HBase是什么

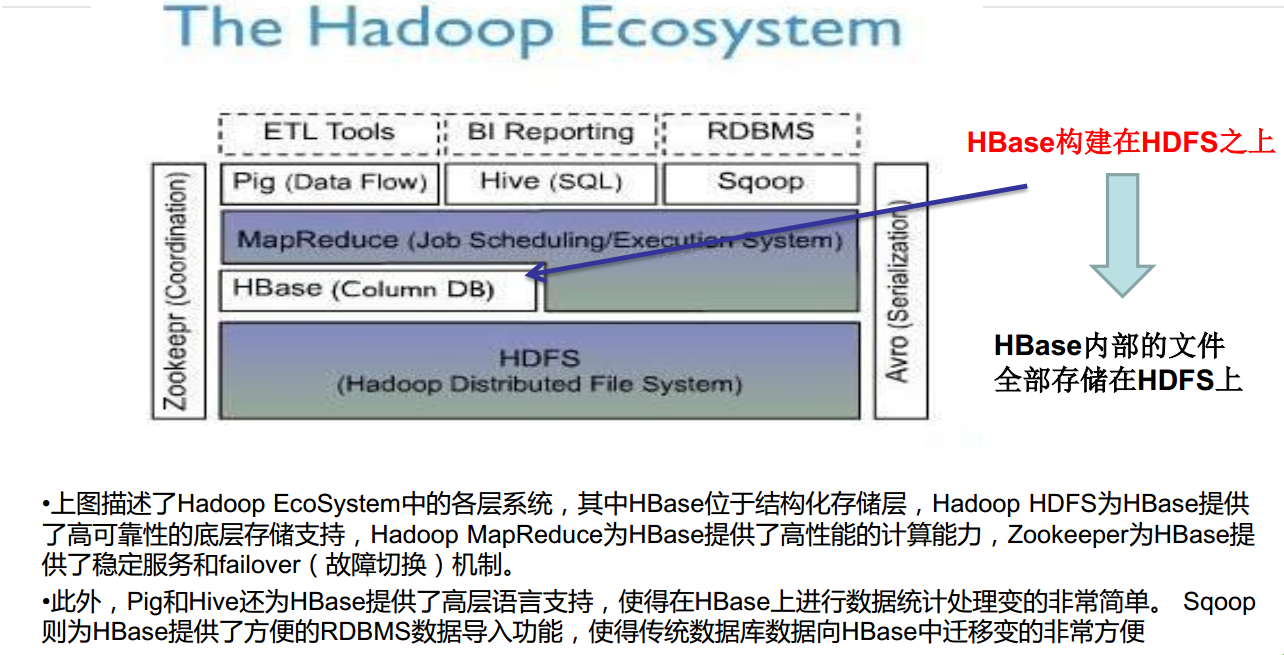
HBase在生态体系中的位置
HBase vs HDFS

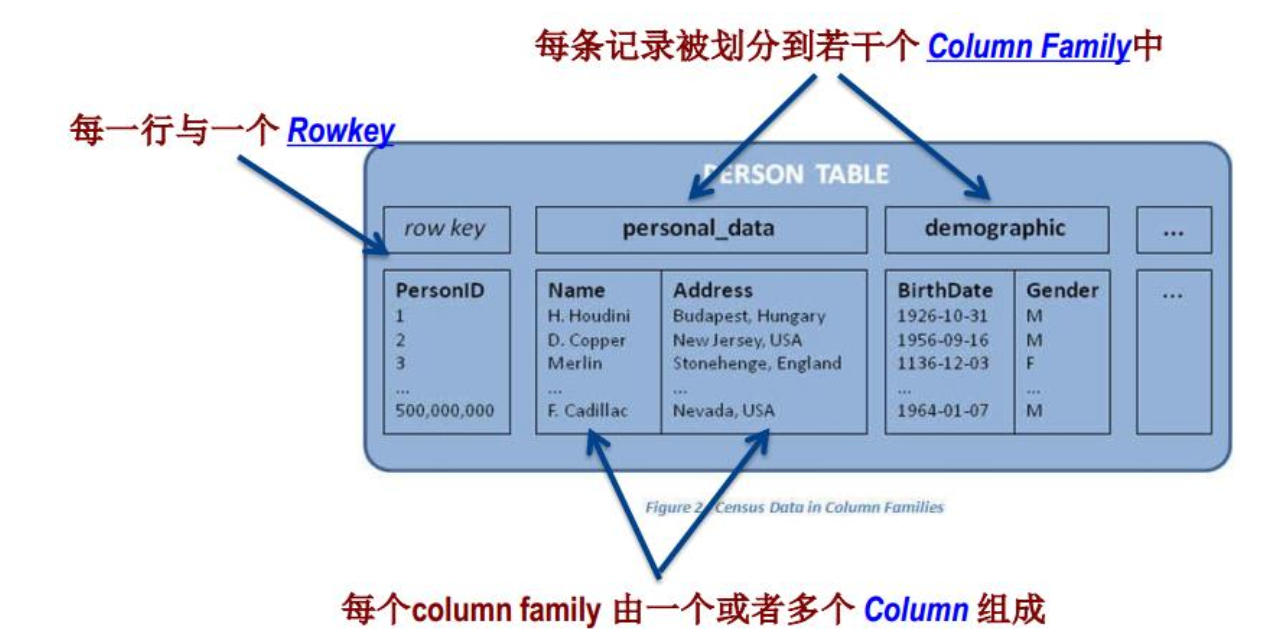
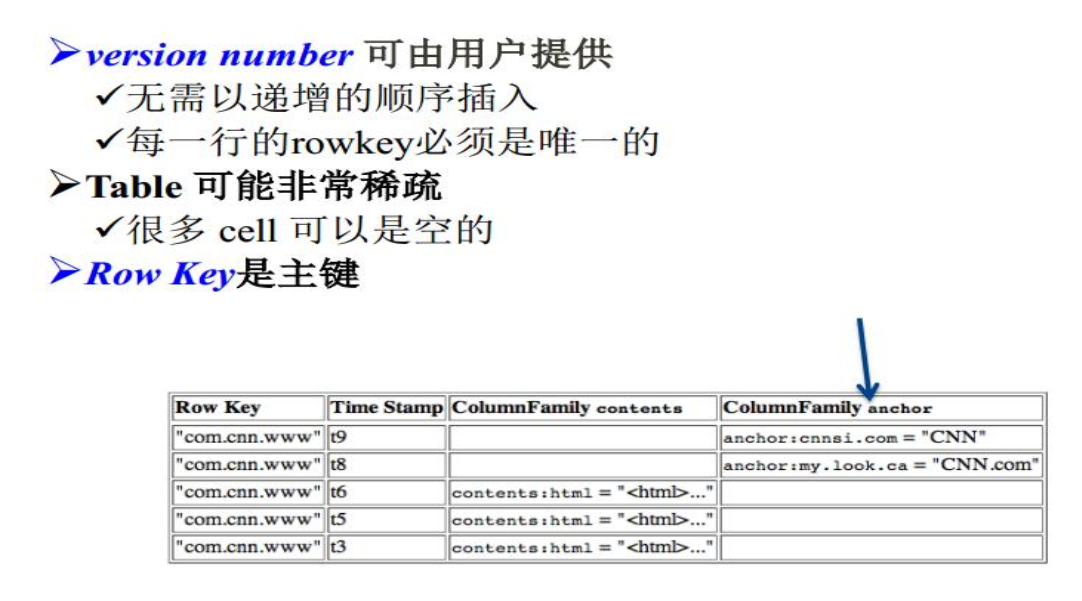
HBase表的特点

HBase是真正的分布式存储,存储级别达到TB级别,而才传统数据库就不是真正的分布式了,传统数据库在底层,虽然的存储能力很强,一旦达到上亿条数据。读取性能下降得很快。
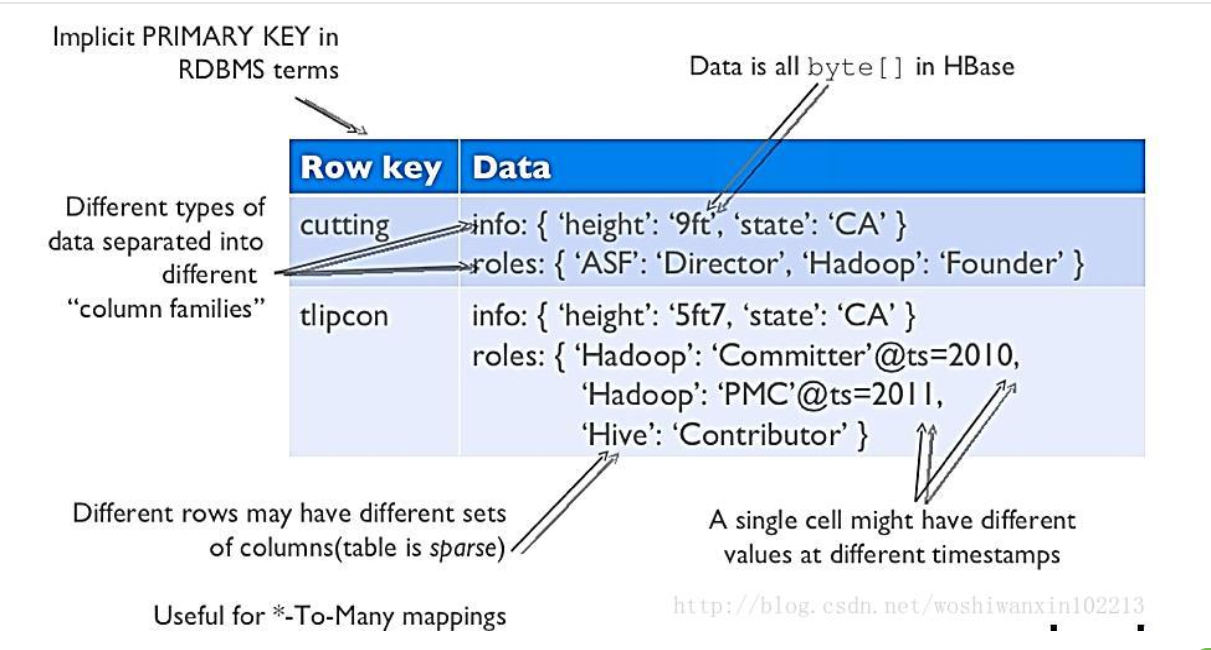
传统数据库按行存储,如果列过多的话,一行数据会非常大,HBase按列簇存储,每个列簇都存储一个文件,如果只读取某一些字段的话,只需读取对应的文件就可以了,其他的不用扫描,节省了IO。
HBase的存储每一行的内容可以不同,空出来的列不占用空间。
多版本,怎么理解呢,就比如说相同id的行重新插入数据不会覆盖掉,而是按照插入的时间戳分类。
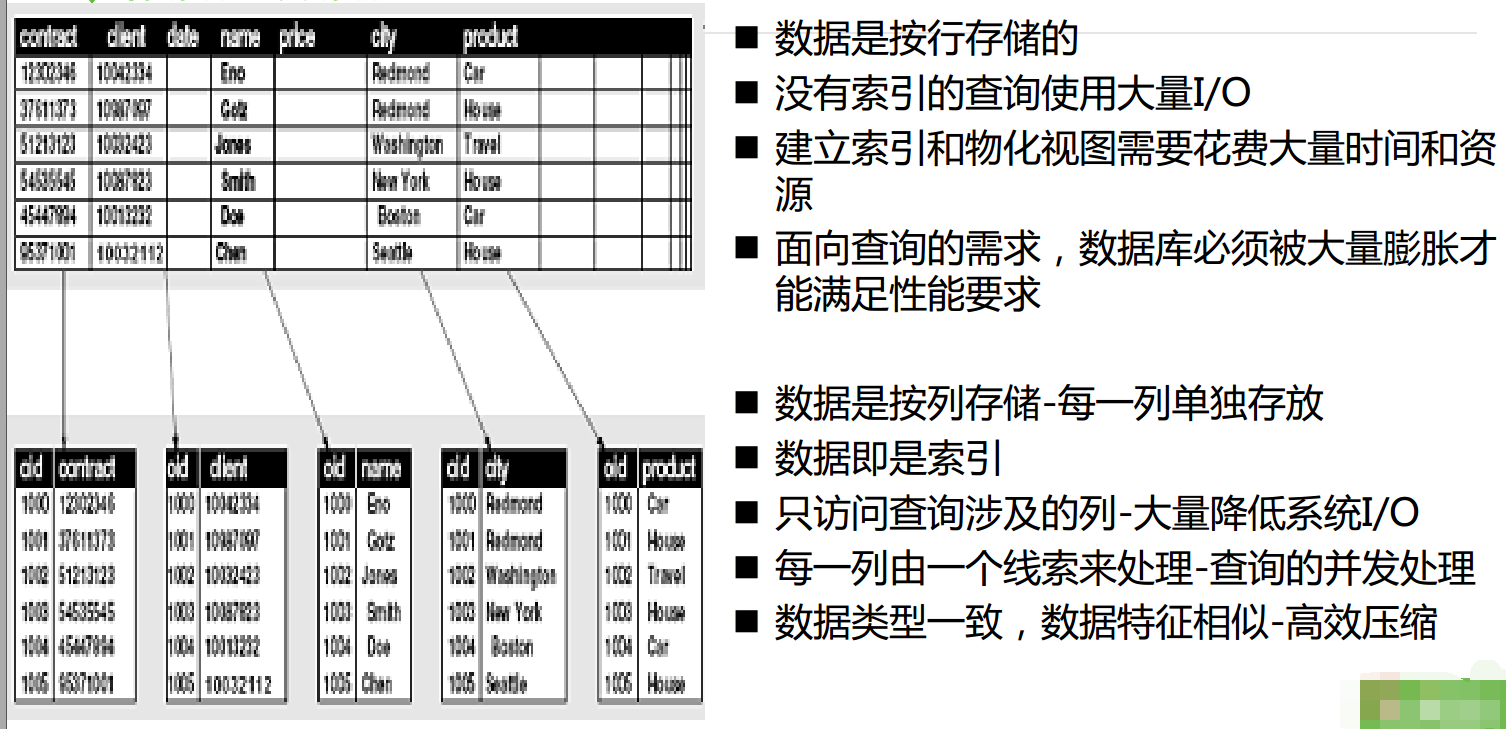
行存储和列存储
02 HBase数据模型
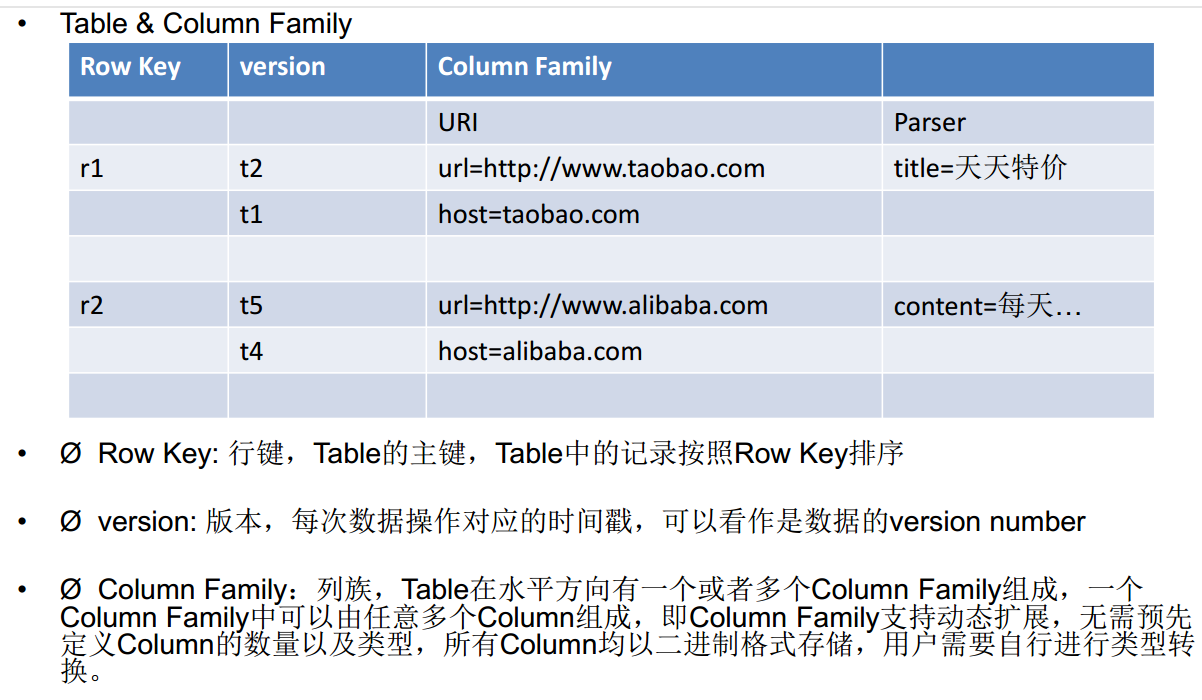
HBase逻辑视图
Rowkey和Column Family
HBase数据模型

HBase支持的操作

03 HBase物理模型

传统数据库和HBase的存储的不同


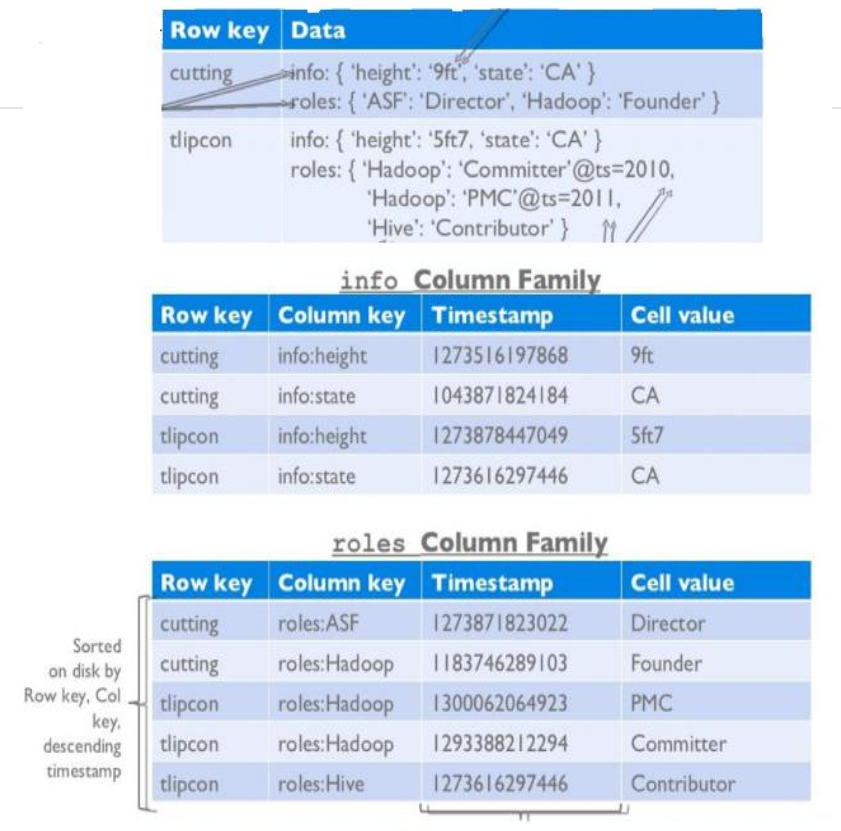
物理存储
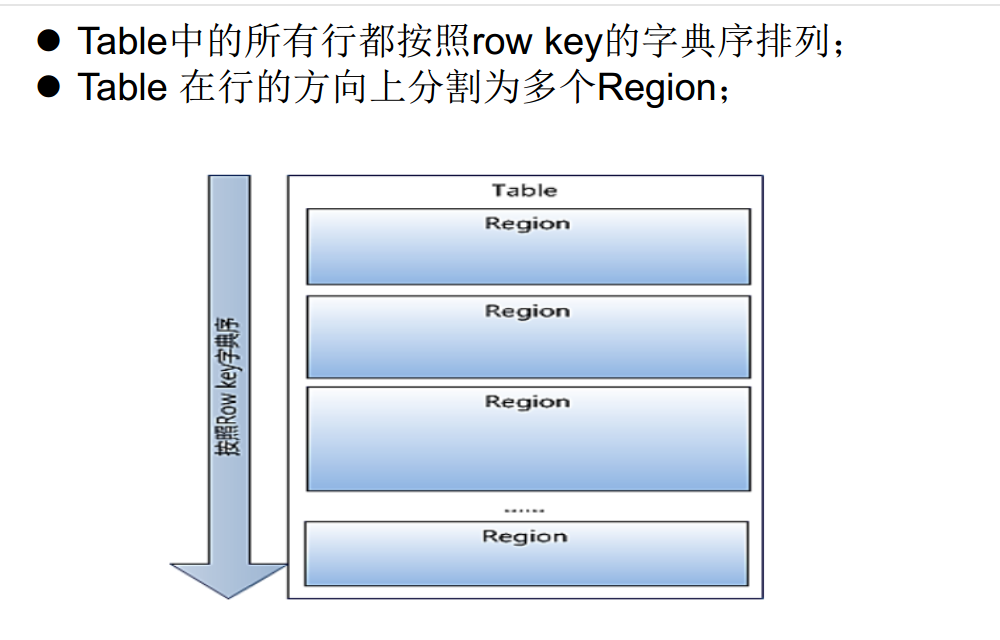
Table vs Region
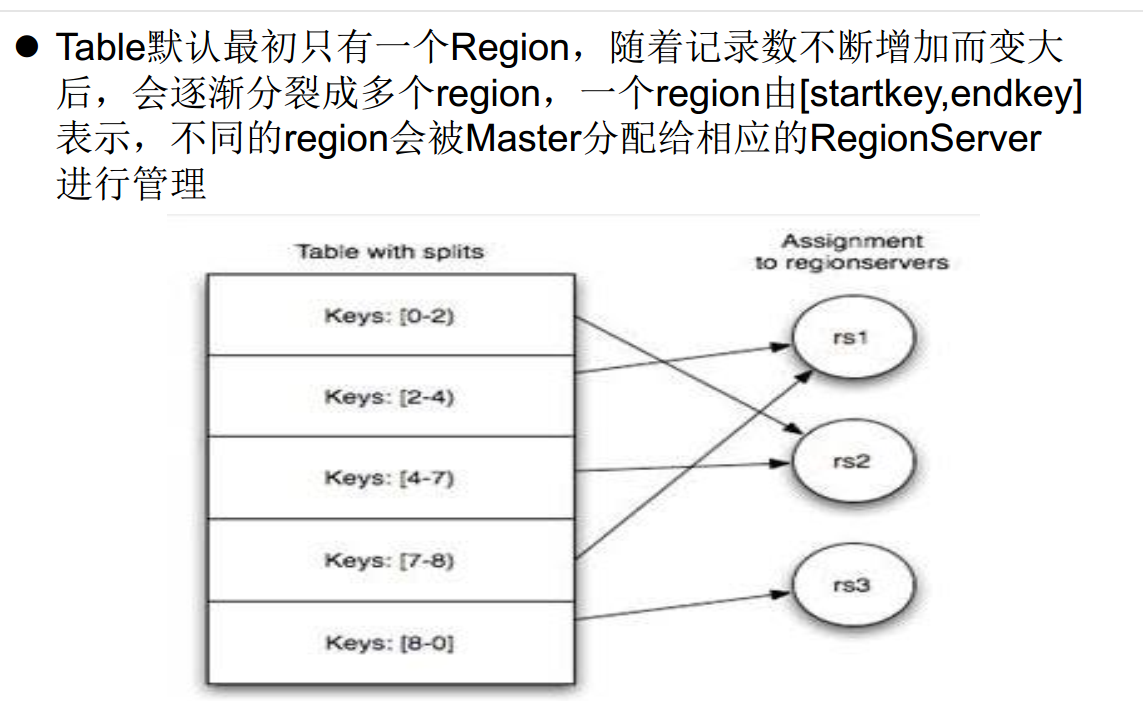
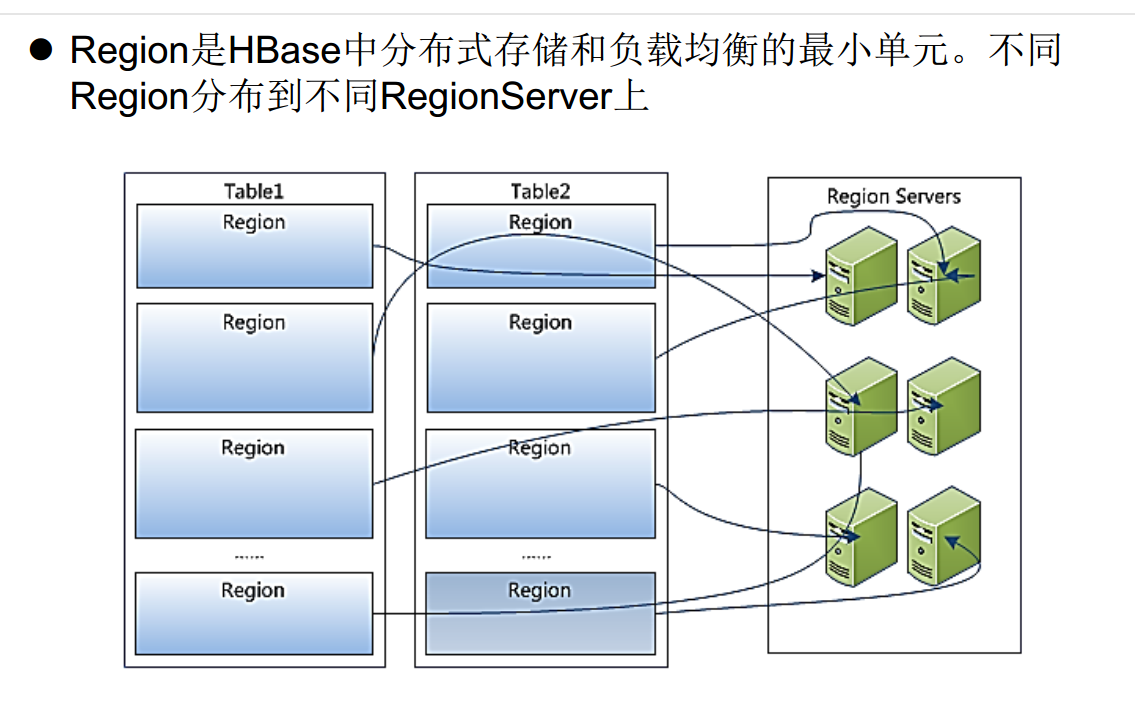
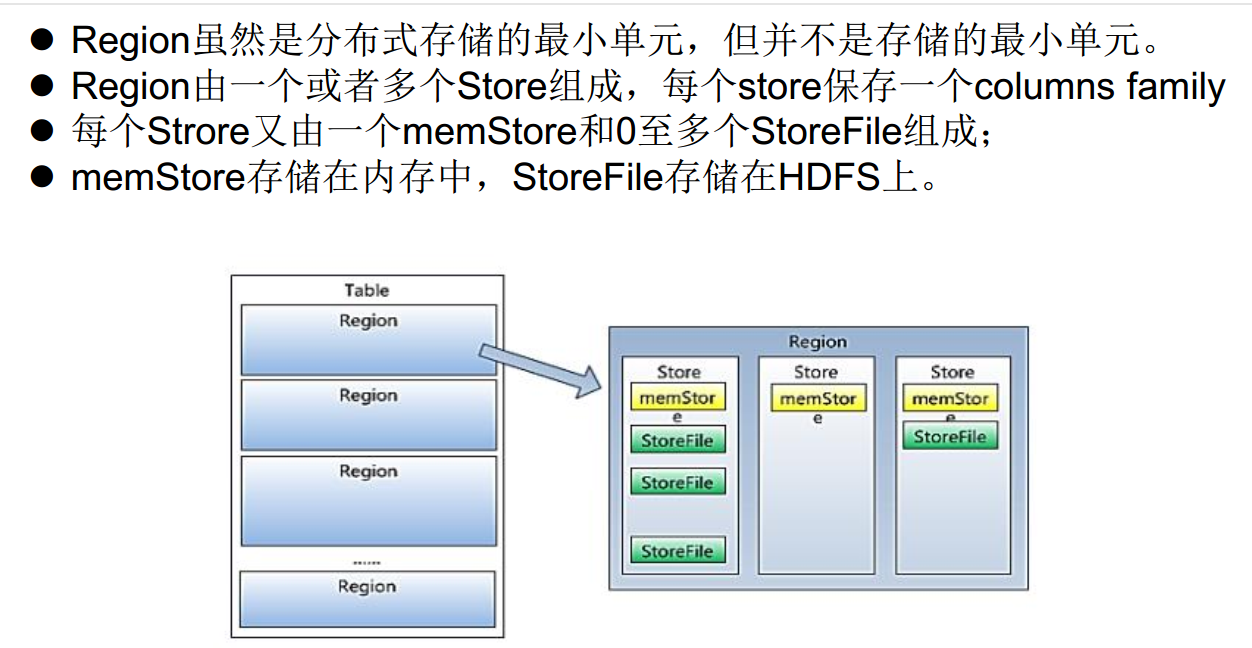
04 HBase系统架构
架构图
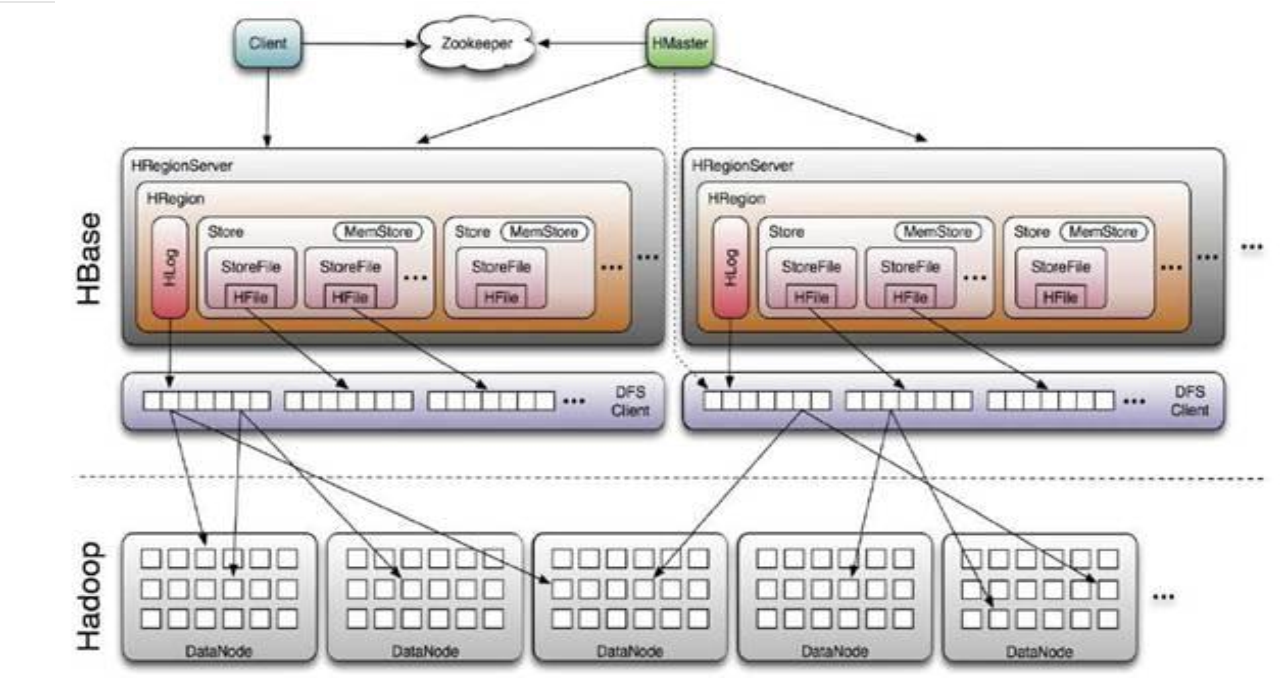
HBase基本组件

HBase工作流程

Hbase Write-Ahead-Log(预先写日志)
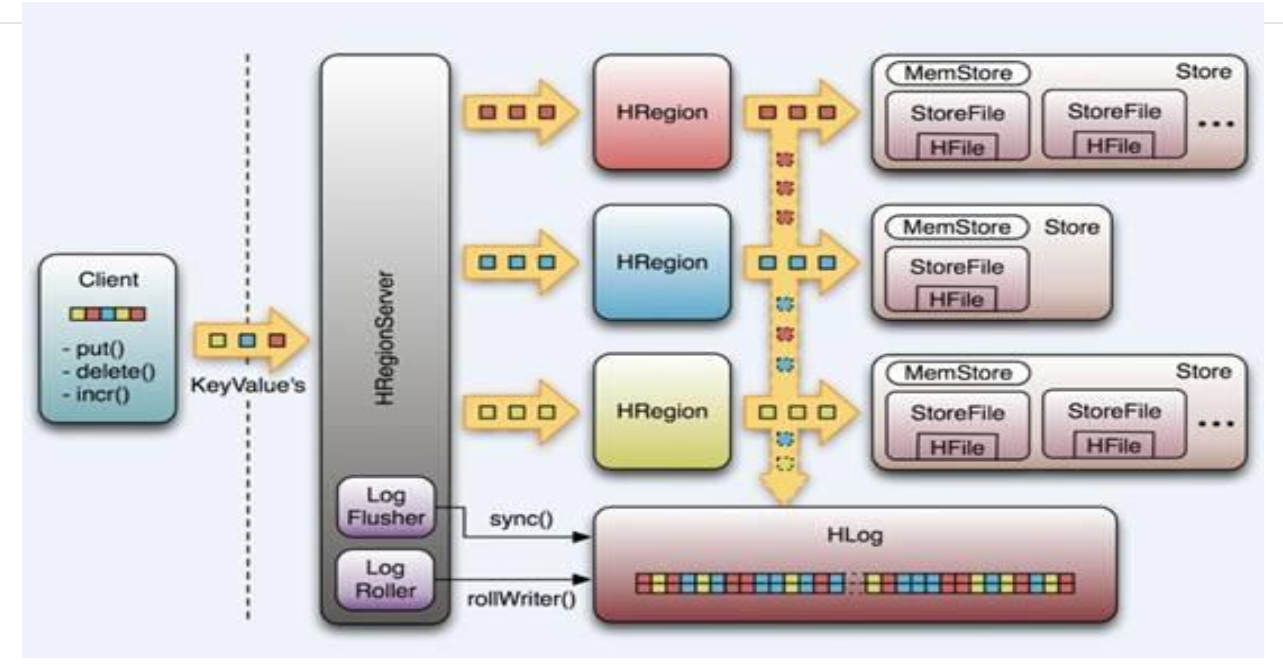
Regionserver结构

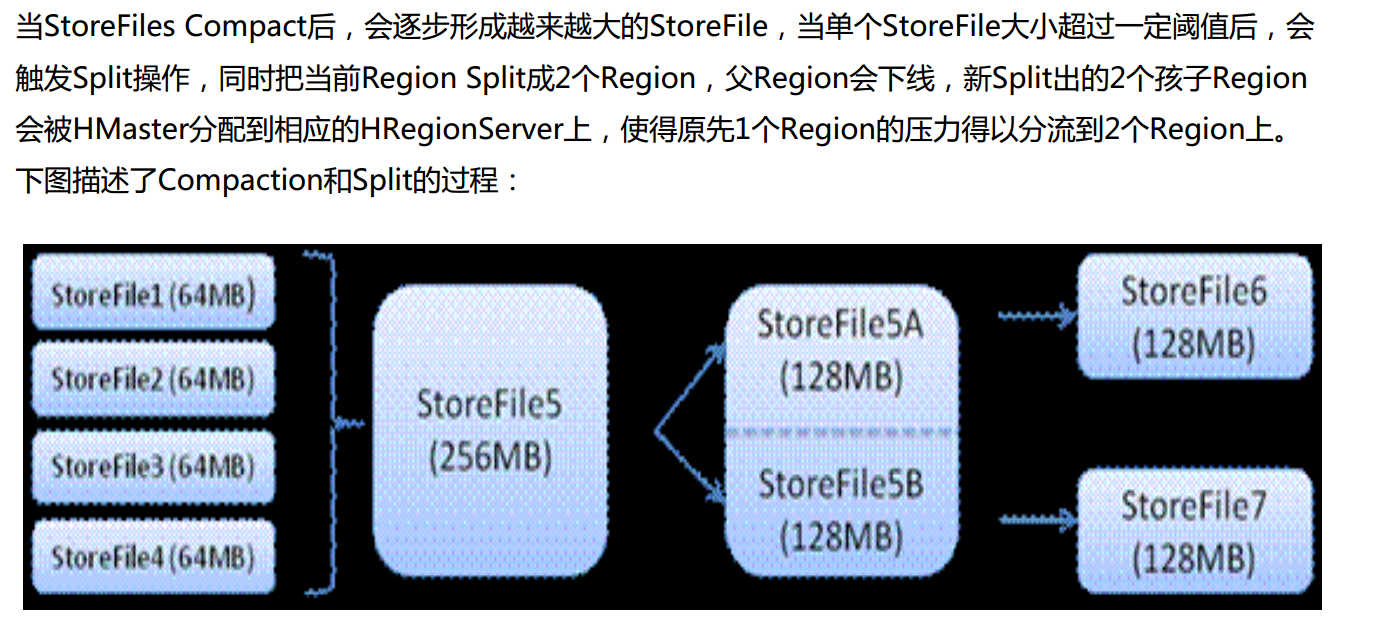
HBase Compact && Split
HLog Replay

Hfile存储格式
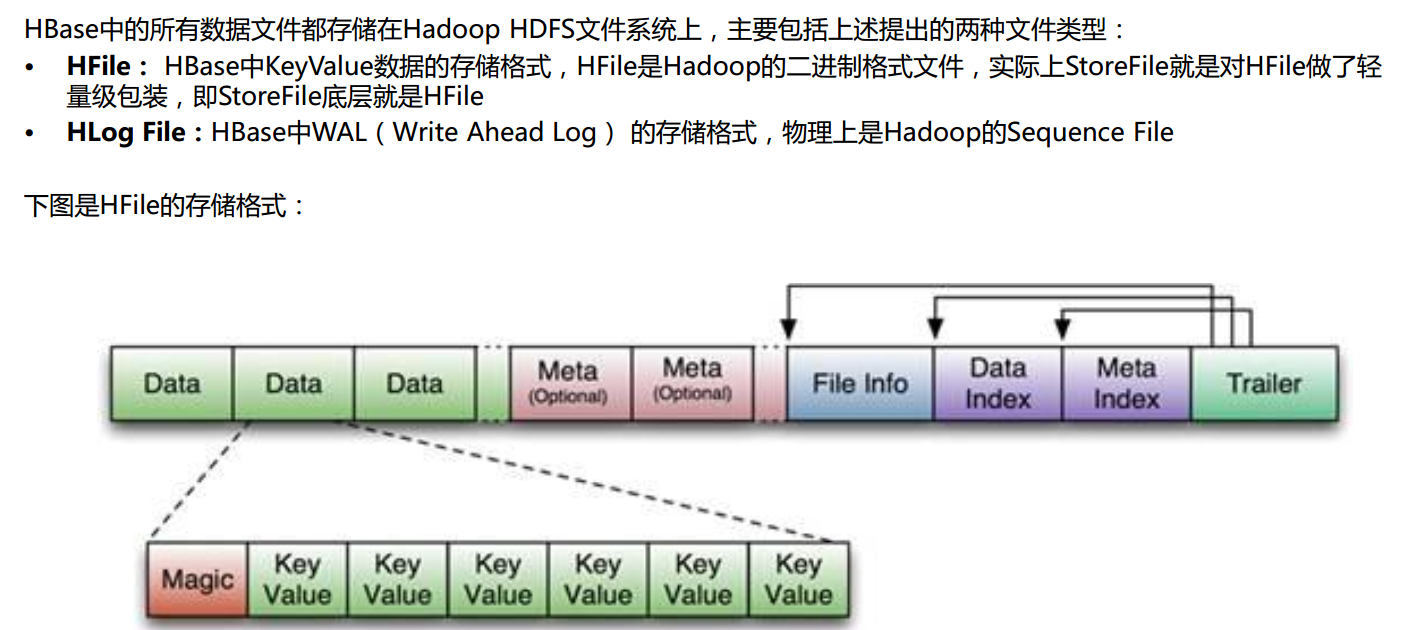
Hfile存储格式(续)

Keyvalue格式

Hlog存储格式
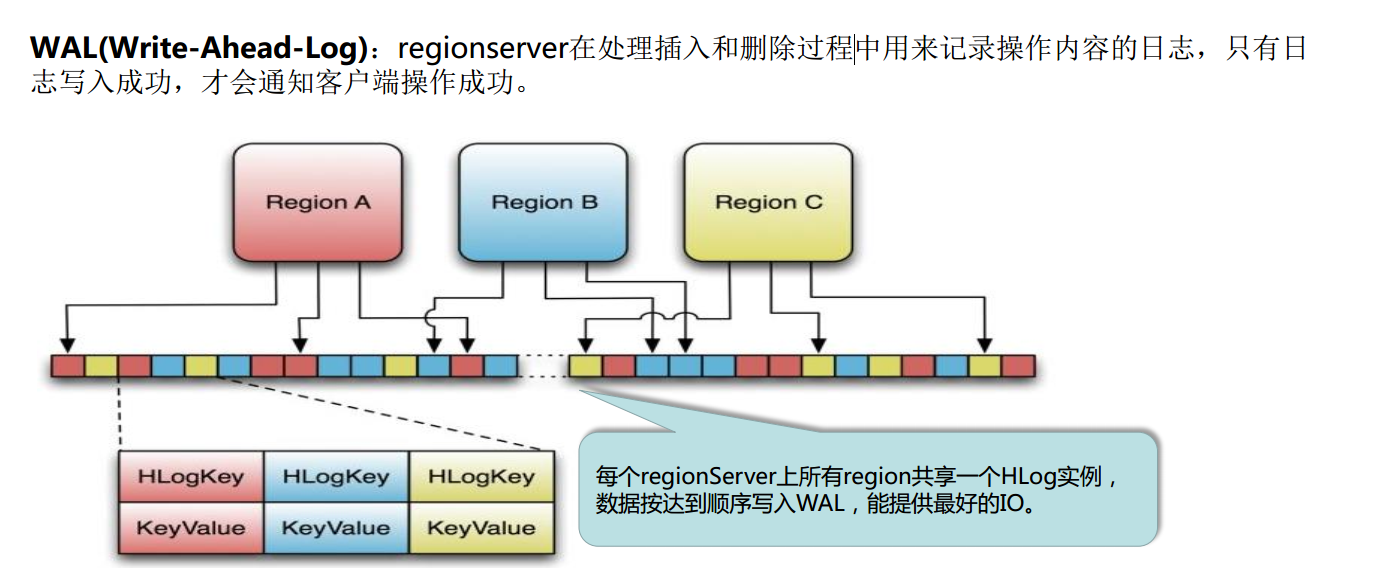
HLog存储格式(续)

HBase高可用
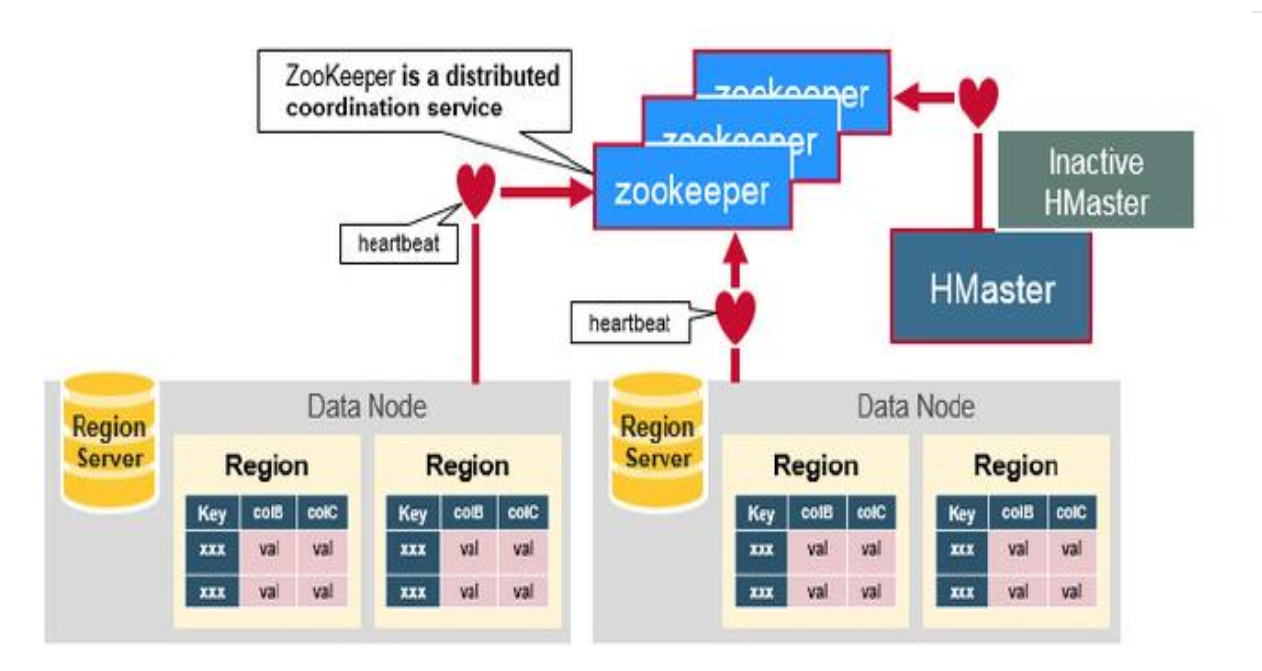
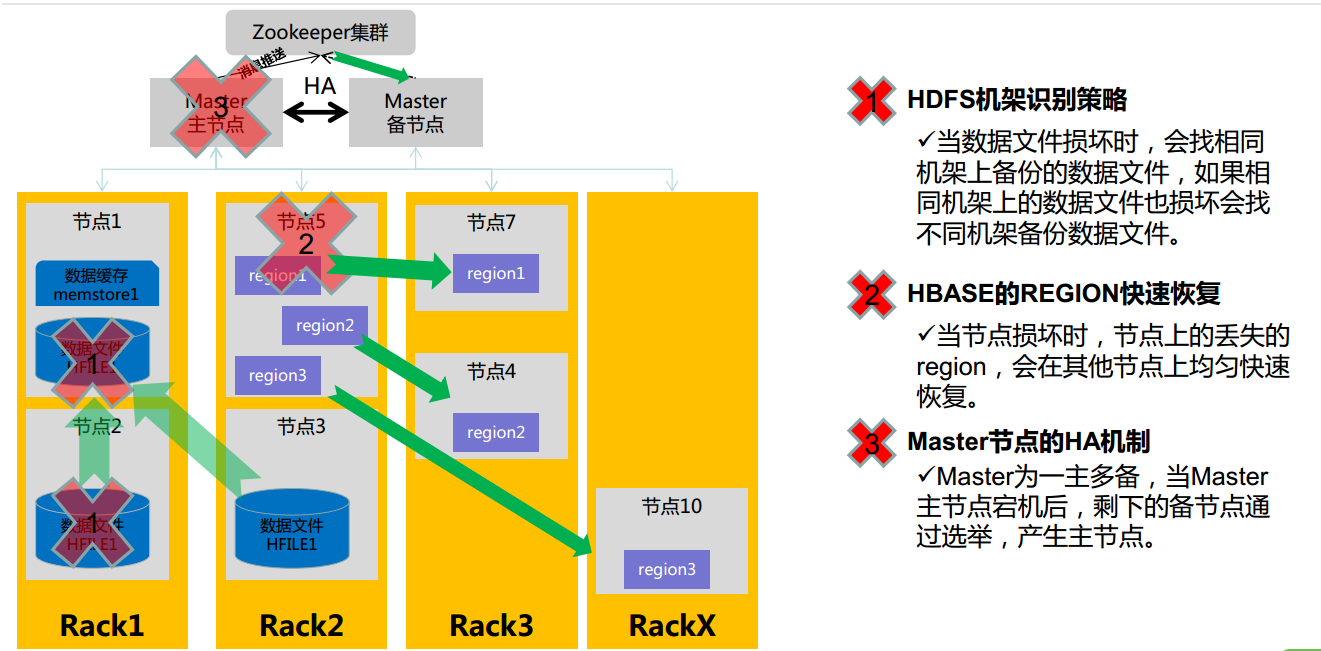
HBase容错性

Region定位

先访问zookeeper,找到root表的位置,root表记录了meta表的位置,在meta表里面查找对应的rowkey查找所在的region,并获取用户region的位置
-ROOT-和.META.表结构

