现一个模板;2. 实现一个模型算法;3. 实现一个submitter. 这套逻辑对于工程师可能比较简单(实际上定义地方太多, 也麻烦), 但是对于AI算法的人, 肯定不是用
AI Engine和SQL Engine分离带来的性能问题, 这套架构的问题就是AI系统离数据远了一点, 所有数据都是通过SQL Engine计算而来, 而且是通过RPC获取的数据, 比起Spark这种直接在内存中获取数据, 这里会成为正式商用时候的大瓶颈点- 数据分布式化工程量太大, 这其实是问题二的引申版, 未来肯定要实现数据分布化, AI计算分布式化, 这钟模式我还没有想到如何分布式化(回去再好好想想)
另外对于这个项目的商业前景如何, 这个确实存疑的, 也许在阿里内部可能有这部分需求, 但对我们来说却不是.
2018年8月BigQuery出了ML之后, 我们也有计划跟进, 调研了XGBoost On Spark, 但最后还是没决定要做, 最主要的原因是没有客户明确需要这个能力.
值得表扬的是: 蚂蚁的文档和demo做的是真好, 做技术调研能遇到这样的项目, 确实让我省了不少功夫.
附录: Go语言环境安装
SQLFlow的主编程语言为Go语言, 安装部署也相对方便, 不记录过程了, 只放置一些安装资源链接