| python文件目录操作 |
python中对文件、文件夹(文件操作函数)的操作需要涉及到os模块和shutil模块。
得到当前工作目录,即当前Python脚本工作的目录路径: os.getcwd()
返回指定目录下的所有文件和目录名:os.listdir()
函数用来删除一个文件:os.remove()
删除多个目录:os.removedirs(r“c:python”)
检验给出的路径是否是一个文件:os.path.isfile()
检验给出的路径是否是一个目录:os.path.isdir()
判断是否是绝对路径:os.path.isabs()
检验给出的路径是否真地存:os.path.exists()
返回一个路径的目录名和文件名:os.path.split() eg os.path.split('/home/swaroop/byte/code/poem.txt') 结果:('/home/swaroop/byte/code', 'poem.txt')
分离扩展名:os.path.splitext()
获取路径名:os.path.dirname()
获取文件名:os.path.basename()
运行shell命令: os.system()
读取和设置环境变量:os.getenv() 与os.putenv()
给出当前平台使用的行终止符:os.linesep Windows使用' ',Linux使用' '而Mac使用' '
指示你正在使用的平台:os.name 对于Windows,它是'nt',而对于Linux/Unix用户,它是'posix'
重命名:os.rename(old, new)
创建多级目录:os.makedirs(r“c:python est”)
创建单个目录:os.mkdir(“test”)
获取文件属性:os.stat(file)
修改文件权限与时间戳:os.chmod(file)
终止当前进程:os.exit()
获取文件大小:os.path.getsize(filename)
| 文件操作 |
os.mknod("test.txt") 创建空文件
fp = open("test.txt",w) 直接打开一个文件,如果文件不存在则创建文件
关于open 模式:
w 以写方式打开,
a 以追加模式打开 (从 EOF 开始, 必要时创建新文件)
r+ 以读写模式打开
w+ 以读写模式打开 (参见 w )
a+ 以读写模式打开 (参见 a )
rb 以二进制读模式打开
wb 以二进制写模式打开 (参见 w )
ab 以二进制追加模式打开 (参见 a )
rb+ 以二进制读写模式打开 (参见 r+ )
wb+ 以二进制读写模式打开 (参见 w+ )
ab+ 以二进制读写模式打开 (参见 a+ )
fp.read([size]) #size为读取的长度,以byte为单位
fp.readline([size]) #读一行,如果定义了size,有可能返回的只是一行的一部分
fp.readlines([size]) #把文件每一行作为一个list的一个成员,并返回这个list。其实它的内部是通过循环调用readline()来实现的。如果提供size参数,size是表示读取内容的总长,也就是说可能只读到文件的一部分。
fp.write(str) #把str写到文件中,write()并不会在str后加上一个换行符
fp.writelines(seq) #把seq的内容全部写到文件中(多行一次性写入)。这个函数也只是忠实地写入,不会在每行后面加上任何东西。
fp.close() #关闭文件。python会在一个文件不用后自动关闭文件,不过这一功能没有保证,最好还是养成自己关闭的习惯。 如果一个文件在关闭后还对其进行操作会产生ValueError
fp.flush() #把缓冲区的内容写入硬盘
fp.fileno() #返回一个长整型的”文件标签“
fp.isatty() #文件是否是一个终端设备文件(unix系统中的)
fp.tell() #返回文件操作标记的当前位置,以文件的开头为原点
fp.next() #返回下一行,并将文件操作标记位移到下一行。把一个file用于for … in file这样的语句时,就是调用next()函数来实现遍历的。
fp.seek(offset[,whence]) #将文件打操作标记移到offset的位置。这个offset一般是相对于文件的开头来计算的,一般为正数。但如果提供了whence参数就不一定了,whence可以为0表示从头开始计算,1表示以当前位置为原点计算。2表示以文件末尾为原点进行计算。需要注意,如果文件以a或a+的模式打开,每次进行写操作时,文件操作标记会自动返回到文件末尾。
fp.truncate([size]) #把文件裁成规定的大小,默认的是裁到当前文件操作标记的位置。如果size比文件的大小还要大,依据系统的不同可能是不改变文件,也可能是用0把文件补到相应的大小,也可能是以一些随机的内容加上去。
| 目录操作 |
os.mkdir("file") 创建目录
复制文件:
