时序列数据库武斗大会之什么是TSDB
由于工作上的关系,最近看了一些关于时序列数据库的东西,当然,我所看的也都是以开源方案为主。
趁着这股热劲还没退,希望能整理一些资料出来。如果正好你也有这方面的需求,那么希望这一系列的介绍能够帮助到你。
1. 什么是时序列数据库(Time series database)?
一听到时序列数据库,如果只是稍有耳闻的人,可能立刻会联想到运维和监控系统。
没错,确实是很多运维、监控系统都采用了TSDB作为数据库系统来存储海量的、严格按时间递增的、在一定程度来说结构非常简单的各种指标(英文可能为metric、measurement或者类似的其他单词)数据。
1.1. 给TSDB一个定义
这是维基百科上的解释:
A time series database (TSDB) is a software system that is optimized for handling time series data, arrays of numbers indexed by time (a datetime or a datetime range).
翻译过来就是“时序列数据库用来存储时序列(time-series)数据并以时间(点或区间)建立索引的软件。”
其中,时序列数据可以定义如下:
- 可以唯一标识的序列名/ID(比如cpu.load.1)及meta-data;
- 一组数据点{timestamp, value}。timestamp是一个Unix时间戳,一般精度会比较高,比如influxdb里面是nano秒。一般来说这个精度都会在秒以上。
一般时序列数据都具备如下两个特点:
- 数据结构简单
- 数据量大
所谓的结构简单,可以理解为某一度量指标在某一时间点只会有一个值,没有复杂的结构(嵌套、层次等)和关系(关联、主外键等)。
数据量大则是另一个重要特点,这是由于时序列数据由所监控的大量数据源来产生、收集和发送,比如主机、IoT设备、终端或App等。
2. TSDB数据库特点
TSDB作为一种专为时序列数据优化而设计的数据库,在很多方面都和传统的RDBMS和NoSQL数据库不太一样,比如它不关心范式和事务。
其他方面TSDB的特点主要有以下几点,这里简单罗列了一下。
2.1. 数据写入
TSDB在数据写入方面,具有如下特点:
- 写多于读
95%-99%的操作都是写操作
- 顺序写
由于是时间序列数据,因此数据多为追加式写入,而且几乎都是实时写入,很少会写入几天前的数据。
- 很少更新
数据写入之后,不会更新
- 区块(bulk)删除
基本没有随机删除,多数是从一个时间点开始到某一时间点结束的整段数据删除。比如删除上个月,或者7天前的数据。很少出现删除单独某个指标的数据,或者跳跃时间段的数据。
区块删除很容易进行优化,比如可以按区块来分开存储到不同的文件,这样删除一个区块只需要删除一个文件就可以了,成本会比较低。
2.2. 数据读取(查询)
相对于写入操作,TSDB的读取操作特点如下:
- 顺序读
基本都是按照时间顺序读取一段时间内的数据。
- 基数大
基本数据大,超过内存大小,要选取的只是其一小部分,且没有规律,缓存几乎不起任何作用。
2.3. 分布式(集群)
TSDB应该天生就要考虑到分布式和分区等特性,将存储和查询分发到不同的服务器,以支撑大规模的数据采集和查询请求。
2.4. 基本数据分析支持
TSDB的数据是用来分析的,所以TSDB还会提供做数据分析所必须的各种运算、变换函数。比如可以方便的对时序列数据进行求和、求平均值等操作,就像传统的RDBMS一样。
3. 如何去选择开源时序列数据库
虽然每个人的场景不太一样,不过我觉得以下的大部分因素,都值得大家好好考量一下。除了功能上能满足、性能上撑得住,运(售)维(后)等也是我们准备长期使用所必须面临的问题。
我自己总结的评价因素主要有如下几点:
3.1. 性能
主要就是读和写的性能,在前面TSDB的特点中我们已经讲过了。
通过前面的说明,我们也知道TSDB 99.9%都是读少写多,因此写入性能必须能跟得上、无延时,并且不能阻塞读操作,且读操作能快速返回最新的数据。
还有一点必须注意的是,现在很多用户的数据都跑在云主机上,那么IOPS则是一个你必须要注意的因素,超了Plan限制的话很难找出问题原因。
3.2. 存储方案(或引擎)
存储方案主要会影响到读写性能、集群扩展容易程度、以及运维的复杂度。典型的存储方案有HDFS、HBase、Cassandra、LevelDB等。
3.3. 集群功能
一般来说,集群主要集中为存储和查询的集群功能,也代表其可扩展性,因为时序列数据库的数据量很可能很大,并且增长趋势不可预测,尤其是随着大数据和物联网的兴起,GB已经算入门,TB也是刚起步。
3.4. API(HTTP API和Client Library)
如果你需要定制,或者只是使用TSDB做存储,自己写入数据并通过查询接口进行数据展示,那么API的完善程度将是一个很重要的评判因素。
还好大部分TSDB都提供了HTTP API,除了简单的文本格式,有很多还支持JSON格式的输入、输出。
Client Library也是一个加分项,有一个好用的、你熟悉的语言的SDK包的话应该会更方便你做开发。
3.5. SQL-like Query Language
如果能通过类似传统SQL的select mean(value) from metric where role='user' and time >= xxx and time <= yyy group by dc来查询metric的话,是不是刚接触到TSDB的人更容易上手和理解呢?
可能这看起来比较酷,不过对我来说这只能算是个加分项而已。因为我们只会通过API来读写数据,而且查询模式非常固定、数量不多。
但是很多经常出报表的人,可能更喜欢这一特点了,因为老板、运营可能会定期或者随时找他们出统计数据。
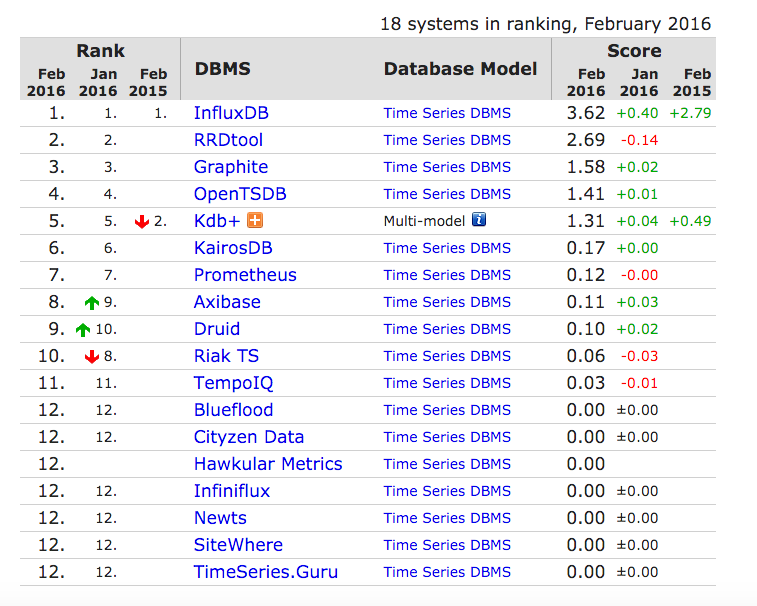
DB-Engines中时序列数据库排名
我们先来看一下DB-Engines中关于时序列数据库的排名
这是当前(2016年2月的)排名情况:
摘自:http://liubin.org/blog/2016/02/18/tsdb-intro/