版本规划

安装VirtualBox

然后直接一路下一步

选择一下安装路径


这时VirtualBox会自动运行,主界面如下 :
安装VirtualBox Extension Pack
VirtualBox的一些高级特性依赖于VirtualBox Extension Pack,接下来我们安装它。
在VirtualBox的主界面点击"全局设定",会弹出全局设定窗口,如下图所示:
在全局这顶窗口,切换到"扩展"选项卡,然后点击"添加"按钮,如下图所示:
在弹出窗口中找到并选择Oracle_VM_VirtualBox_Extension_Pack,然后点击“打开”,如下图所示:

在弹出窗口中找到并选择Oracle_VM_VirtualBox_Extension_Pack,然后点击“打开”

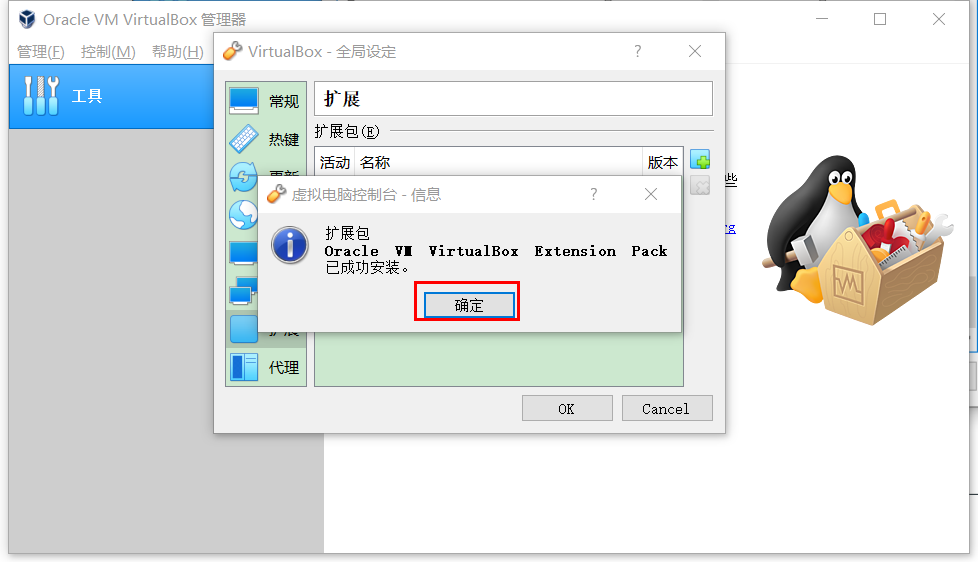
等待一小会安装成功后会弹出确认窗口,点击"确定"即可
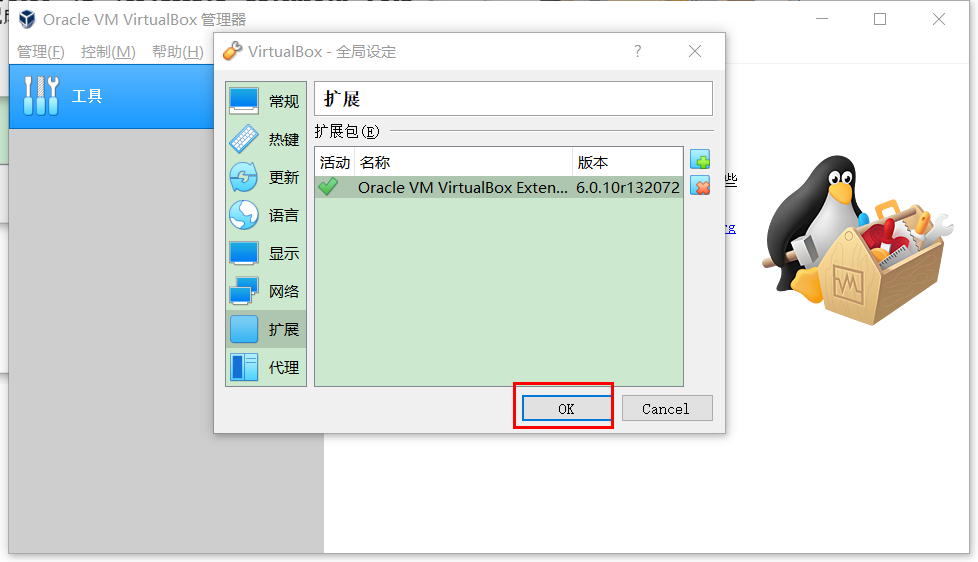
至此扩展包就安装好了 。
新建虚拟机 

文件夹要专门指定一个空间充足的目录,类型一定要选Linux,版本一定要选择Red Hat 64-bit(CentOS
是Red Hat的社区版,64位才可以支持大内存,32 位最多支持4G内存)
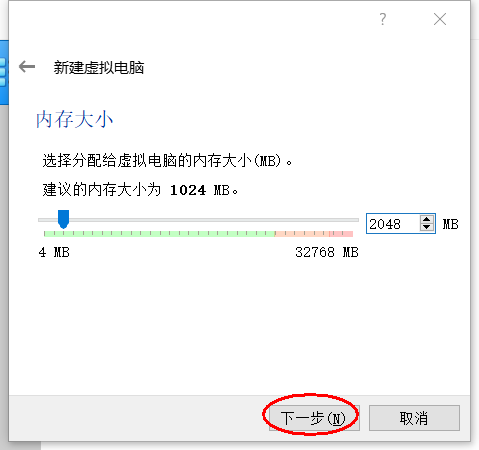
我们先制定2G内存,后面可以改的

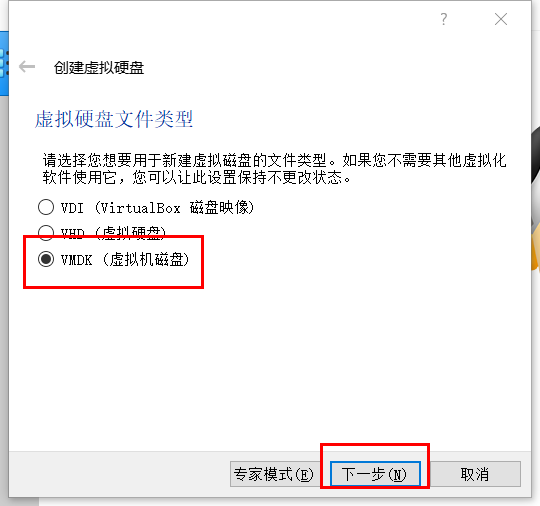
VMDK类型可以分割为2G的小文件便于分享给别人,或者上传到网盘,如果你自己搭建可以
选择VDI
磁盘空间大小选择"动态分配",然后点击下一步,如下图所示
这里关于两种分配方式特殊说明如下:
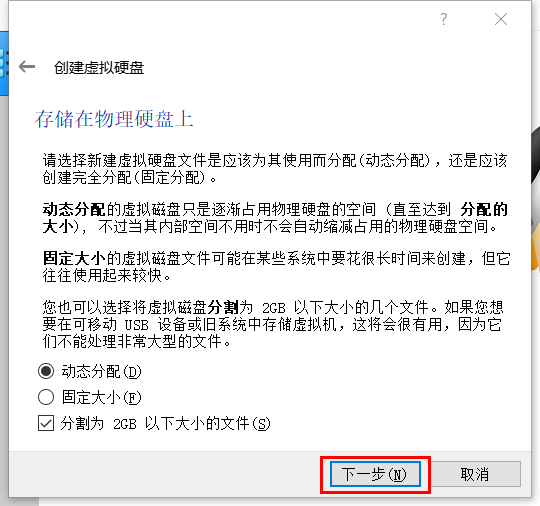


⚠注意:这里设置的是可以使用的最大空间,并不是真正的占用,所以可以设置大一些避免后面不够用。
点击创建之后,一个叫node01的虚拟机就创建好了 
特别注意:没必要一次性创建一堆虚拟机,如果操作系统需求是一样的,可以采用虚拟机克隆,后
面会详述,这样可以避免很多工作,这也是虚拟机的一大好处 。
虚拟机高级设置
有了一台虚拟机,接下来我们进行一些高级设置以便于后面使用。
选择要设置的虚拟机,然后点击“设置”

调节内存大小 
网络设置
切换到“网络”选项卡,连接方式选择"桥接网卡",界面名称实际上是选择你要桥接的物理网卡 
四种网络连接模式:
安装操作系统CentOS7 
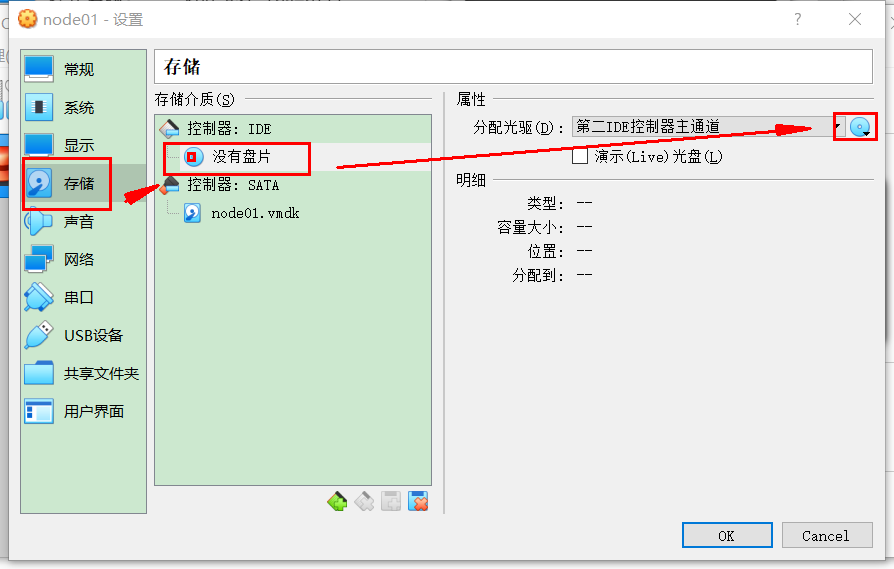
点击选择一个虚拟光盘文件

最后我们就能看到光盘插进光驱了,点击"OK"即可:

启动虚拟机 




这个要默认的就好


这个选择默认的
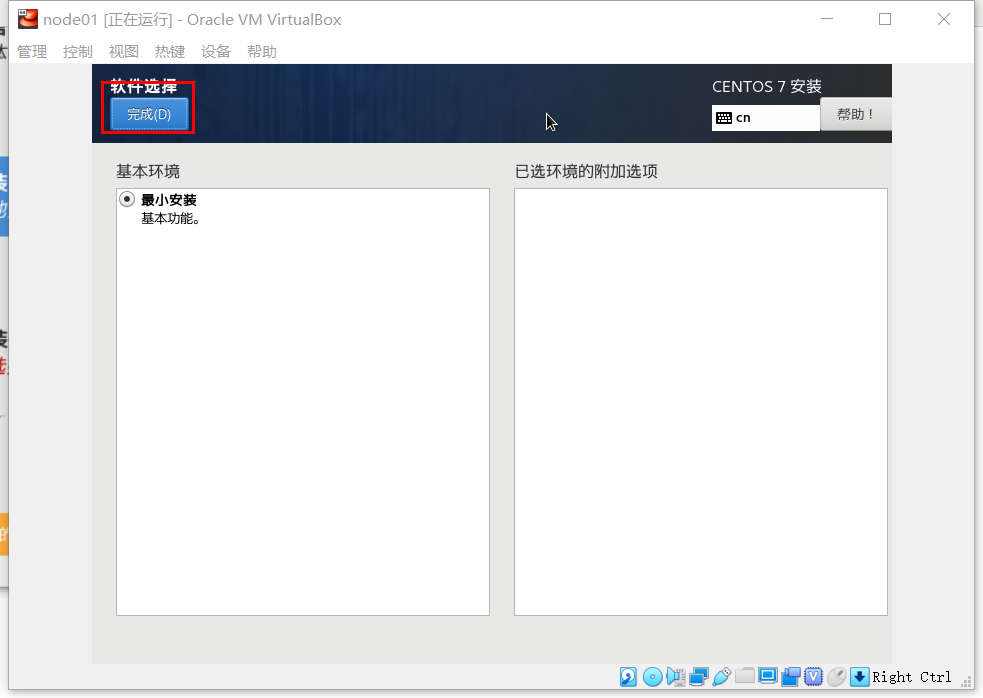
禁用Kdump 
然后我们就看见 Kdump已经禁用了 :
网络和主机名设置 

自定义分区




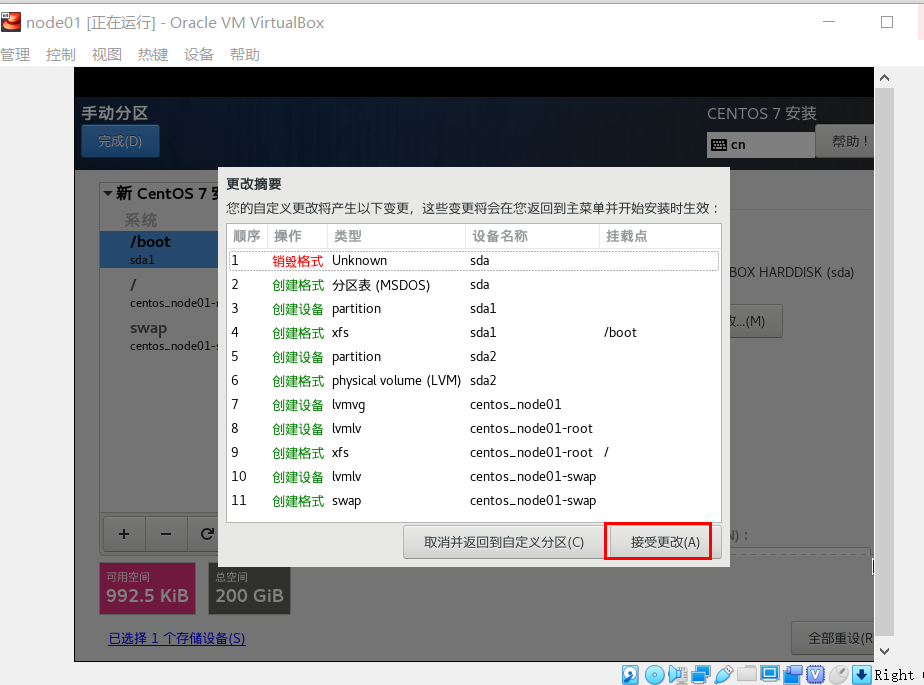

用户设置
修改root用户密码


创建hadoop用户作为管理员 
等安装结束后

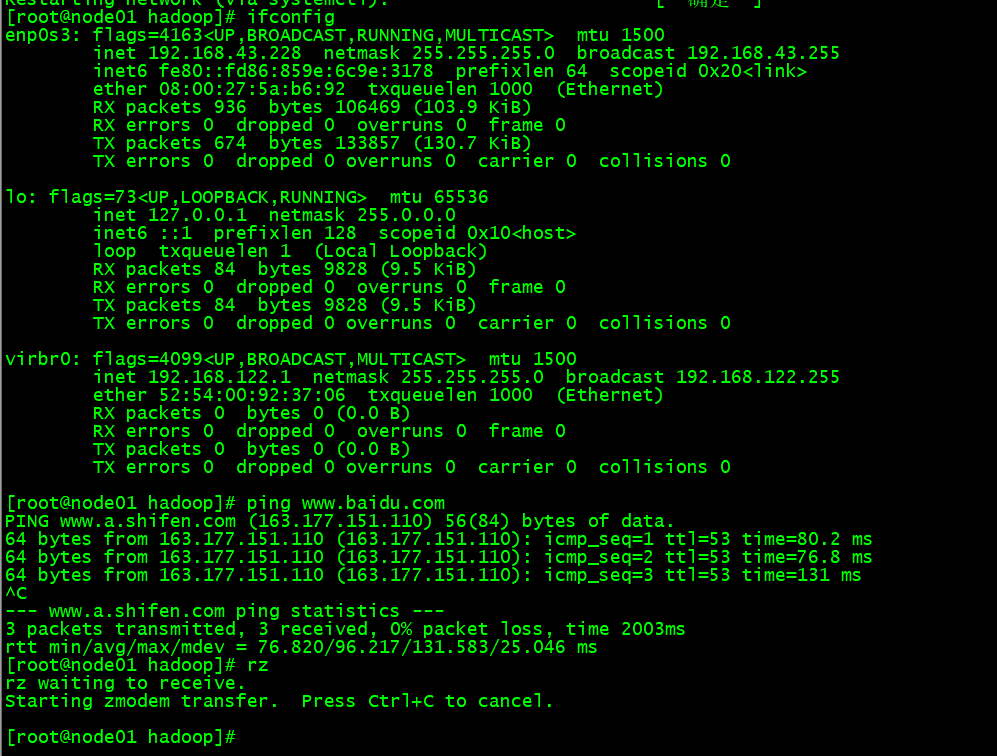
配置网络


测试网络连接情况
#安装网络工具包
yum -y install net-tools
#Ambari用到的下载工具
sudo yum -y install wget
通过软件SecureCRT进行远程连接


首先需要在 SecureCRT设置默认路径:
Options -> Session Options -> Terminal -> Xmodem/Zmodem ->Directories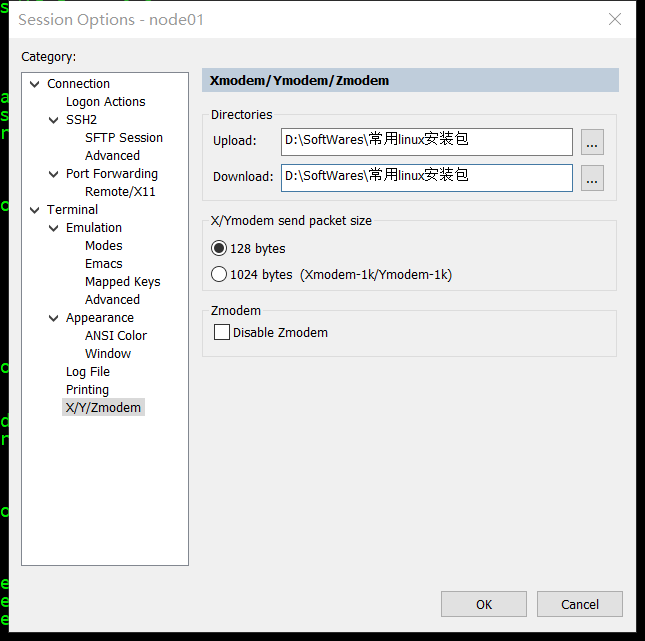
赋予hadoop用户sudo权限
在工作中一般不会让我们通过root用户来操作,因此我们给hadoop用于赋予sudo权限 :
切换到root用户
并输入命令
visudo
这时会进入/etc/sudoers文件的编辑页面,增加如下配置即可
hadoop ALL=(ALL) NOPASSWD: ALL
#以下这行一定要注释掉以免被覆盖(hadoop用户属于wheel组)
#%wheel ALL=(ALL) ALL
配置固定IP
前面我们已经设置为桥接网络,也就是说虚拟机会把宿主机的指定网卡当做“交换机”,首先我们再次看
下当前IP:

sudo vim /etc/sysconfig/network-scripts/ifcfg-enp0s3
作以下修改

修改完重启下网络服务:
sudo service network restart

这个时候需要把远程终端的地址修改一下

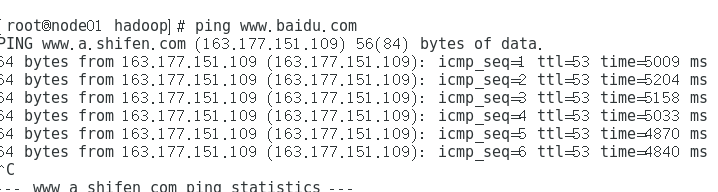
再ping一下baidu,测试一下网络连接情况

配置hosts文件
sudo vi /etc/hosts
添加以下内容

注意:最前面两行一定不要删除,避免出现各种奇怪的网络问题
防火墙设置
#禁止防火墙开机启动
sudo systemctl disable firewalld
#关闭防火墙
sudo systemctl stop firewalld
#查看防火墙状态
sudo systemctl status firewalld

禁用SELinux
检查SELinux状态
getenforce

只要返回的不是disabled就说明SElinux打开着
临时禁用(不需要重启,但必须操作一下 )
sudo setenforce 0
永久禁用
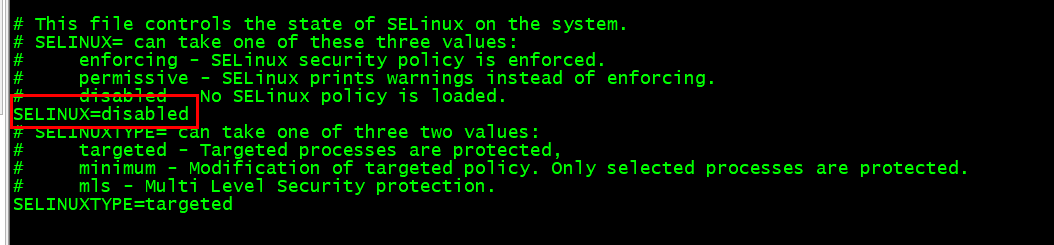
sudo vi /etc/selinux/config
将SELINUX=enforcing改为 SELINUX=disabled:
umask设置
umask用于设置在Linux上创建新文件或文件夹时授予的默认权限或基本权限。 大多数Linux发行版将
022设置为默认umask值。 umask值022授予新文件或文件夹的755权限。 umask值027授予新文件或
文件夹的750权限。
Ambari,HDP和HDF支持的umask值为022( 等价于0022),027(等价于0027)。 这些值必须在所
有主机上设置。
sudo vim /etc/profile
在最后一行添加

使环境变量生效

文件描述符配置
Linux操作系统会对每个进程能打开的文件数进行限制(某用户下某进程),Hadoop生态系统的很多组件
一般都会打开大量的文件,因此要调大相关参数(生产环境必须调大,学习环境稍微大点就可以)
可以用如下命令检查当前用户下一个进程能打开的文件数:
ulimit -Sn
ulimit -Hn

注意:上面的命令只能检查当前用户hadoop。
如果数字小于10000就需要加大
sudo vi /etc/security/limits.conf
添加以下内容
* soft nofile 655350 * hard nofile 655350

重启使系统生效
sudo systemctl reboot
SSH优化
CentOS7下,每次远程SSH连接都需要5秒左右,通过如下操作可以优化:
sudo vi /etc/ssh/sshd_config
查找GSSAPIAuthentication 赋值为no
查找UseDNS,赋值为 no(该项默认不启用的,要把前面的#删除掉 )
保存退出,并重启ssh服务
sudo systemctl restart sshd
SSH免密
ssh-keygen cd .ssh cat id_rsa.pub >> authorized_keys chmod 700 ~/.ssh chmod 600 ~/.ssh/authorized_keys




安装Java

配置环境变量
sudo vim /etc/profile
添加以下内容
export JAVA_HOME=/usr/local/jdk export JRE_HOME=${JAVA_HOME}/jre export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib export PATH=${JAVA_HOME}/bin:$PATH
使环境变量生效
source /etc/profile

克隆出一台新虚拟机
到目前为止作为,一台标准的干净的大数据节点就完全创建被设置好了,为了便于后续扩展成多个节
点,我们先基于node01克隆出一个标准虚拟机备用
先将node01关闭
sudo systemctl poweroff
然后

给克隆出的虚拟机命名为node02,选择一个路径,Mac地址设定一定要选择“为所有网卡重新生成mac
地址”,然后点击“下一步”,


复制过程需要持续几分钟

可以看到复制好了。
准备本地yum源
我们的思路是把HDP所需要的RPM安装包都下载到本地创建一个本地yum源,后续安装就直接使用本
地yum源,这样速度比较快,也可以在内网操作
准备HDP相关文件
需要从以下地址下载相关文件:
Ambari相关安装包:
http://public-repo-1.hortonworks.com/ambari/centos7/2.x/updates/2.7.4.0/ambari-2.7.4.0-centos7.tar.gz
HDP安装:
http://public-repo-1.hortonworks.com/HDP/centos7/3.x/updates/3.1.4.0/HDP-3.1.4.0-centos7-rpm.tar.gz
HDP-UTIL安装包:
http://public-repo-1.hortonworks.com/HDP-UTILS-1.1.0.22/repos/centos7/HDP-UTILS-1.1.0.22-centos7.tar.gz
HDP-GPL文件:
http://public-repo-1.hortonworks.com/HDP-GPL/centos7/3.x/updates/3.1.4.0/HDP-GPL-3.1.4.0-centos7gpl.tar.gz
拿到这些包之后,使用FileZilla上传到node01的hadoop用户主目录下即可 
安装Apache
#安装Apache sudo yum -y install httpd #讲Apache设置为开机启动 sudo systemctl enable httpd #启动Apache sudo systemctl start httpd
修改本地的hosts文件
添加以下内容

打开浏览器访问地址: http://node01

HDP安装包部署到Apache
#移动所有包到/var/www/html/下:
cd /var/www/html/
sudo mv ~/ambari-2.7.4.0-centos7.tar.gz /var/www/html/
sudo mv ~/HDP-3.1.4.0-centos7-rpm.tar.gz /var/www/html/
sudo mv ~/HDP-GPL-3.1.4.0-centos7-gpl.tar.gz /var/www/html/
sudo mv ~/HDP-UTILS-1.1.0.22-centos7.tar.gz /var/www/html/
#解压缩
sudo tar -zxvf ambari-2.7.4.0-centos7.tar.gz
sudo tar -zxvf HDP-3.1.4.0-centos7-rpm.tar.gz
sudo tar -zxvf HDP-GPL-3.1.4.0-centos7-gpl.tar.gz
sudo tar -zxvf HDP-UTILS-1.1.0.22-centos7.tar.gz
#安装压缩包清理
sudo rm -r ambari-2.7.4.0-centos7.tar.gz
sudo rm -r HDP-3.1.4.0-centos7-rpm.tar.gz
sudo rm -r HDP-GPL-3.1.4.0-centos7-gpl.tar.gz
sudo rm -r HDP-UTILS-1.1.0.22-centos7.tar.gz
#更改目录权限
sudo chmod -R ugo+rX /var/www/html/
配置使用本地yum源
在node01上执行:
cd /etc/yum.repos.d/
sudo vi ambari.repo
ambari.repo内容如下
[ambari-repo]
name=ambari
baseurl=http://node01/ambari/centos7/2.7.4.0-118/
gpgcheck=0
enabled=1
验证
yum repolist

安装MySQL
下载安装包
sudo wget http://dev.mysql.com/get/mysql57-community-release-el7-11.noarch.rpm
安装mysql源
sudo yum -y install mysql57-community-release-el7-11.noarch.rpm
安装mysql服务器
sudo yum -y install mysql-community-server
设置为开机启动
sudo systemctl enable mysqld
启动Mysql
sudo systemctl start mysqld
查看mysql状态
sudo systemctl status mysqld
查看临时root临时密码
sudo grep 'temporary password' /var/log/mysqld.log

利用临时密码登录mysql

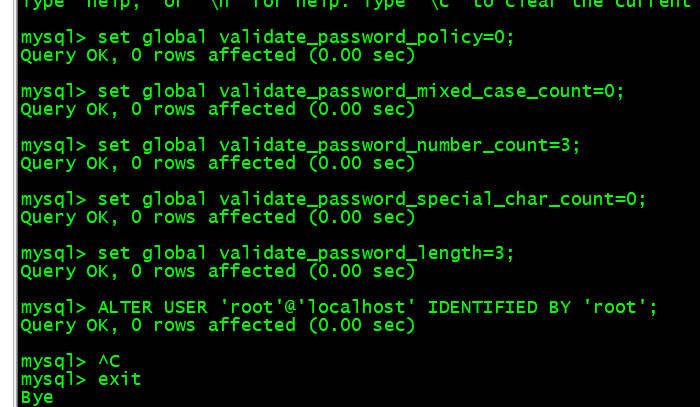
现在我们修改root用户密码:
set global validate_password_policy=0;
set global validate_password_mixed_case_count=0;
set global validate_password_number_count=3;
set global validate_password_special_char_count=0;
set global validate_password_length=3;
ALTER USER 'root'@'localhost' IDENTIFIED BY 'root';
exit
安装MySQL的Java驱动
将MySQL的java驱动mysql-connector-java-8.0.18.jar上传到node01的用户主目录,并移动到一个目录下:
sudo mkdir -p /usr/share/java
sudo mv ~/mysql-connector-java-8.0.18.jar /usr/share/java
部署AmbariServer
在node01上执行
sudo yum -y install ambari-server

创建Ambari数据库资源
Ambari在配置的时候需要MySQL来存储数据,因此我们来创建相关数据库资源,进入MySQL
执行如下命令:
set global validate_password_policy=0;
set global validate_password_mixed_case_count=0;
set global validate_password_number_count=3;
set global validate_password_special_char_count=0;
set global validate_password_length=3;
create database ambari;
CREATE USER 'ambari'@'%' IDENTIFIED BY 'bigdata';
GRANT ALL ON ambari.* TO 'ambari'@'%';
FLUSH PRIVILEGES;
use ambari;
source /var/lib/ambari-server/resources/Ambari-DDL-MySQL-CREATE.sql;
exit
配置AmbariServer
执行如下命令开始设置Ambari-Server:
sudo ambari-server setup
是否自定义ambari-server的运行用户

我们保持默认root用户即可,所以输入n并回车

在上图中,我们选择2,代表自定义java,然后回车

我们需要指定自己安装的java的路径/usr/local/jdk,然后回车

上图提示是否下载并安装LZO的包,我们输入y并回车

是否进入数据库高级设置,我们输入y然后回车

在选择数据库的环节,我们选择3也就是MySQL,然后回车

MySQL的相关配置我们均采用默认值,默认用户和db都是ambari,密码是bigdata,然后回车(它会自
动创建):

我们需要指定MySQL的驱动包所在的路径/usr/share/java/mysql-connector-java-8.0.18.jar,
然后回车

我们选择可以远程连接该数据库(y),然后回车就配置完毕了
调大node01的内存
先把node01关机
sudo systemctl poweroff
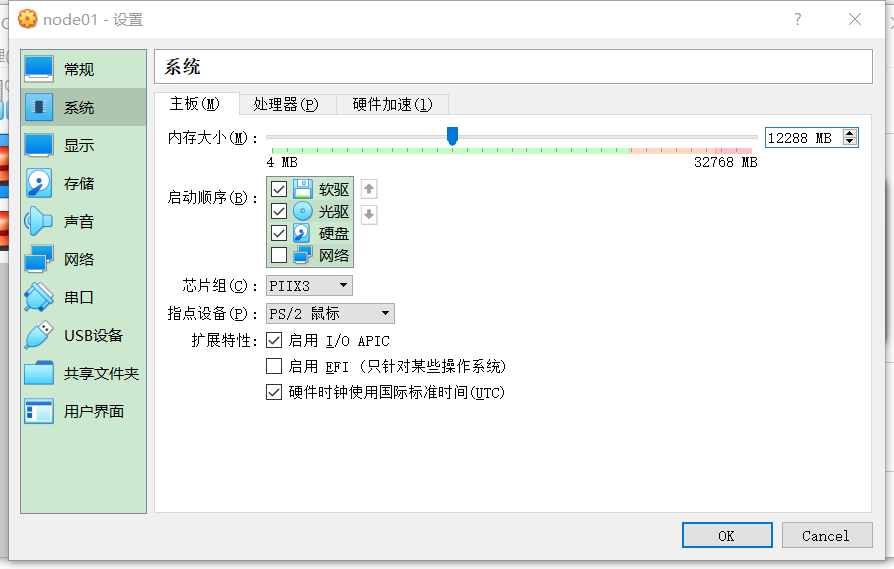
如果你准备一直单机运行可以把内存调整到12G,前提是你的物理宿主机器起码16G内存
启动Ambari-Sever
sudo ambari-server start
如果出现错误,一定要查看日志
vi /var/log/ambari-server/ambari-server.log
然后访问以下地址;
用户名密码默认是admin/admin,如果看到如下界面就代表ambari真正启动好了 
部署Amabri集群
点击Ambari主界面中的"Launch Install Wizard",启动安装向导
接下来我们要给集群起个名字 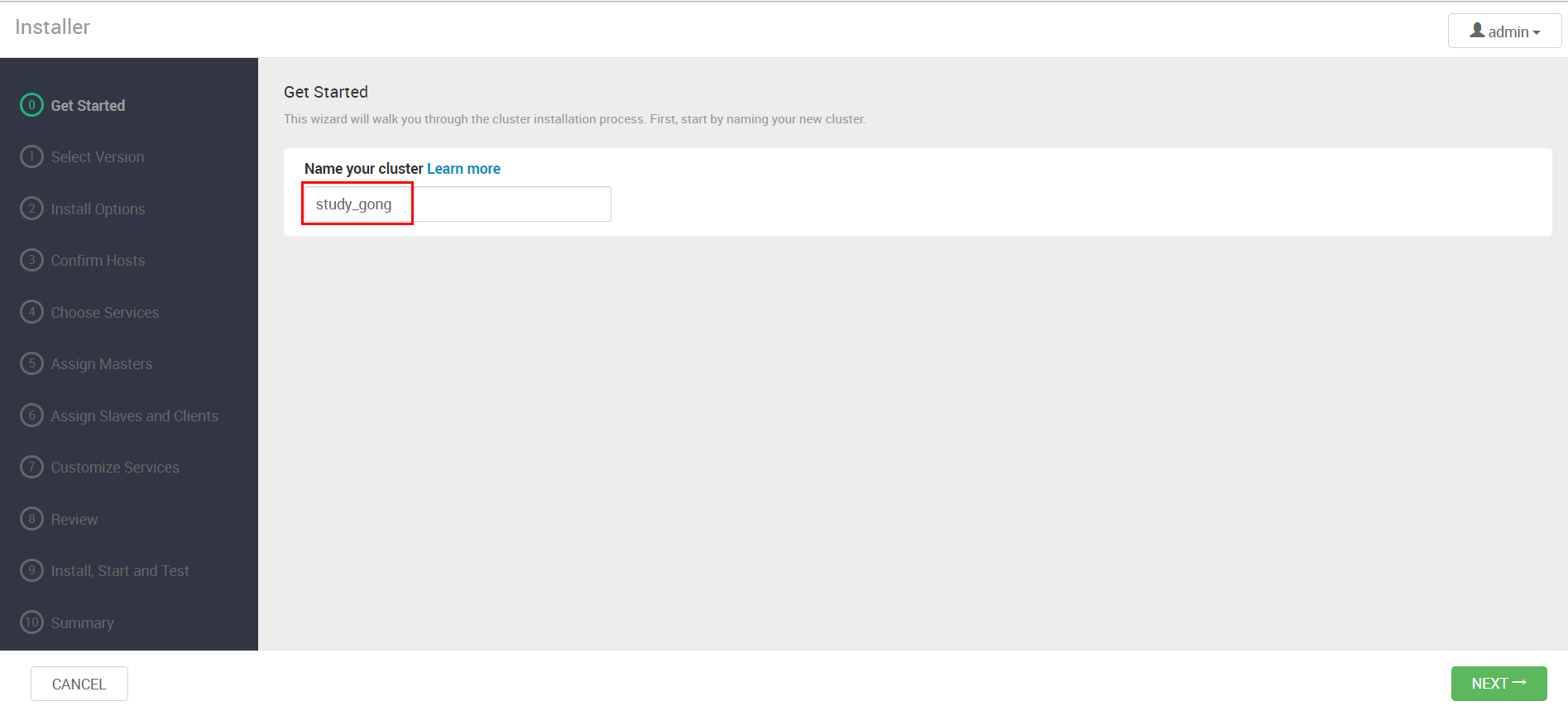
版本选择 
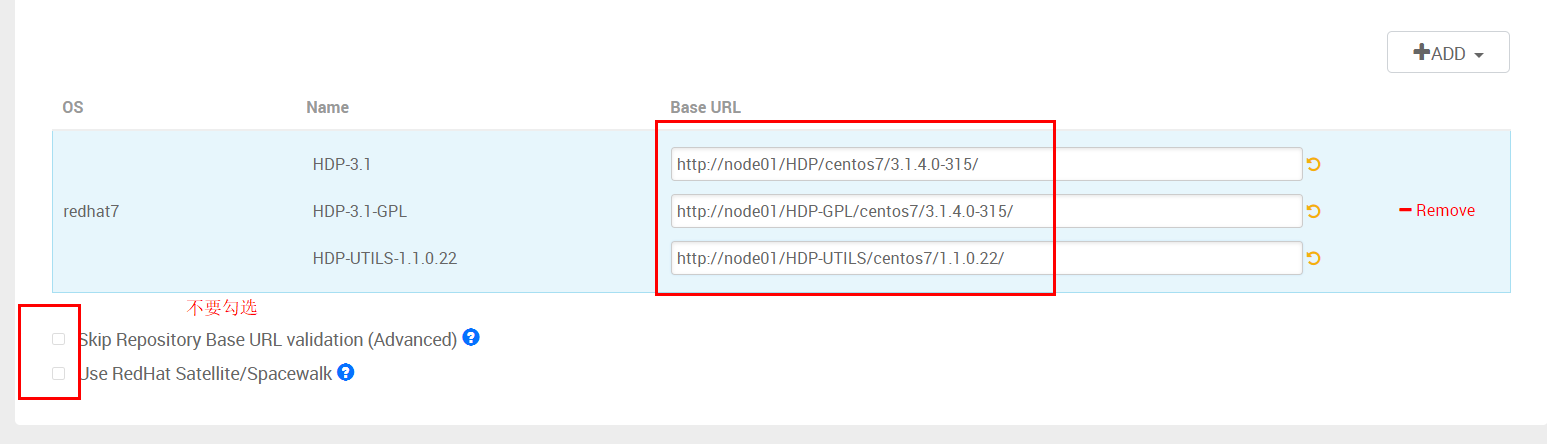
接着要把滚动条往下拉,把无用的其他操作系统的仓库删掉 
只保留redhat7,其他的都删除掉
最终我们只保留"readhat7"的仓库,接下来要把直接部署yum本地仓库的地址填进去,同时不要勾选下
面的两个高级选项
HDP-3.1 http://node01/HDP/centos7/3.1.4.0-315/
HDP-3.1-GPL http://node01/HDP-GPL/centos7/3.1.4.0-315/
HDP-UTILS-1.1.0.22 http://node01/HDP-UTILS/centos7/1.1.0.22/
我们按照下图所示注册主机到Ambari
把node01的私钥复制过来

上面的私钥要拷贝完整,一点也不能少,最后一行也不要换行。
点击右下角按钮开始注册,会弹出提示窗口,点击”CONTINUE“即可


自动开始注册

点击这里去查看一些警告

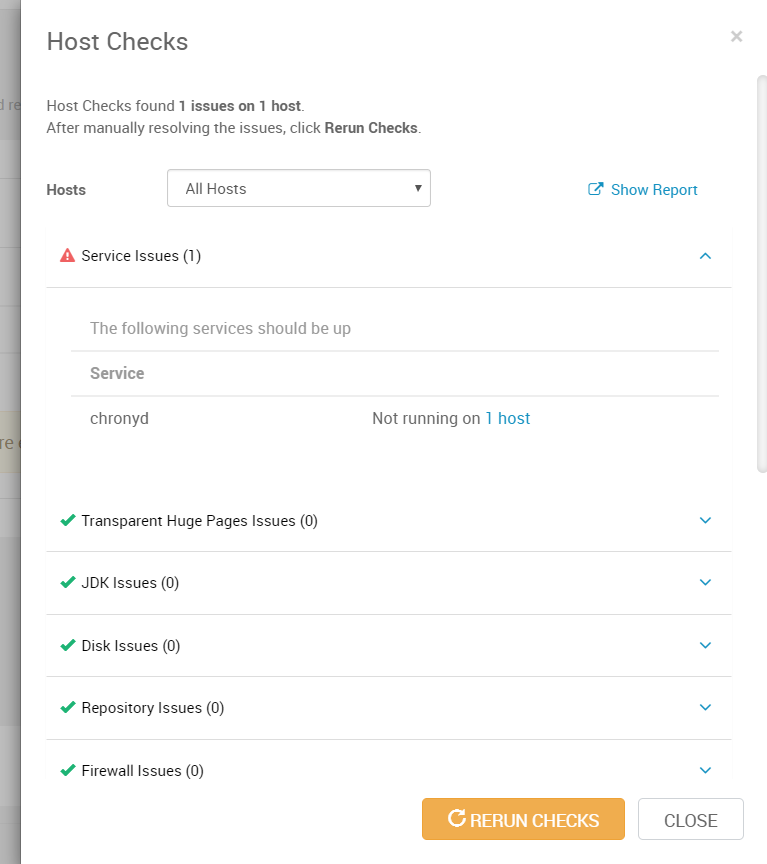
它这里就警告chronyd没有在1个节点上运行也就是没在node01上运行,chronyd是CentOS7默认的时
间同步服务(CentOS6的NTP),因为我们暂时一个节点无需时钟同步,所以不用管,直接点ClOSE。

然后直接点击右下角的”NEXT“,这时会弹出窗口,问你有警告是否忽略(chronyd的警告),我们选择”
OK“会自动进入下一步

选择要安装的服务
Amabri管大数据的各个组件叫做 Service,在这异步要选择同时安装的服务,当然我们也可以先不选后
面再选。
在这里我们选择安装下Hadoop相关的服务,其余的服务就取消掉对话框的对勾(它默认选了一堆,一定
要去掉,好多用不到)
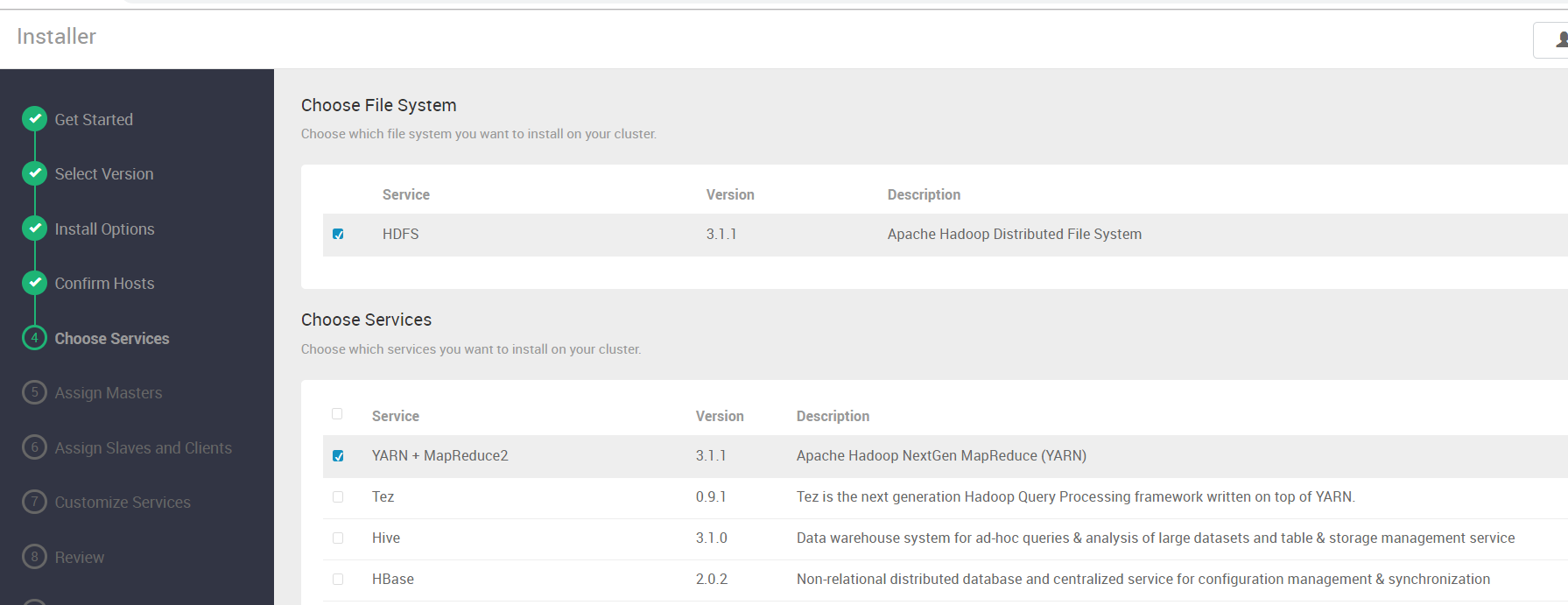

在这里要特别注意,在Ambari里Hadoop被当做多个服务例如HDFS、YARN等,如果你选择的服务依赖
于其他服务他会提示的,你点击确认后会自动勾选,然后下一步即可 。
分配Mater服务安装到哪些主机
接下来Ambari会让你选择Master服务要安装到哪些主机,所谓Master服务,是指的各个服务的Master
服务,例如HDFS的Master服务就是namenode,因为我们就一个节点,所以保持不动直接下一步

分配Slave服务和Client安装到哪些主机

接下来是一些自定义Service的配置,首先会让你设置一些服务的密码 ,为了方便,这里统一用admin

这里要注意,随着前面你选的Service的不同,这里也会不同,点击”next“会让你确认一些服务的目录,
我们先保持默认,直接”next“

然后是确认各个service运行在操作系统的哪个用户下,我们也保持默认
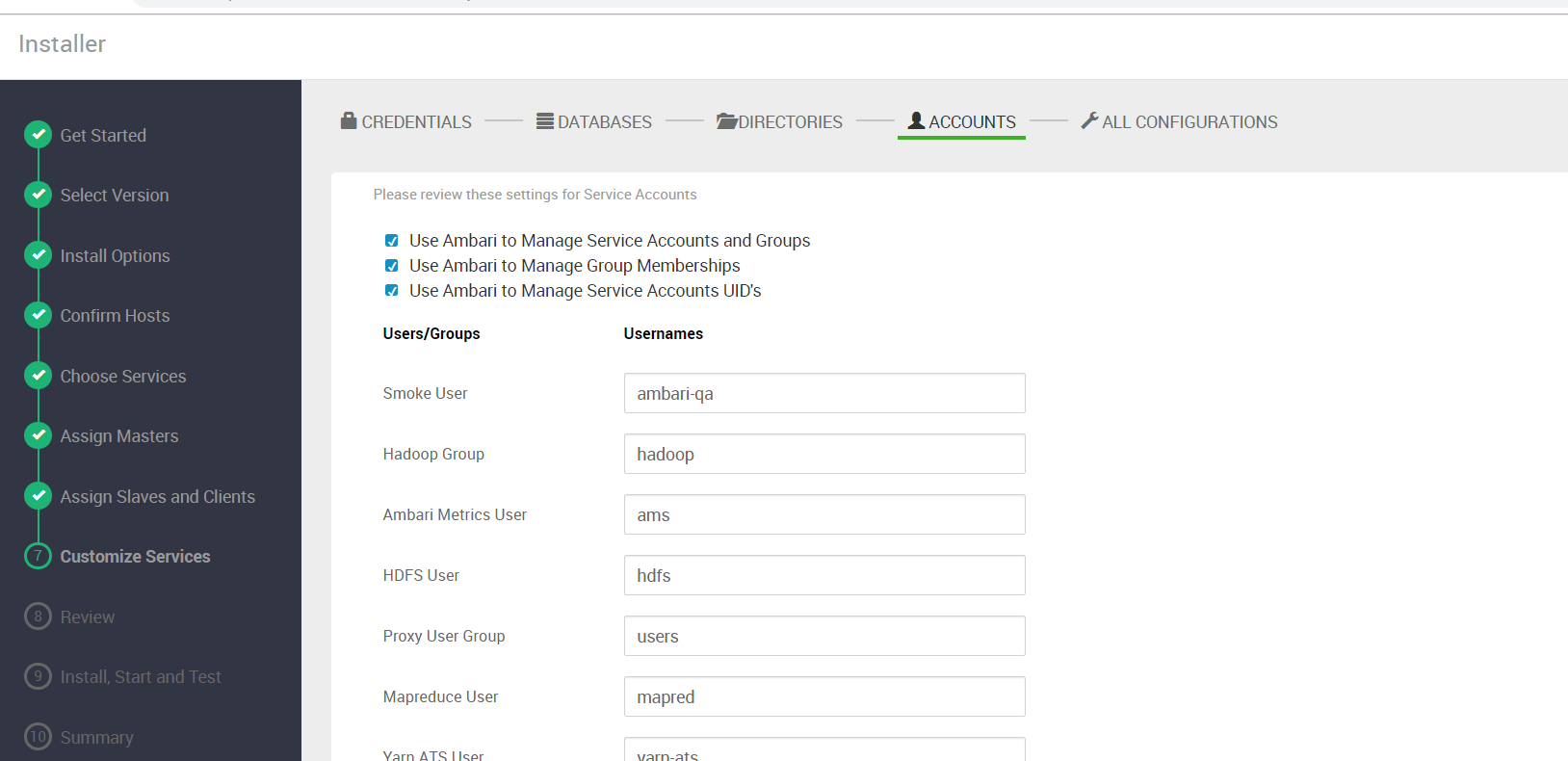
点击下一步,会让我们确认其他的配置,我们保持默认直接点NEXT

注意,这里随着你前面选择的service的不同会有很大差异,比如你要选择了了Hive,它一定会要你输入
MySQL相关信息,所以不要死记硬背 。
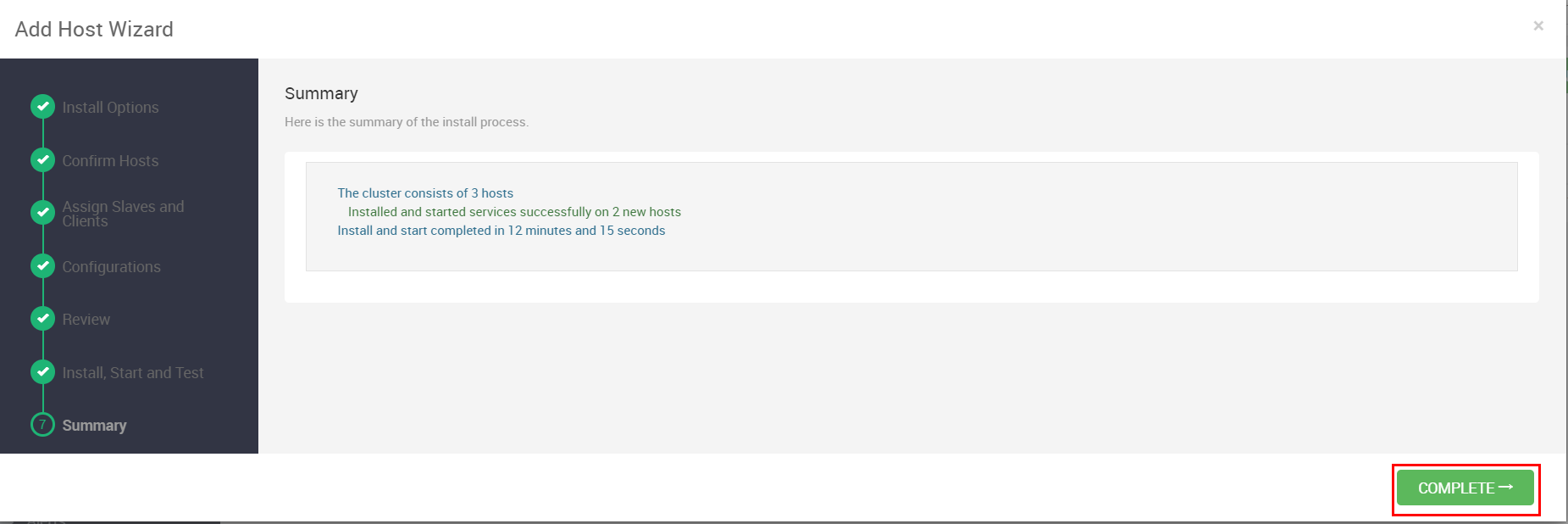
在Review环节我们要仔细检查之前的配置,没有问题就点击”DEPLOY“正式开始部署了
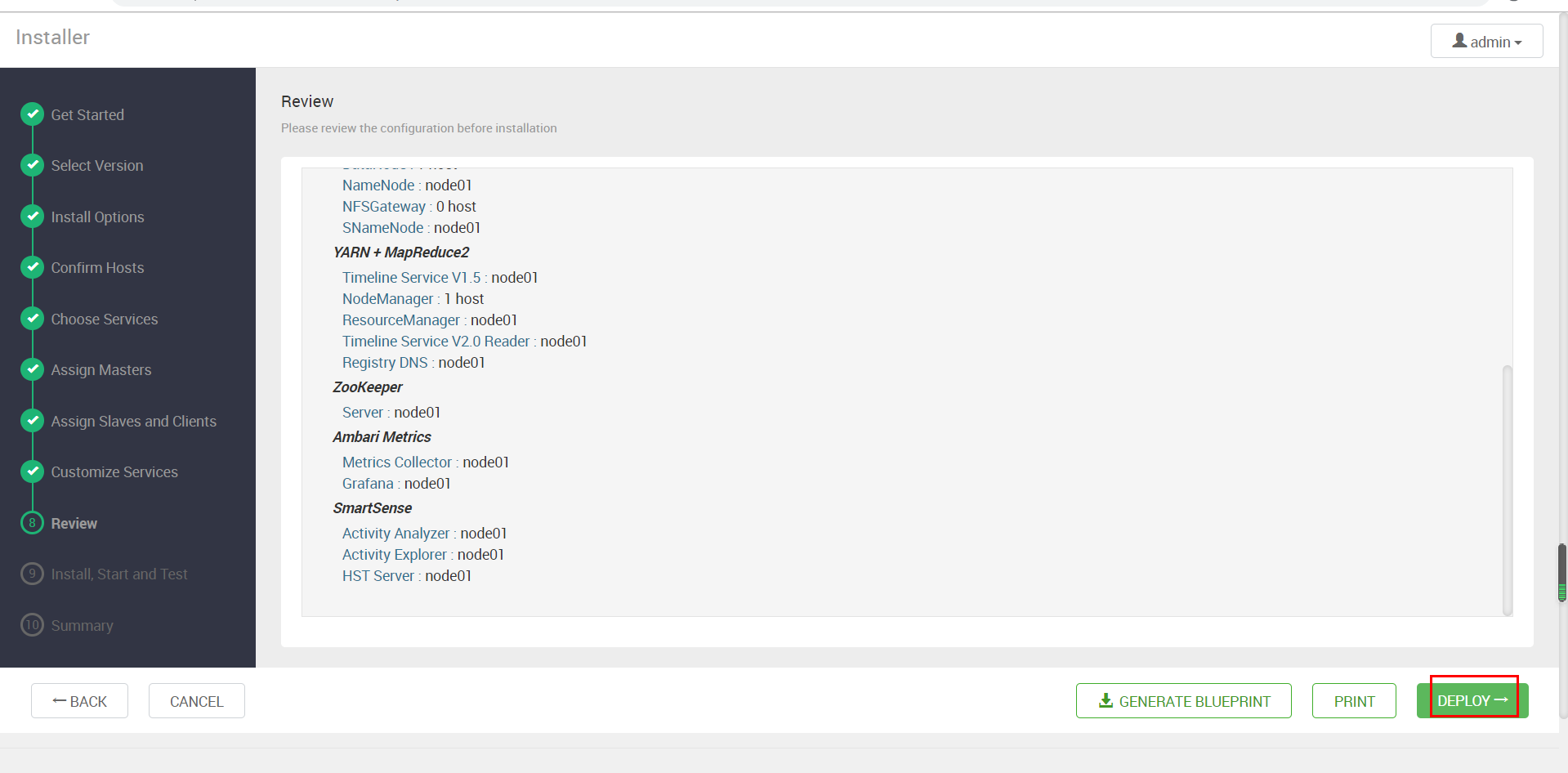
部署过程需要花较长时间,随时可以看到进度

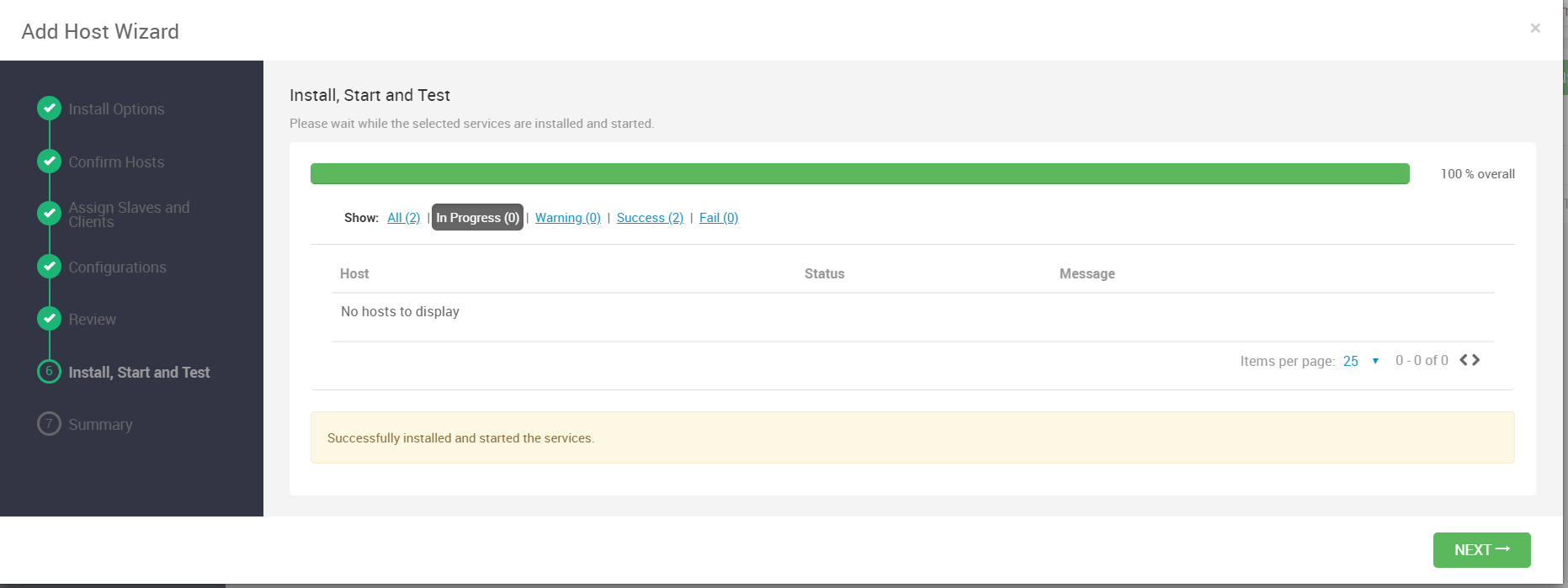
再部署完服务之后,Ambari会自动启动服务并进行冒烟测试,测试通过看到如下界面就代表成功安装
好了,点击”NEXT“即可


把这边的进程都每个手动启动一下,因为刚启动的时候有些警告
部署HBase
之前在不是Amabri集群的过程中安装了HDFS、YARN,包括Zookeeper集群,接下来我们通过增加服
务的方式安装下HBase 。
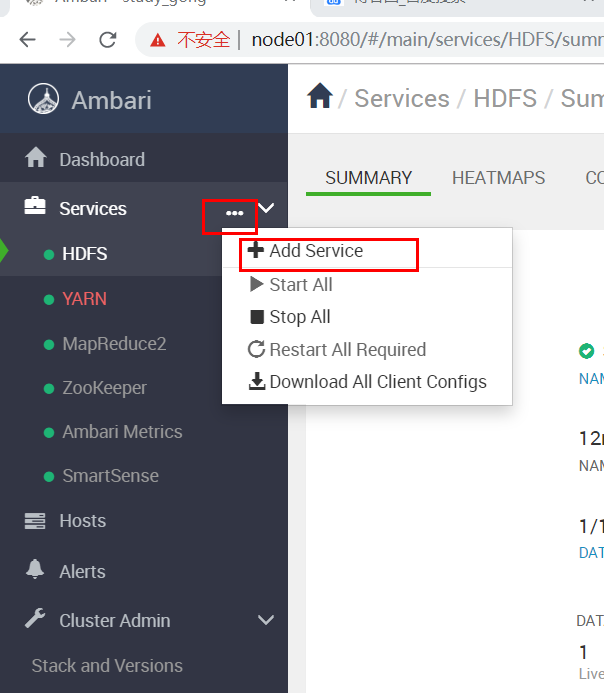
接下来的步骤就跟我们前面部署Ambari集群的方式稍微有点类似,首先要选择服务,这里我们当然选
择HBase然后后"NEXT"(当然也可以一次性选择多个Service一起部署)。

这一步不用动,因为就一个节点 ,直接next,

分配Slave服务和Client安装到哪些主机
这一步就勾选RegionServer和Client即可

自定义服务
这一步我们保持配置不变,点“next”


Review环节直接点“DEPLOY

部署启动与测试
整个安装过程会持续一段时间,在部署完服务之后,Ambari会自动启动服务并进行冒烟测试,测试通
过看到如下界面就代表成功安装好了,点击”NEXT“即可




部署Hive
Hive的部署过程跟HBase基本一样,其他服务亦如此,不过Hive的元数据一般选择存放在MySQL,所
以我们要在MySQL里单独为Hive创建用户和库以便于管理
在node01上,进入MySQL
set global validate_password_policy=0;
set global validate_password_mixed_case_count=0;
set global validate_password_number_count=3;
set global validate_password_special_char_count=0;
set global validate_password_length=3;
create database hive;
CREATE USER 'hive'@'%' IDENTIFIED BY 'hive';
GRANT ALL ON hive.* TO 'hive'@'%';
FLUSH PRIVILEGES;
exit

告诉Hive组件MySQL驱动在哪里
sudo ambari-server setup --jdbc-db=mysql --jdbc-driver=/usr/share/java/mysql-connector-java-8.0.18.jar

在Ambari主界面按照下图操作启动安装向导

这里我们选择Hive然后后"NEXT"
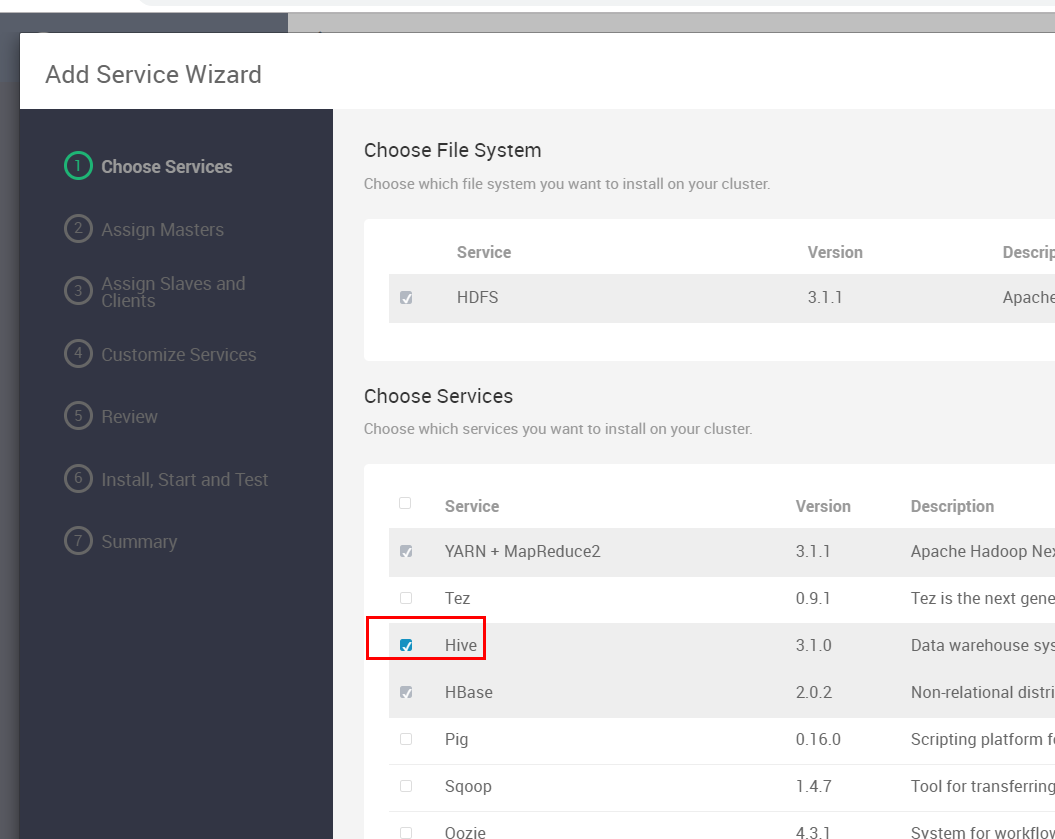

这一步不用动,因为就一个节点
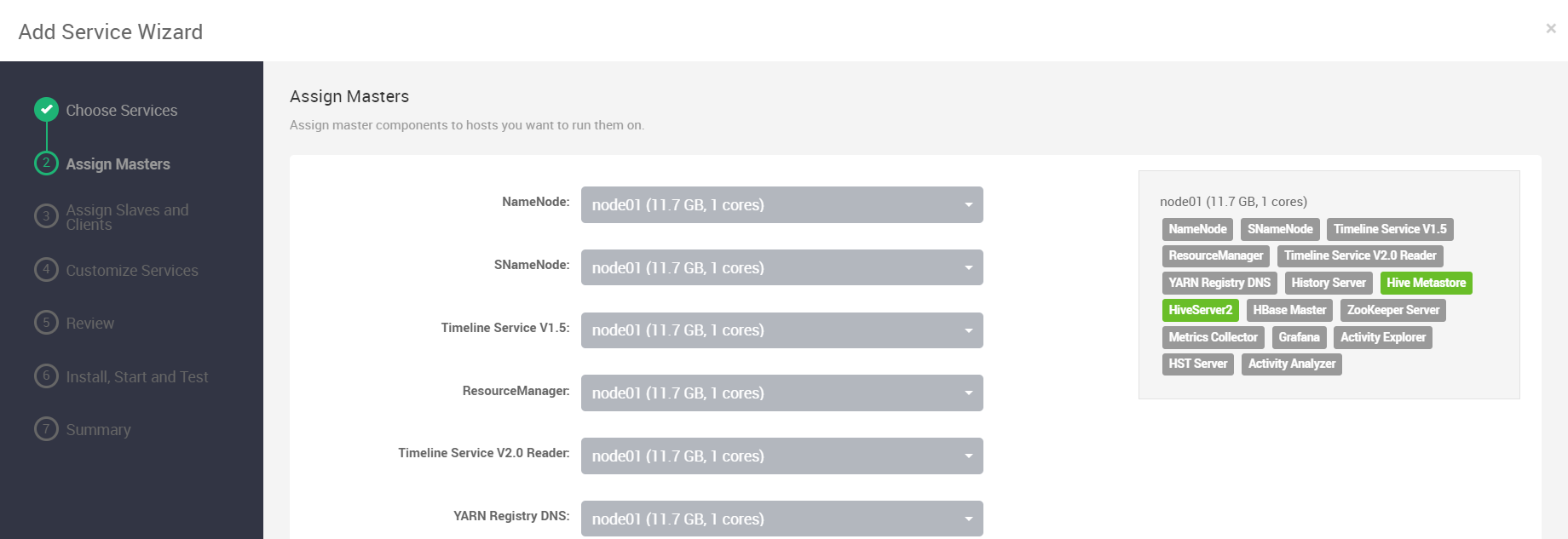
这一步就勾选Client即可:
自定义服务
这一步我们保持配置不变,除了hive,我们能看到如下图的提示

我们点击“HIVE”选项卡切换到Hive配置页

在Hive配置页,我们要切换到DATABASE子选项卡,然后往下滚动页面去配置数据库的信息,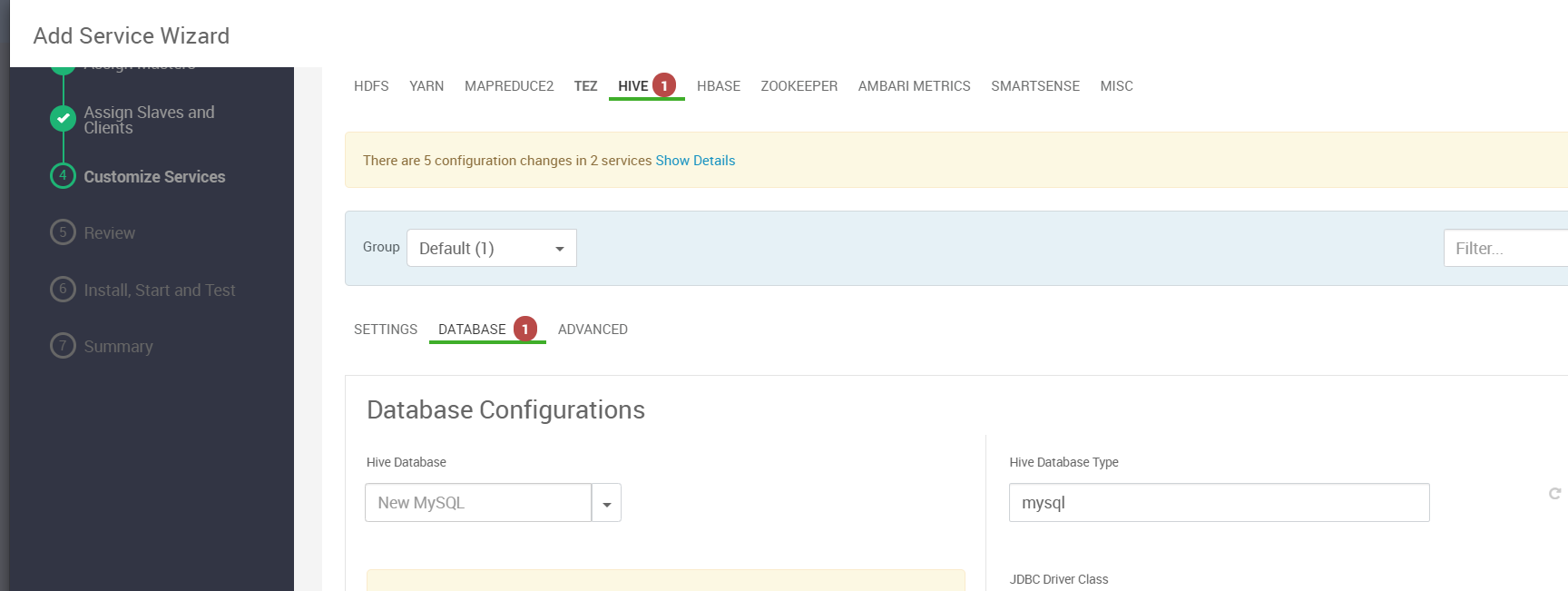