shutil.copyfile("oldfile","newfile") oldfile和newfile都只能是文件
shutil.copy("oldfile","newfile") oldfile只能是文件夹,newfile可以是文件,也可以是目标目录
复制文件夹:
shutil.copytree("olddir","newdir") olddir和newdir都只能是目录,且newdir必须不存在
重命名文件(目录)
os.rename("oldname","newname") 文件或目录都是使用这条命令
移动文件(目录)
shutil.move("oldpos","newpos")
删除文件
os.remove("file")
删除目录
os.rmdir("dir")只能删除空目录
shutil.rmtree("dir") 空目录、有内容的目录都可以删
转换目录
os.chdir("path") 换路径
| python编码和转码 |
第一阶段:起源,ASCII
计算机是美国人发明的,人家用的是美式英语,字符比较少,所以一开始就设计了一个不大的二维表,128个字符,取名叫ASCII(American Standard Code for Information Interchange)。但是7位编码的字符集只能支持128个字符,为了表示更多的欧洲常用字符对ASCII进行了扩展,ASCII扩展字符集使用8位(bits)表示一个字符,共256字符。即其最多只能用 8 位来表示(一个字节)。
第二阶段:GBK
当计算机传到了亚洲,尤其是东亚,国际标准被秒杀了,路边小孩随便说句话,256个码位就不够用了。于是,中国定制了GBK。用2个字节代表一个字符(汉字)。其他国家也纷纷定制了自己的编码,例如:
日本把日文编到Shift_JIS里,韩国把韩文编到Euc-kr里。
第三阶段:unicode
当互联网席卷了全球,地域限制被打破了,不同国家和地区的计算机在交换数据的过程中,就会出现乱码的问题,跟语言上的地理隔离差不多。为了解决这个问题,一个伟大的创想产生了——Unicode(万国码)。Unicode编码系统为表达任意语言的任意字符而设计。
规定所有的字符和符号最少由 16 位来表示(2个字节),即:2 **16 = 65536,注:此处说的的是至少2个字节(16位),可能更多。
第四阶段:UTF-8
unicode的编码方式虽然包容万国,但是对于英文等字符就会浪费太多存储空间。于是出现了UTF-8,是对Unicode编码的压缩和优化,遵循能用最少的表示就用最少的表示,他不再使用最少使用2个字节,而是将所有的字符和符号进行分类:ascii码中的内容用1个字节保存、欧洲的字符用2个字节保存,东亚的字符用3个字节保存。
unicode:包容万国,优点是字符->数字的转换速度快,缺点是占用空间大
utf-8:精准,对不同的字符用不同的长度表示,优点是节省空间,缺点是:字符->数字的转换速度慢,因为每次都需要计算出字符需要多长的Bytes才能够准确表示
内存中使用的编码是unicode,用空间换时间,为了快 因为程序都需要加载到内存才能运行,因而内存应该是尽可能的保证快。 硬盘中或者网络传输用utf-8,网络I/O延迟或磁盘I/O延迟要远大与utf-8的转换延迟,而且I/O应该是尽可能地节省带宽,保证数据传输的稳定性。 因为数据的传输,追求的是稳定,高效,数据量越小数据传输就越靠谱,于是都转成utf-8格式的,而不是unicode。
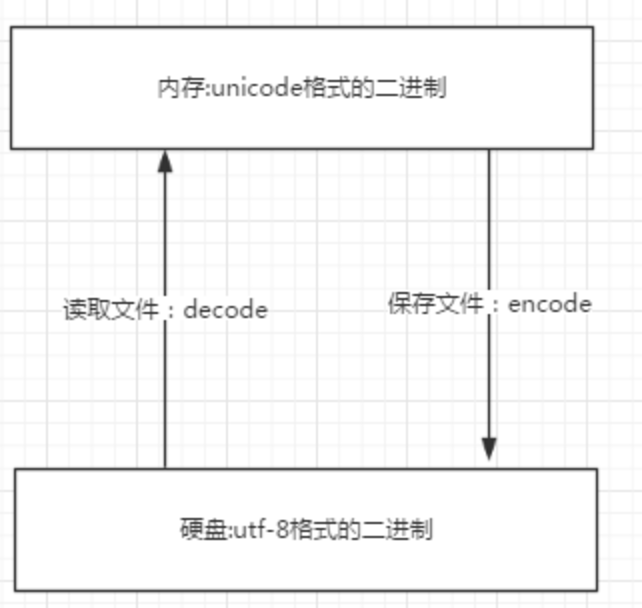
字符编码的使用:
1)文本编辑器存取文件的原理(nodepad++,pycharm,word)
打开编辑器就打开了启动了一个进程,是在内存中的,所以在编辑器编写的内容也都是存放与内存中的,断电后数据丢失。因而需要保存到硬盘上,点击保存按钮,就从内存中把数据刷到了硬盘上。在这一点上,我们编写一个py文件(没有执行),跟编写其他文件没有任何区别,都只是在编写一堆字符而已。
无论是何种编辑器,要防止文件出现乱码,核心法则就是,文件以什么编码保存的,就以什么编码方式打开。
2)python解释器执行py文件的原理 (python test.py)
第一阶段:python解释器启动,此时就相当于启动了一个文本编辑器
第二阶段:python解释器相当于文本编辑器,去打开test.py文件,从硬盘上将test.py的文件内容读入到内存中
第三阶段:python解释器解释执行刚刚加载到内存中test.py的代码
补充:
所以,在写代码时,为了不出现乱码,推荐使用UTF-8,会加入 # -*- coding: utf-8 -*-
即
#!/usr/bin/env python # -*- coding: utf-8 -*- print "你好,世界"
python解释器会读取test.py的第二行内容,# -*- coding: utf-8 -*-,来决定以什么编码格式来读入内存,这一行就是来设定python解释器这个软件的编码使用的编码格式这个编码。
