原文链接:https://adamsitnik.com/Array-Pool/
第一次翻译,会有较多机翻,如果有错误,请及时指出批评,我会立即改正。
使用ArrayPool来避免大数组造成的Full GC的问题。
简介
.NET的垃圾收集器(GC)实现了许多性能优化,其中之一就是,设定年轻的对象很快消亡,然而老的对象却可以生存很久。这就是为什么托管堆被划分为三个代。我们称呼他们为第0代(最年轻的)、第1代(短暂生存)、第2代(生存最长的)。新的对象默认都被分配到第0代。当GC尝试分配一个新的对象到第0代时并且发现第0代已经满了,就会触发第0代进行回收,这个被称呼为局部回收(仅仅回收第0代)。GC遍历整个对象图形,从最根部(局部变量,静态字段等)开始,将所有的引用对象标记为生存对象。
以上是第一阶段,被称为“标记”阶段,此阶段为非阻塞的。但是GC回收进程是阻塞的,GC会挂起所有的线程来执行下一步。
生存了的对象被提权(提权过程大部分时间都是消耗在数据拷贝上)到第1代,然后第0代被清空。第0代往往被设计为很小,所以执行第0代的回收会比较快。理想情况下,一个WEB请求,从开始请求到结束请求,所有被分配的对象都应该被回收掉。然后GC就可以将下一个对象指针移到第0代的起始位置。同理,根据第0代的回收逻辑,当第1代也满了之后,GC就不能再将第0代的对象进行提权到第1代了。接着GC就开始回收第1代的内存。第1代也很小,执行回收也很快,紧接着,第1代的生存者被提权到第2代。第2代里面都是生存期很长的对象,第2代非常大并且执行第2代的垃圾回收会非常非常耗时。所以针对于第2代的垃圾回收我们应该尽量避免,想知道为什么?让我们看看下面的视频然后看看第2代的垃圾回收是如何影响用户体验的。
大对象堆栈(LOH)
每当GC将对象转移到新的一代时,都会进行内存拷贝。如你想象,如果是在拷贝一些大对象,例如大数组或者字符串时会尤其耗时。为了解决这种问题,GC有另一个优化手段,任何一个大于85000字节的对象都被认为是大对象,大对象存储在托管堆的单独部分中,称为大对象堆(LOH),该部分使用自由列表算法进行管理。这意味着GC有一个免费的内存段列表,当我们想要分配一些大的内容时,它会搜索列表以找到一个可行的内存段。因此,默认情况下,大对象永远不会在内存中移动。然而,如果遇到LOH碎片问题,则需要压缩LOH。从.NET 4.5.1开始,您可以按需执行此操作。
问题来了
分配大对象时,它被标记为GC的第2代对象。不像小对象是默认放在第0代的。这种机制的结果就是如果你在LOH中耗尽内存,GC会清理整个托管堆(第0代、第1代、第2代以及LOH块),而不仅仅是LOH。这种行为被称为Full GC,是最为耗时的垃圾回收。对于许多应用,Full GC可以忍受,但是对于高性能的WEB服务器,实在是无法忍受,其中需要很少的大内存缓冲来处理平均的Web请求(例如从套接字读取,解压缩,解码JSON等等)。
要是想知道Full GC是不是你的应用性能问题,可以用内置的perfmon.exe程序获得简单的视图报告。

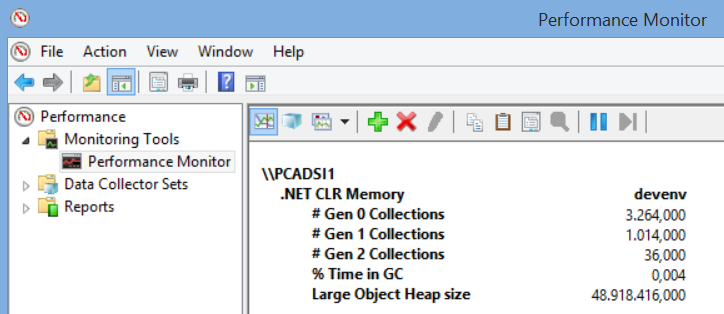
如你所见,对于我的Visual Studio程序来说,Full GC不是问题,我的Visual Studio应用程序已经运行了好几个小时了,第2代的回收相比于第0、1代来说要少很多。
解决方案
解决方案非常简单:缓冲池。 池(Pool)是一组可以使用的初始化对象。我们不是分配新对象,而是从池中租用它。一旦我们完成使用,我们就将它返回到池中。每个大型托管对象都是一个数组或数组包装器(字符串包含一个长度字段和一个字符数组)。所以我们需要池数组来避免这个问题。
ArrayPool
代码示例
var samePool = ArrayPool<byte>.Shared;
byte[] buffer = samePool.Rent(minLength);
try
{
Use(buffer);
}
finally
{
samePool.Return(buffer);
// don't use the reference to the buffer after returning it!
}
void Use(byte[] buffer) // it's an array
如何使用
首先你需要一个初始化的池,至少有三种方式可以获得:
- 最建议的方式:使用 ArrayPool
.Shared 属性,它将返回一个线程安全的可共享的池对象实例,不过要记住他有一个默认的最大数组长度( 2^20 (1024*1024 = 1 048 576))。 - 使用 ArrayPool
.Create静态方法,也可以创建一个线程安全的池,并且可以自定义maxArrayLength和maxArraysPerBucket两个参数,如果最大数组长度对你来说不够的话,你可以尝试使用。不过请记住,一旦你创建了它,你有责任让它保持活力。 - 从抽象ArrayPool
派生自定义类并且自己实现处理机制。
接下来,在获取了初始化池之后你就需要调用Rent方法,它需要你传入一个你想要的缓存的最小长度,请记住,Rent返回的内容可能比您要求的要大。
byte[] webRequest = request.Bytes;
byte[] buffer = ArrayPool<byte>.Shared.Rent(webRequest.Length);
Array.Copy(
sourceArray: webRequest,
destinationArray: buffer,
length: webRequest.Length); // webRequest.Length != buffer.Length!!
完成使用后,只需使用Return方法将其返回到相同的池中即可。Return方法有一个重载,它允许你清理缓冲区,以便后续的消费者调用Rent方法不会看到以前的消费者的内容。默认情况下,内容保持不变。
源码中有一段关于ArrayPool的一个非常重要的备注
Once a buffer has been returned to the pool, the caller gives up all ownership of the buffer and must not use it. The reference returned from a given call to Rent must only be returned via Return once.
这意味着,开发人员需要正确使用此功能。如果在将缓冲区返回到池后继续使用对缓冲区的引用,则存在不可预料的风险。据我所知,截止至今天来说还没有一个静态代码分析工具可以校验正确的用法。 ArrayPool是corefx库的一部分,它不是C#语言的一部分。
压测
让我们使用BenchmarkDotNet来比较使用new操作符分配数组和使用ArrayPoolRent和Return的消耗,我正在运行.NET Core 2.0的基准测试,这很重要,因为它具有更快的ArrayPool
class Program
{
static void Main(string[] args) => BenchmarkRunner.Run<Pooling>();
}
[MemoryDiagnoser]
[Config(typeof(DontForceGcCollectionsConfig))] // we don't want to interfere with GC, we want to include it's impact
public class Pooling
{
[Params((int)1E+2, // 100 bytes
(int)1E+3, // 1 000 bytes = 1 KB
(int)1E+4, // 10 000 bytes = 10 KB
(int)1E+5, // 100 000 bytes = 100 KB
(int)1E+6, // 1 000 000 bytes = 1 MB
(int)1E+7)] // 10 000 000 bytes = 10 MB
public int SizeInBytes { get; set; }
private ArrayPool<byte> sizeAwarePool;
[GlobalSetup]
public void GlobalSetup()
=> sizeAwarePool = ArrayPool<byte>.Create(SizeInBytes + 1, 10); // let's create the pool that knows the real max size
[Benchmark]
public void Allocate()
=> DeadCodeEliminationHelper.KeepAliveWithoutBoxing(new byte[SizeInBytes]);
[Benchmark]
public void RentAndReturn_Shared()
{
var pool = ArrayPool<byte>.Shared;
byte[] array = pool.Rent(SizeInBytes);
pool.Return(array);
}
[Benchmark]
public void RentAndReturn_Aware()
{
var pool = sizeAwarePool;
byte[] array = pool.Rent(SizeInBytes);
pool.Return(array);
}
}
public class DontForceGcCollectionsConfig : ManualConfig
{
public DontForceGcCollectionsConfig()
{
Add(Job.Default
.With(new GcMode()
{
