AlexNet将LeNet的思想发扬光大,把CNN的基本原理应用到了很深很宽的网络中。AlexNet主要使用到的新技术点如下。
(1)成功使用ReLU作为CNN的激活函数,并验证其效果在较深的网络超过了Sigmoid,成功解决了Sigmoid在网络较深时的梯度弥散问题。虽然ReLU激活函数在很久之前就被提出了,但是直到AlexNet的出现才将其发扬光大。
(2)训练时使用Dropout随机忽略一部分神经元,以避免模型过拟合。Dropout虽有单独的论文论述,但是AlexNet将其实用化,通过实践证实了它的效果。在AlexNet中主要是最后几个全连接层使用了Dropout。
(3)在CNN中使用重叠的最大池化。此前CNN中普遍使用平均池化,AlexNet全部使用最大池化,避免平均池化的模糊化效果。并且AlexNet中提出让步长比池化核的尺寸小,这样池化层的输出之间会有重叠和覆盖,提升了特征的丰富性。
(4)提出了LRN层,对局部神经元的活动创建竞争机制,使得其中响应比较大的值变得相对更大,并抑制其他反馈较小的神经元,增强了模型的泛化能力。
LRN(Local Response Normalization)
ImageNet中的LRN层是按下述公式计算的:

但似乎,在后来的设计中,这一层已经被其它种的Regularization技术,如drop out, batch normalization取代了。知道了这些,似乎也可以不那么纠结这个LRN了。
转自:http://blog.csdn.net/searobbers_duck/article/details/51645941
为什么要有局部响应归一化(Local Response Normalization)?
详见http://blog.csdn.net/hduxiejun/article/details/70570086
局部响应归一化原理是仿造生物学上活跃的神经元对相邻神经元的抑制现象(侧抑制),然后根据论文有公式如下
公式解释:
因为这个公式是出自CNN论文的,所以在解释这个公式之前读者应该了解什么是CNN,可以参见
http://blog.csdn.net/whiteinblue/article/details/25281459
http://blog.csdn.net/stdcoutzyx/article/details/41596663
http://www.jeyzhang.com/cnn-learning-notes-1.html
这个公式中的a表示卷积层(包括卷积操作和池化操作)后的输出结果,这个输出结果的结构是一个四维数组[batch,height,width,cha
nnel],这里可以简单解释一下,batch就是
批次数(每一批为一张图片),height就是图片高度,width就是图片宽度,channel就是通道数可以理解成一批图片中的某一个图片经
过卷积操作后输出的神经元个数(或是理解
成处理后的图片深度)。ai(x,y)表示在这个输出结构中的一个位置[a,b,c,d],可以理解成在某一张图中的某一个通道下的某个高度和某
个宽度位置的点,即第a张图的第d个通道下
的高度为b宽度为c的点。论文公式中的N表示通道数(channel)。a,n/2,k,α,β分别表示函数中的input,depth_radius,bias,alpha,beta,其
中n/2,k,α,β都是自定义的,特别注意一下∑叠加的方向是沿着通道方向的,即每个点值的平方和是沿着a中的第3维channel方向
的,也就是一个点同方向的前面n/2个通
道(最小为第0个通道)和后n/2个通道(最大为第d-1个通道)的点的平方和(共n+1个点)。而函数的英文注解中也说明了把input当
成是d个3维的矩阵,说白了就是把input的通道
数当作3维矩阵的个数,叠加的方向也是在
通道方向。
画个简单的示意图:
这里写图片描述
实验代码:
import tensorflow as tf
import numpy as np
x = np.array([i for i in range(1,33)]).reshape([2,2,2,4])
y = tf.nn.lrn(input=x,depth_radius=2,bias=0,alpha=1,beta=1)
with tf.Session() as sess:
print(x)
print('#############')
print(y.eval())
结果解释:
这里要注意一下,如果把这个矩阵变成图片的格式是这样的
这里写图片描述
然后按照上面的叙述我们可以举个例子比如26对应的输出结果0.00923952计算如下
26/(0+1*(25^2+26^2+27^2+28^2))^1
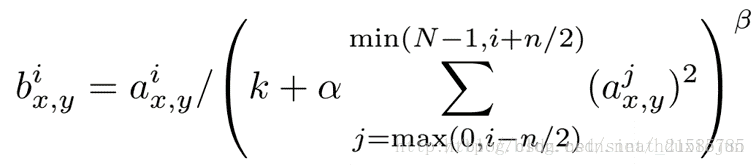

BN本质上解决的是反向传播过程中的梯度问题。
详细点说,反向传播时经过该层的梯度是要乘以该层的参数的,即前向有:
那么反向传播时便有:
那么考虑从l层传到k层的情况,有:
上面这个 便是问题所在。因为网络层很深,如果
大多小于1,那么传到这里的时候梯度会变得很小比如
;而如果
又大多大于1,那么传到这里的时候又会有梯度爆炸问题 比如
。
BN所做的就是解决这个梯度传播的问题,因为BN作用抹去了w的scale影响。
具体有:
(
) =
(
)
那么反向求导时便有了:
可以看到此时反向传播乘以的数不再和 的尺度相关,也就是说尽管我们在更新过程中改变了
的值,但是反向传播的梯度却不受影响。更进一步:
即尺度较大的 将获得一个较小的梯度,在同等的学习速率下其获得的更新更少,这样使得整体
的更新更加稳健起来。
总结起来就是BN解决了反向传播过程中的梯度问题(梯度消失和爆炸),同时使得不同scale的 整体更新步调更一致。
链接:https://www.zhihu.com/question/38102762/answer/164790133
说到底,BN的提出还是为了克服深度神经网络难以训练的弊病。其实BN背后的insight非常简单,只是在文章中被Google复杂化了。
首先来说说“Internal Covariate Shift”。文章的title除了BN这样一个关键词,还有一个便是“ICS”。大家都知道在统计机器学习中的一个经典假设是“源空间(source domain)和目标空间(target domain)的数据分布(distribution)是一致的”。如果不一致,那么就出现了新的机器学习问题,如,transfer learning/domain adaptation等。而covariate shift就是分布不一致假设之下的一个分支问题,它是指源空间和目标空间的条件概率是一致的,但是其边缘概率不同,即:对所有
那么好,为什么前面我说Google将其复杂化了。其实如果严格按照解决covariate shift的路子来做的话,大概就是上“importance weight”(ref)之类的机器学习方法。可是这里Google仅仅说“通过mini-batch来规范化某些层/所有层的输入,从而可以固定每层输入信号的均值与方差”就可以解决问题。如果covariate shift可以用这么简单的方法解决,那前人对其的研究也真真是白做了。此外,试想,均值方差一致的分布就是同样的分布吗?当然不是。显然,ICS只是这个问题的“包装纸”嘛,仅仅是一种high-level demonstration。
那BN到底是什么原理呢?说到底还是为了防止“梯度弥散”。关于梯度弥散,大家都知道一个简单的栗子: