某些网站的一些数据是通过js加载的 ,所以爬取下来的数据拿不到,
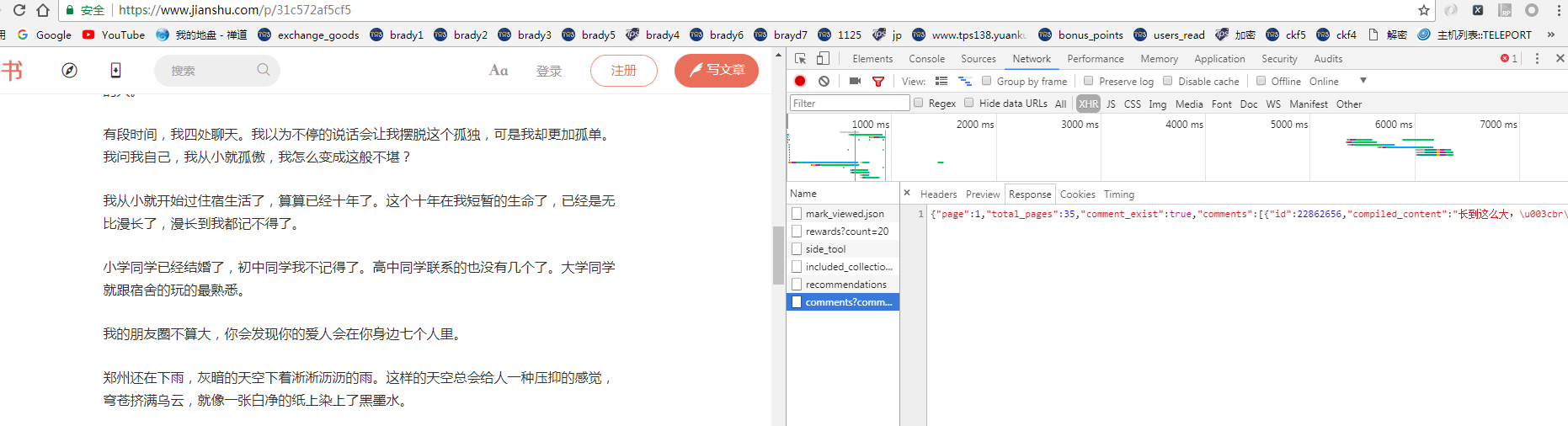
找到评论的地址 .进行请求获取评论数据
#coding=utf-8
import json
import requests
def requests_view(response):
import webbrowser
requests_url = response.url
base_url = '<head><base href="%s">' %(requests_url)
base_url = base_url.encode('utf-8')
content = response.content.replace(b"<head>",base_url)
tem_html = open('tmp.html','wb')
tem_html.write(content)
tem_html.close()
webbrowser.open_new_tab("tmp.html")
headers = {
"User-Agent": 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36'}
response = requests.get("https://www.jianshu.com/notes/26504955/comments?comment_id=&author_only=false&since_id=0&max_id=1586510606000&order_by=likes_count&page=1",headers=headers)
comments = json.loads(response.content)
if comments['comment_exist'] == True:
for item in comments['comments']:
print(item['user']['nickname'],item['compiled_content'])