如果不在python文件指定头信息#-*-coding:utf-8-*-,那就使用默认的python2中默认使用ascii,python3中默认使用utf-8
总结:
1)python解释器是解释执行文件内容的,因而python解释器具备读py文件的功能,这一点与文本编辑器一样
2)与文本编辑器不一样的地方在于,python解释器不仅可以读文件内容,还可以执行文件内容
3)python2和python3的一些不同
1) python2中默认使用ascii,python3中默认使用utf-8
2) Python2中,str就是编码后的结果bytes,str=bytes,所以s只能decode。
3) python3中的字符串与python2中的u'字符串',都是unicode,只能encode,所以无论如何打印都不会乱码,因为可以理解为从内存打印到内存,即内存->内存,unicode->unicode
4) python3中,str是unicode,当程序执行时,无需加u,str也会被以unicode形式保存新的内存空间中,str可以直接encode成任意编码格式,s.encode('utf-8'),s.encode('gbk')
#unicode(str)-----encode---->utf-8(bytes) #utf-8(bytes)-----decode---->unicode
5)在windows终端编码为gbk,linux是UTF-8.
| python函数 |
| 递归 |
1 def calc(n): 2 print(n) 3 if int(n/2)>0: 4 return calc(int(n/2)) 5 print(n) 6 7 n=calc(10)
运行结果:
1 执行结果: 2 10 3 5 4 2 5 1 6 1
函数的好处
1.没有使用函数导致代码结构无组织无结构,代码冗余;
2.没有使用函数导致代码可读性差
3.没有使用函数导致代码无法统一管理且维护成本高
函数的分类:
在python中函数分两类:内置函数,自定义函数
1、内置函数
 内置函数
内置函数

1 sum 2 max 3 min 4 5 a=len('hello') 6 print(a) 7 8 b=max([1,2,3]) 9 print(b)
2、自定义函数
def print_star(): print('#'*6) def print_msg(): print('hello world') print_star() print_star() print_star() print_msg() print_star() print_star() print_star()
3、函数参数
从大的角度去看,函数的参数分两种:形参(变量名),实参(值)
#1)定义阶段 def foo(x,y): #x=1,y=2 print(x) print(y) #2)调用阶段 foo(1,2)
详细的区分函数的参数分为五种:
位置参数,关键字参数,默认参数,可变长参数(*args,**kwargs),命名关键字参数
1)位置参数:
1 def foo(x,y,z):#位置形参:必须被传值的参数 2 print(x,y,z) 3 4 foo(1,2,3) 5 foo(1,2,3) #位置实参数:与形参一一对应
2)关键字参数:key = value
def foo(x,y,z): print(x,y,z) foo(z=3,x=1,y=2) # 关键字参数需要注意的问题: # 1:关键字实参必须在位置实参后面 # 2: 不能多次重复对一个形参数传值 foo(1,z=3,y=2) #正确 foo(x=1,2,z=3) #错误 foo(1,x=1,y=2,z=3)
3)默认参数:
def register(name,age,sex='male'): #形参:默认参数 print(name,age,sex) register('asb',age=40) register('a1sb',39) register('a2sb',30) register('a3sb',29) register('钢蛋',20,'female') register('钢蛋',sex='female',age=19)
默认参数需要注意的问题:
一:默认参数必须跟在非默认参数后
def register(sex='male',name,age): #在定义阶段就会报错
print(name,age,sex)
(了解)二:默认参数在定义阶段就已经赋值了,而且只在定义阶段赋值一次
a=100000000
def foo(x,y=a):
print(x,y)
a=0
foo(1)
三:默认参数的值通常定义成不可变类型
4)可变长参数(*args,**kwargs)
1 def foo(x,y,*args): #*会把溢出的按位置定义的实参都接收,以元组的形式赋值给args 2 print(x,y) 3 print(args) 4 5 foo(1,2,3,4,5) 6 7 8 def add(*args): 9 res=0 10 for i in args: 11 res+=i 12 return res 13 print(add(1,2,3,4)) 14 print(add(1,2)) 15 16 def foo(x, y, **kwargs): # **会把溢出的按关键字定义的实参都接收,以字典的形式赋值给kwargs 17 print(x, y) 18 print(kwargs) 19 foo(1,2,a=1,name='egon',age=18) 20 21 22 def foo(name,age,**kwargs): 23 print(name,age) 24 if 'sex' in kwargs: 25 print(kwargs['sex']) 26 if 'height' in kwargs: 27 print(kwargs['height']) 28 29 foo('egon',18,sex='male',height='185') 30 foo('egon',18,sex='male')
5)命名关键字参数(了解)
1 def foo(name,age,*,sex='male',height): 2 print(name,age) 3 print(sex) 4 print(height) 5 #*后定义的参数为命名关键字参数,这类参数,必须被传值,而且必须以关键字实参的形式去传值 6 foo('egon',17,height='185') 7 8 9 10 def foo(name,age=10,*args,sex='male',height,**kwargs): 11 def foo(name,age=10,*args,sex='male',height,**kwargs): 12 print(name) 13 print(age) 14 print(args) 15 print(sex) 16 print(height) 17 print(kwargs) 18 19 foo('alex',1,2,3,4,5,sex='female',height='150',a=1,b=2,c=3) 20 21 22 def foo(*args): 23 print(args) 24 25 foo(1,2,3,4) # 1,2,3,4 <=====>*(1,2,3,4) 26 27 *['A','B','C','D'],=====>'A','B','C','D' 28 foo(*['A','B','C','D']) #foo('A','B','C','D') 29 foo(['A','B','C','D']) # 30 31 def foo(x,y,z): 32 print(x,y,z) 33 34 # foo(*[1,2,3]) #foo(1,2,3) 35 foo(*[1,2]) #foo(1,2) 36 37 38 def foo(**kwargs): 39 print(kwargs) 40 41 #x=1,y=2 <====>**{'y': 2, 'x': 1} 42 # foo(x=1,y=2) 43 44 foo(**{'y': 2, 'x': 1,'a':1}) #foo(a=1,y=2,x=1) 45 46 def foo(x,y,z): 47 print(x,y,z) 48 49 # foo(**{'z':3,'x':1,'y':2}) #foo(x=1,z=3,y=2) 50 foo(**{'z':3,'x':1}) #foo(x=1,z=3) 51 52 53 def foo(x,y,z): 54 print('from foo',x,y,z) 55 56 def wrapper(*args,**kwargs): 57 print(args) 58 print(kwargs) 59 60 61 wrapper(1,2,3,a=1,b=2) 62 63 64 65 def foo(x,y,z): 66 print('from foo',x,y,z) 67 def wrapper(*args,**kwargs): 68 print(args) #args=(1,2,3) 69 print(kwargs) #kwargs={'a':1,'b':2} 70 foo(*args,**kwargs) #foo(*(1,2,3),**{'a':1,'b':2}) #foo(1,2,3,b=2,a=1) 71 # wrapper(1,2,3,a=1,b=2) 72 wrapper(1,z=2,y=3) 73 74 75 76 def foo(x,y,z): 77 print('from foo',x,y,z) 78 def wrapper(*args,**kwargs): 79 # print(args) #args=(1,) 80 # print(kwargs) #kwargs={'y':3,'z':2} 81 foo(*args,**kwargs) #foo(*(1,),**{'y':3,'z':2}) #foo(1,z=2,y=3) 82 # wrapper(1,2,3,a=1,b=2) 83 wrapper(1,z=2,y=3)