自己用 python 实现 base64 编码
base64 编码原理
二进制文件中包含有很多无法显示和打印的字符,二进制的数据一般以 ASCII 码形式(8 bit,即一个字节)存储,8 bit 可以表示 128 个不同的编码,而 ASCII 码中有 33 个编码表示的不是显示或打印的字符:
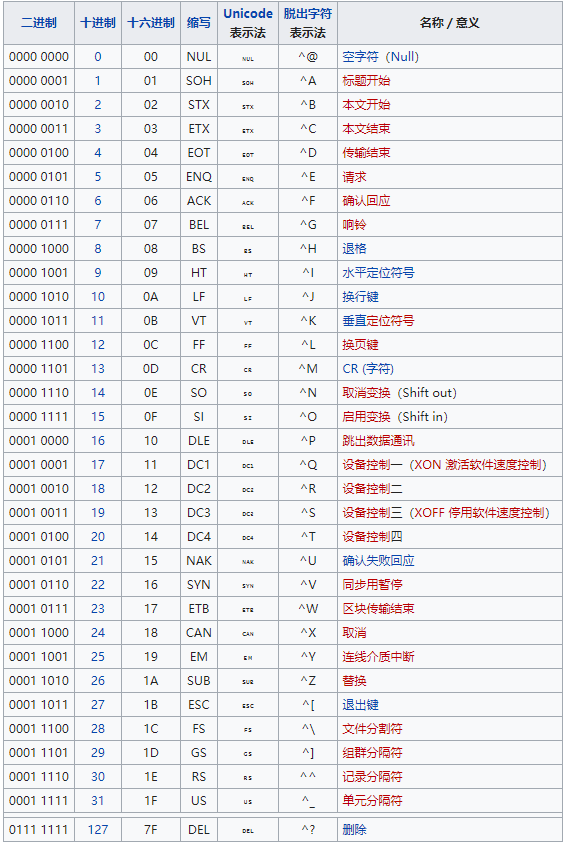
图片来自维基百科
剩下的编码表示的是可以打印的字符:

图片来自维基百科
当处理二进制文件中的数据时,就需要将无法显示或打印的字符进行转换,Base64 编码的原理就是将这 128 个不同的编码(可以打印或不可打印的字符)映射到 64 个可以打印的字符集中。
准备字符数组/字符串
首先准备 64 个可以显示/打印的字符数组(字符串),可以用 chr 将十进制数据转换成相应的字符,然后构造成字符数组:
def constructTable():
array = []
for i in range( 65, 91 ):
array.append( chr( i ) )
for i in range( 97, 123 ):
array.append( chr( i ) )
for i in range( 0, 10 ):
array.append( str( i ) )
array.append( '+' )
array.append( '-' )
# print( array )
return array
也可以用 string 提供的常量构造出一个字符串:
def constructTable2():
str = string.ascii_uppercase + string.ascii_lowercase + string.digits
return str + '+' + '-'
两者取出相应位置的字符都可以用数组的形式,比如用 table 保存字符数组/字符串,table[2] 就是 C。
处理数据
接下来对二进制数据进行处理,每 3 个字节一组进行处理即可:
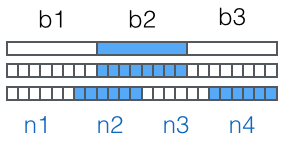
图片来自廖雪峰的官方教程
只考虑数据字节数为 3 的情况,将其重新编码:
def _b64encode_str( s0, s1, s2 ):
"""
s0、s1、s2 依次为第一、二、三个字符
"""
d = s2 & 63
d = array[ d ]
c1 = ( s1 & 15 ) << 2
c2 = ( s2 & 192 ) >> 6
c = c1 + c2
c = array[ c ]
b1 = ( s0 & 3 ) << 4
b2 = ( s1 & 240 ) >> 4
b = b1 + b2
b = array[ b ]
a = ( s0 & 252 ) >> 2
a = array[ a ]
return ''.join( [ a, b, c, d ] )
这里的思路是从右往左,依次计算出 d、c、b、a,也就是对应着上图的 n4、n3、n2、n1。当要编码的数据不是 3 的倍数时,需要在数据末尾用 x00 补足成 3 的倍数,最后根据补 x00 的次数在编码后的字符串中添加相应个数的 =。
# input is str
length = len( str )
remainder = length % 3
# fill with zero
if( remainder == 1 ):
str = str + b'x00x00' # add twice
length += 2
elif( remainder == 2 ):
str = str + b'x00' # add once
length += 1
之后,再将原始数据进行编码,先考虑简单的 remainder == 0 的情况,每 3 个字符一组进行编码即可:
i = 0
buf = StringIO()
while i < length:
en = _b64encode_str( str[ i ], str[ i+1 ], str[ i+2 ] )
buf.write( en )
i += 3
如果 remainder != 0,那么最后的三个字符中有添加的 =,这三个字符需要特殊处理,前面的字符和上面的处理方式一样,在最后返回的时候调用字符串的 encode 方法将其转为二进制:
while i < length - 3:
en = _b64encode_str( str[ i ], str[ i+1 ], str[ i+2 ] )
buf.write( en )
i += 3
# print( remainder, i, buf.getvalue() )
en = _b64encode_str( str[ i ], str[ i+1 ], str[ i+2 ] )
buf.write( en[ 0 ] )
buf.write( en[ 1 ] )
if( remainder == 2 ):
buf.write( en[ 2 ] ) # add once
buf.write( '=' )
elif( remainder == 1 ):
buf.write( '==' ) # add twice
然后编写一个简单的测试文件,简单验证下自己编写的 b64encode 方法是否正确:
def randomString():
# print( chars )
size = random.randint( 70, 100 )
rstr = ''.join( random.SystemRandom().choices( _CHARS, k = size ) )
return rstr.encode()
def compare():
rstr = randomString()
exp = base64.b64encode( rstr )
act = mybase64.b64encode( rstr )
if( exp != act ):
print( rstr )
print( exp )
print( act )
raise ValueError
loops = 10000
print( 'encode comp: ', timeit.timeit( stmt = compare, number = loops ) )
按照标准的 Base64 编码编写的代码没有问题。
性能比较
最后将 Python 自带的 base64 编码和自己编写的编码函数进行比较:
def encode1():
rstr = randomString()
base64.b64encode( rstr )
def encode2():
rstr = randomString()
mybase64.b64encode( rstr )
loops = 10000
print( sys.version )
print( 'random: ', timeit.timeit( randomString, number = loops ) )
print( 'encode1: ', timeit.timeit( stmt = encode1, number = loops ) )
print( 'encode2: ', timeit.timeit( stmt = encode2, number = loops ) )
输出结果如下:

小结
可以看到,自己编写的编码方法用时大约 0.447 seconds, base64 库提供的方法的用时约为 0.030 seconds,性能差距约 15 倍。所以一般没有必要自己实现 base64 编码。
另外测试中相应的 decode 方法是没有实现的,实现起来也比较简单,按照编码的方式反过来做就好了。
代码地址:github
Notable
- python 中 str 对象执行 encode 方法后字符串将会以二进制形式保存
- chr( 1 ) 返回值是
'x01',对应的是不可打印的字符,str( 1 ) 返回值是'1',是可以打印的字符。