如果是root表,表名就是.meta。如果是meta表,表名就是用户的id 订单等等。
-ROOT-表和.META


Hbase 读流程
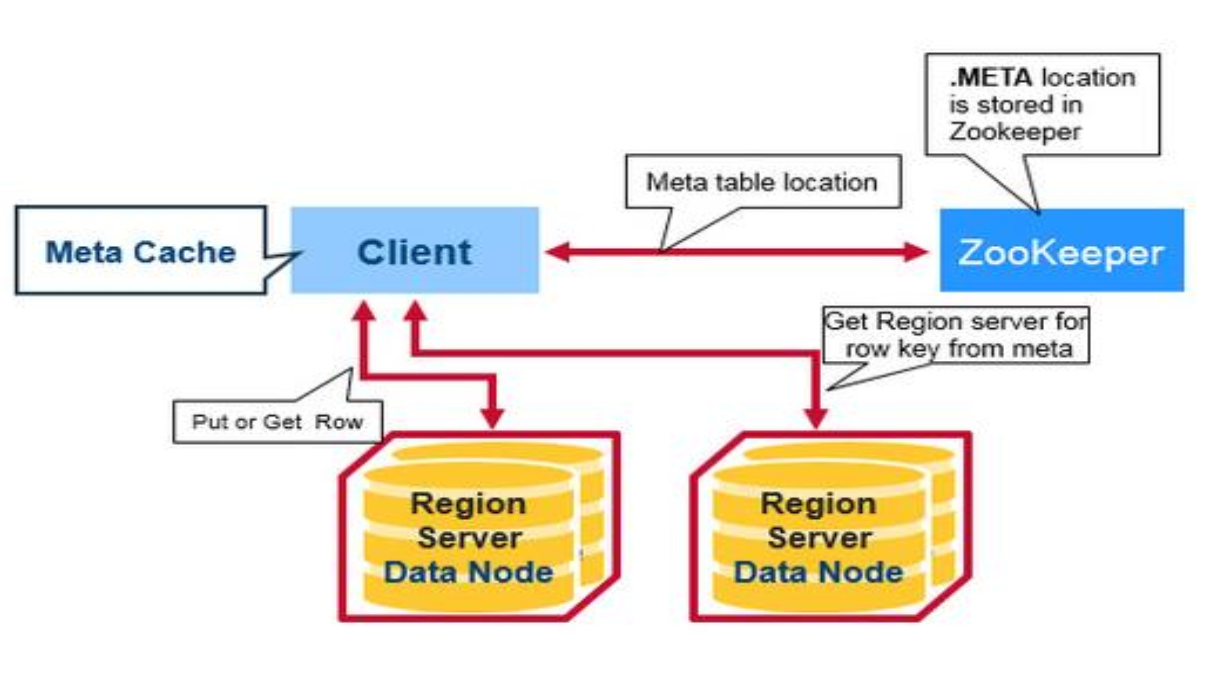
Client客户端先找到zookeeper拿到meta表,meta表根据rowkey拿到相应的region信息,找到对应的regionsever
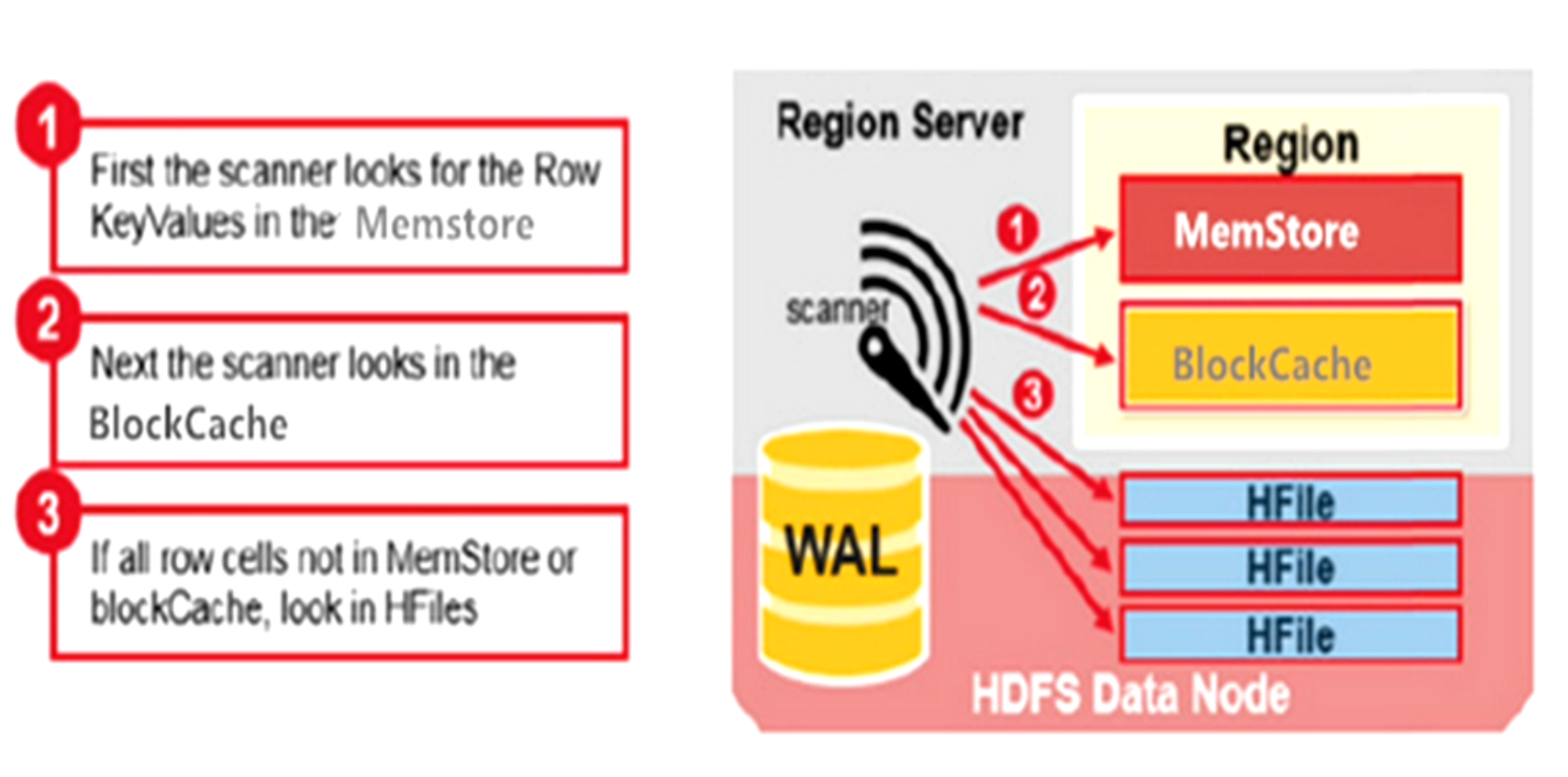
1.memstore是写缓存,blockcache是读缓存。
2.读数据的时候先到写缓存memstore去读,这样能提高读的效率,当memstore没有了,才到读缓存blockcache读数据。如果上面两个缓存(属于内存)都没有的情况下,就到磁盘去读。