测试连接




部署启动与测试
整个安装过程会持续一段时间,在部署完服务之后,Ambari会自动启动服务并进行冒烟测试,测试通
过看到如下界面就代表成功安装好了,点击”NEXT“即可
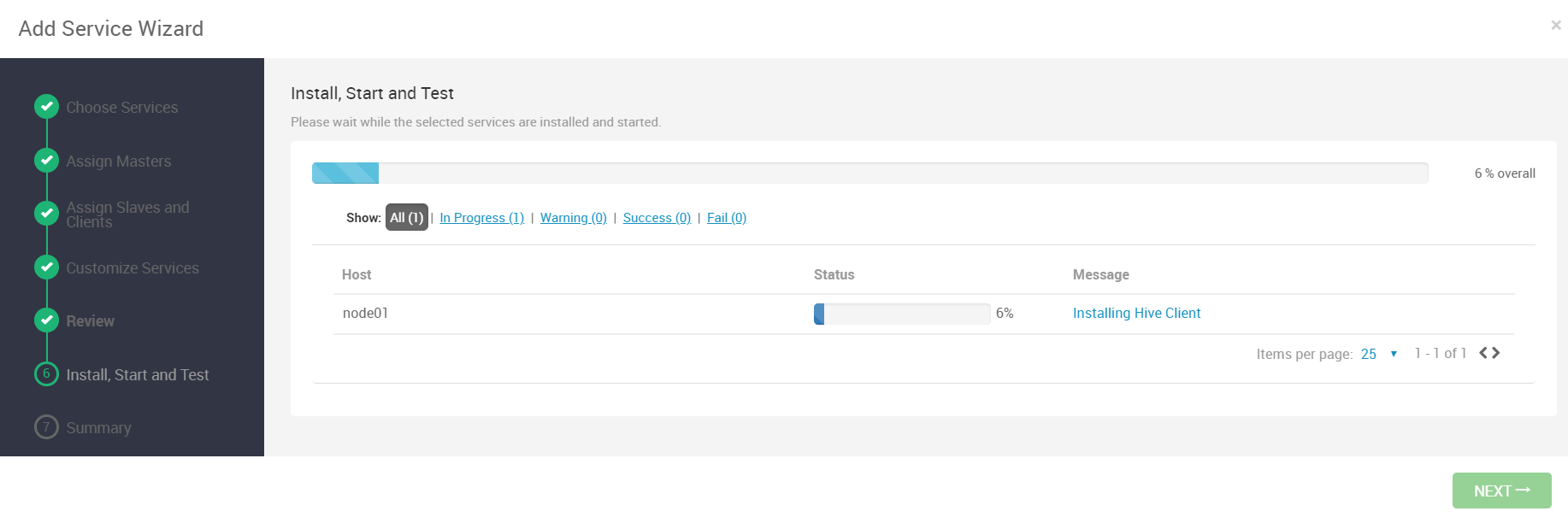

在Ambari界面我们发现因为安装Hive,后台自动更新了一些服务的配置,因此需要重启


如果重启所有服务不行,可以一个个手动重启的,我就是遇到这样的问题,我自己一个个服务手动重启了

Service自动启动
有时候我们希望托管给Ambari的服务可以自动启动

扩容到3个节点
在node02的基础上我们再复制出一个节点node03




注意:千万不要从node01复制,那样会特别大而且里面有Ambari
节点网络配置
配置node02的静态ip

配置node03的静态ip

修改完了分别重启node02和node03的网络
sudo systemctl restart network
配置node02和node03的主机名
由于是克隆过来的,主机名还是node01,因此我们需要修改
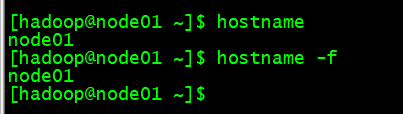
永久修改hostname执行如下命令:
sudo vim /etc/hostname
分别输入node02 node03
配置hosts文件
sudo vi /etc/hosts


node02和node03防火墙设置
分别进行以下操作
#禁止防火墙开机启动
sudo systemctl disable firewalld
#关闭防火墙
sudo systemctl stop firewalld
#查看防火墙状态
sudo systemctl status firewalld
禁用node02和node03 SELinux
分别操作
临时禁用 sudo setenforce 0
sudo vi /etc/selinux/config
将SELINUX=enforcing改为 SELINUX=disabled:
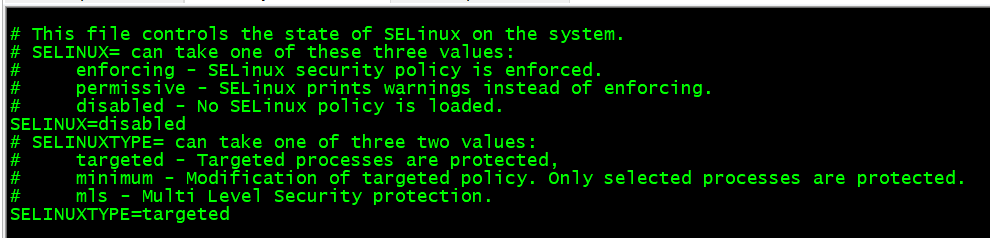
分别重启node02和node03
重启后,在三台机器都配置hosts文件

配置三台机器的SSH免密
先把node02和node03用户主目录下的隐藏文件夹.ssh删掉,这个是复制虚拟机过来


然后分别在node02和node03重新生成
ssh-keygen cd .ssh cat id_rsa.pub >> authorized_keys chmod 700 ~/.ssh chmod 600 ~/.ssh/authorized_keys


免密
我们所谓的免密就是拿集群中的一台机器作为管理节点,让那后让他可以ssh免密码到其他节点执行命
令,这对我们维护一个多节点的集群非常有意义。我们当然以node01为管理节点,所以要实现node01
到其他节点的免密
拿到node01的公钥
cat ~/.ssh/id_rsa.pub

把node01的公钥添加到node02和node03的
vi authorized_keys
添加到node02的公钥

添加到node03的公钥

然后node01分别到node02和node03 ssh连接一次
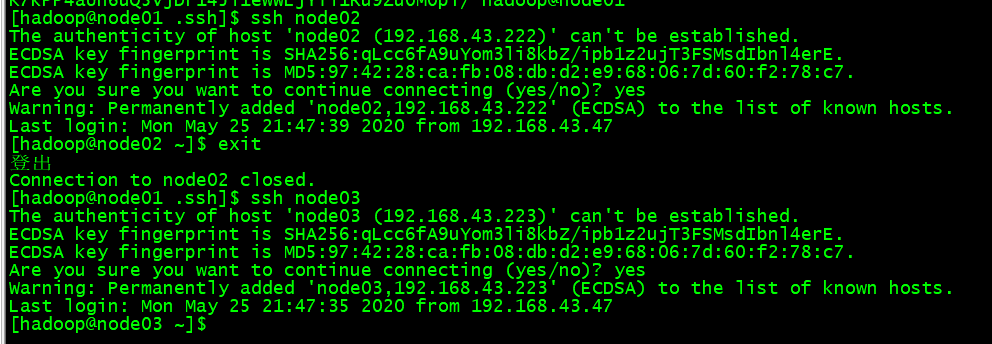
因为我们需要三个节点都能相互ssh通讯的,因此我们把每个节点的公钥都相互交换
每个节点的公钥都赋值

时钟同步
在三个节点分别执行
sudo ntpdate pool.ntp.org
纳入Ambari管理
这一步我们要先把新节点node02-node03纳入到Amabri进行管理


接下来进开始在新加的节点上自动安装ambari-agent了,安装完毕之后点下一步
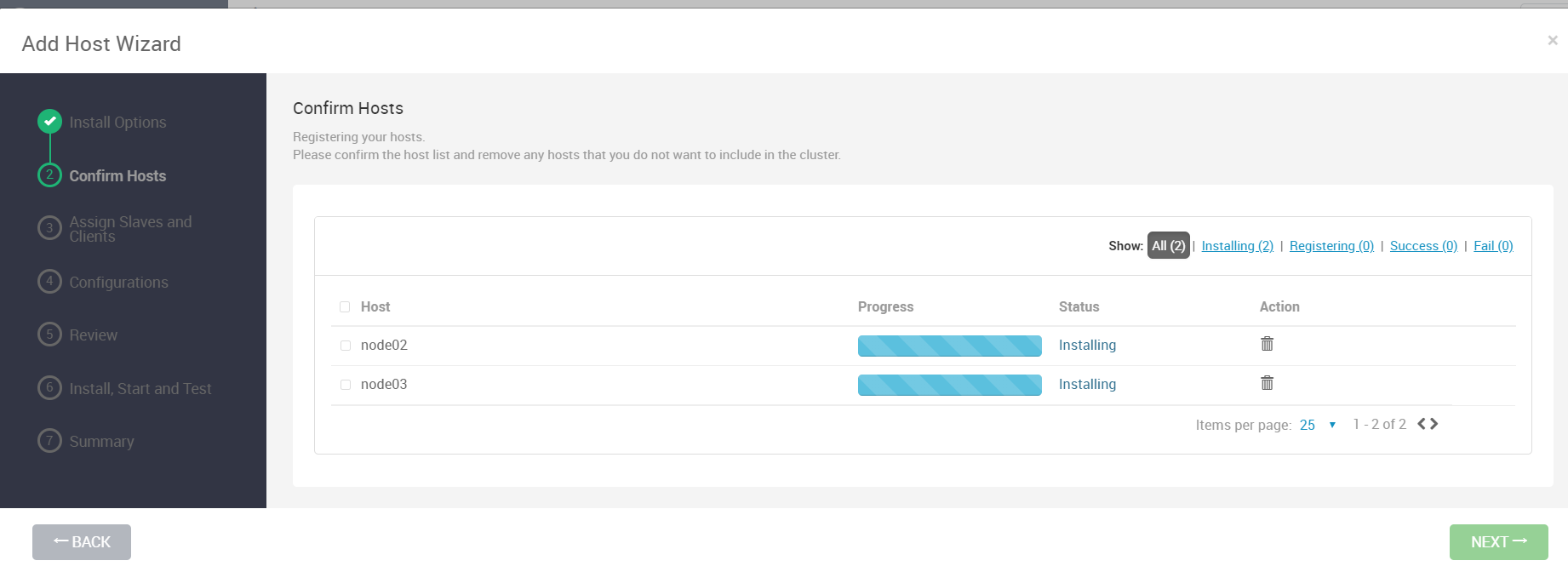


配置保持默认