3.在读到磁盘的时候去查找相应的数据,在没找到之前把前面的hfile放到blockcache读缓存里面,因为blockcache的空间也是有限的,如果blockcache读满了还没有找到需要查询的数据,blockcache就会淘汰一部分数据。
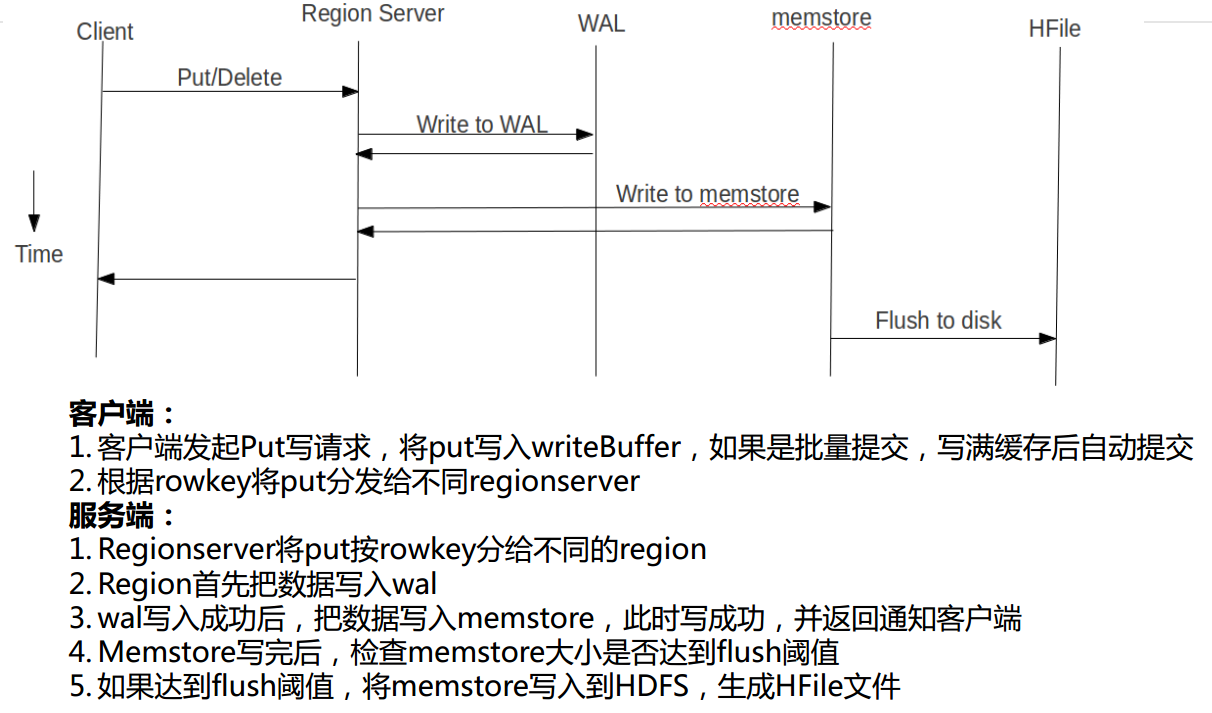
HBase put写流程
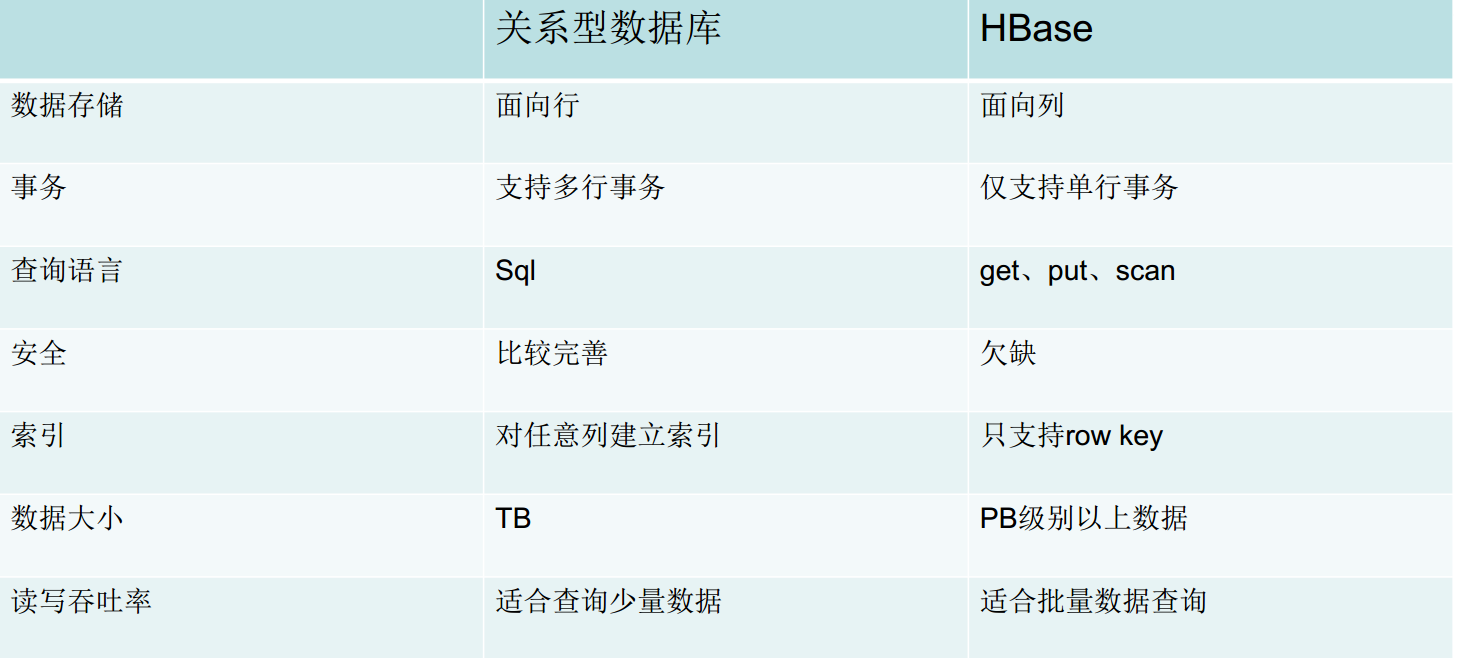
Hbase VS 关系型数据库
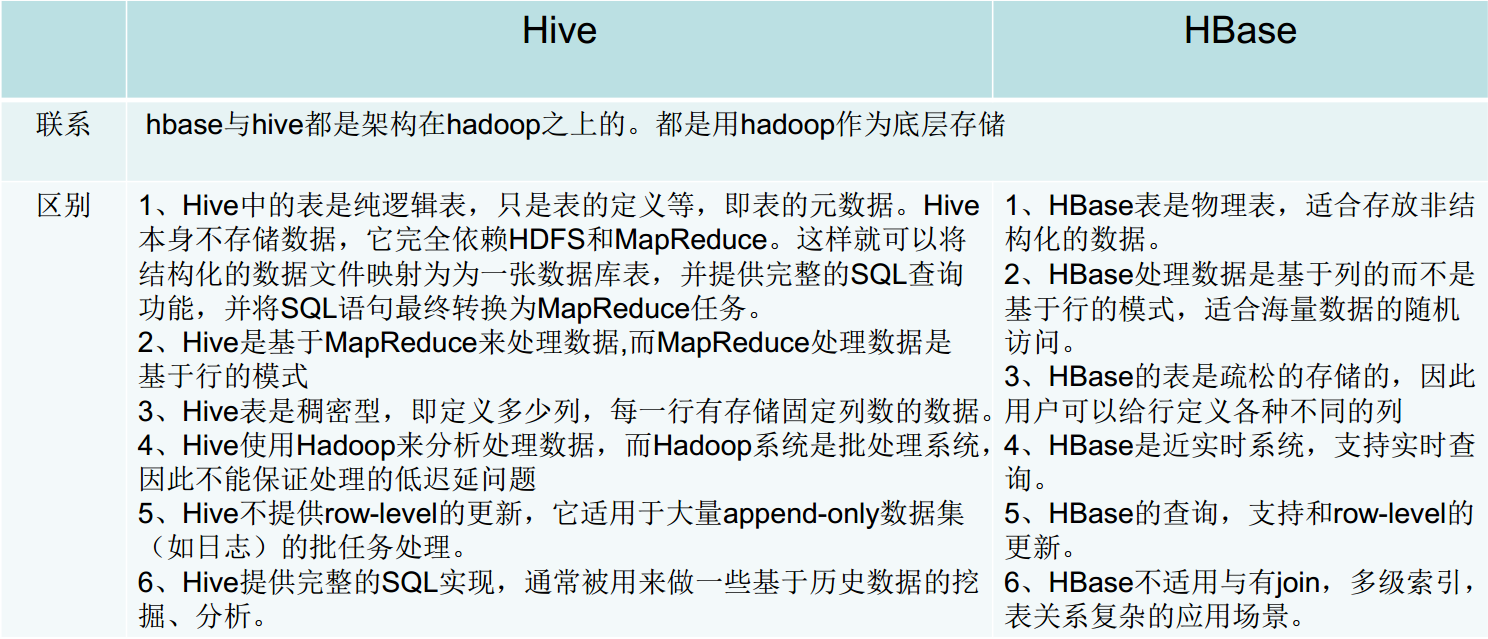
Hbase VS Hive