Force = false // tell BenchmarkDotNet not to force GC collections after every iteration
}));
}
}
结果
如果你对于BenchmarkDotNet在内存诊断程序开启的情况下所输出的内容不清楚的话,你可以读我的这一篇文章来了解如何阅读这些结果。
BenchmarkDotNet=v0.10.7, OS=Windows 10 Redstone 1 (10.0.14393)
Processor=Intel Core i7-6600U CPU 2.60GHz (Skylake), ProcessorCount=4
Frequency=2742189 Hz, Resolution=364.6722 ns, Timer=TSC
dotnet cli version=2.0.0-preview1-005977
[Host] : .NET Core 4.6.25302.01, 64bit RyuJIT
Job-EBWZVT : .NET Core 4.6.25302.01, 64bit RyuJIT
| Method | SizeInBytes | Mean | Gen 0 | Gen 1 | Gen 2 | Allocated |
|---|---|---|---|---|---|---|
| Allocate | 100 | 8.078 ns | 0.0610 | - | - | 128 B |
| RentAndReturn_Shared | 100 | 44.219 ns | - | - | - | 0 B |
对于非常小的内存块,默认分配器可以更快
| Method | SizeInBytes | Mean | Gen 0 | Gen 1 | Gen 2 | Allocated |
|---|---|---|---|---|---|---|
| Allocate | 1000 | 41.330 ns | 0.4880 | 0.0000 | - | 1024 B |
| RentAndReturn_Shared | 1000 | 43.739 ns | - | - | - | 0 B |
对于1000个字节他们的速度也差不多
| Method | SizeInBytes | Mean | Gen 0 | Gen 1 | Gen 2 | Allocated |
|---|---|---|---|---|---|---|
| Allocate | 10000 | 374.564 ns | 4.7847 | 0.0000 | - | 10024 B |
| RentAndReturn_Shared | 10000 | 44.223 ns | - | - | - | 0 B |
随着分配的字节增加,被分配的内存增多导致程序越来越慢。
| Method | SizeInBytes | Mean | Gen 0 | Gen 1 | Gen 2 | Allocated |
|---|---|---|---|---|---|---|
| Allocate | 100000 | 3,637.110 ns | 31.2497 | 31.2497 | 31.2497 | 10024 B |
| RentAndReturn_Shared | 100000 | 46.649 ns | - | - | - | 0 B |
第2代回收,当大于85000字节时,我们看到了第一次的Full GC回收。
| Method | SizeInBytes | Mean | StdDev | Gen 0/1/2 | Allocated |
|---|---|---|---|---|---|
| RentAndReturn_Shared | 100 | 44.219 ns | 0.0314 ns | - | 0 B |
| RentAndReturn_Shared | 1000 | 43.739 ns | 0.0337 ns | - | 0 B |
| RentAndReturn_Shared | 10000 | 44.223 ns | 0.0333 ns | - | 0 B |
| RentAndReturn_Shared | 100000 | 46.649 ns | 0.0346 ns | - | 0 B |
| RentAndReturn_Shared | 1000000 | 42.423 ns | 0.0623 ns | - | 0 B |
此刻,你应该注意到了,ArrayPool
被分配的缓存
如果当我们在给定的池中租赁的缓存超过了最大长度限制(2^20,ArrayPool.Shared)会发生什么呢?
| Method | SizeInBytes | Mean | Gen 0 | Gen 1 | Gen 2 | Allocated |
|---|---|---|---|---|---|---|
| Allocate | 10000000 | 557,963.968 ns | 211.5625 | 211.5625 | 211.5625 | 10000024 B |
| RentAndReturn_Shared | 10000000 | 651,147.998 ns | 207.1484 | 207.1484 | 207.1484 | 10000024 B |
| RentAndReturn_Aware | 10000000 | 47.033 ns | - | - | - | 0 B |
当超过了最大长度限制,每一次运行时都会重新分配一段新的缓存区。并且当你把它还到池里的时候,都会被忽略而不是再放入池中。
别担心,ArrayPool
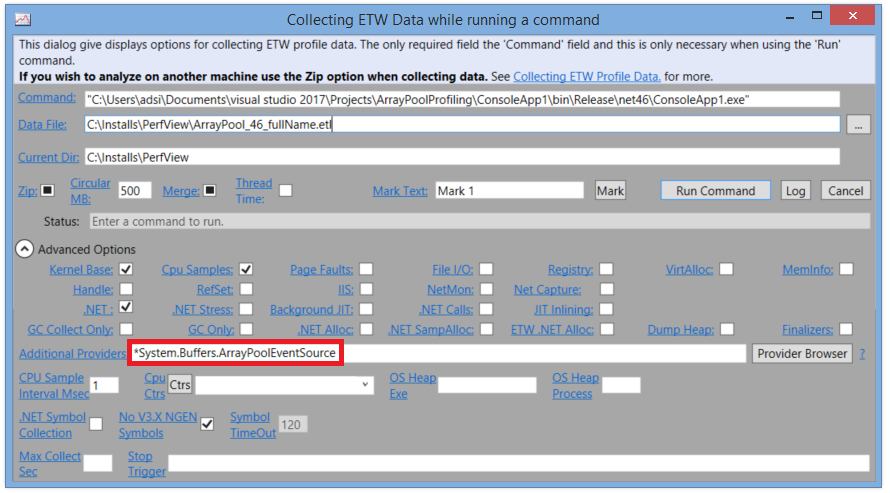
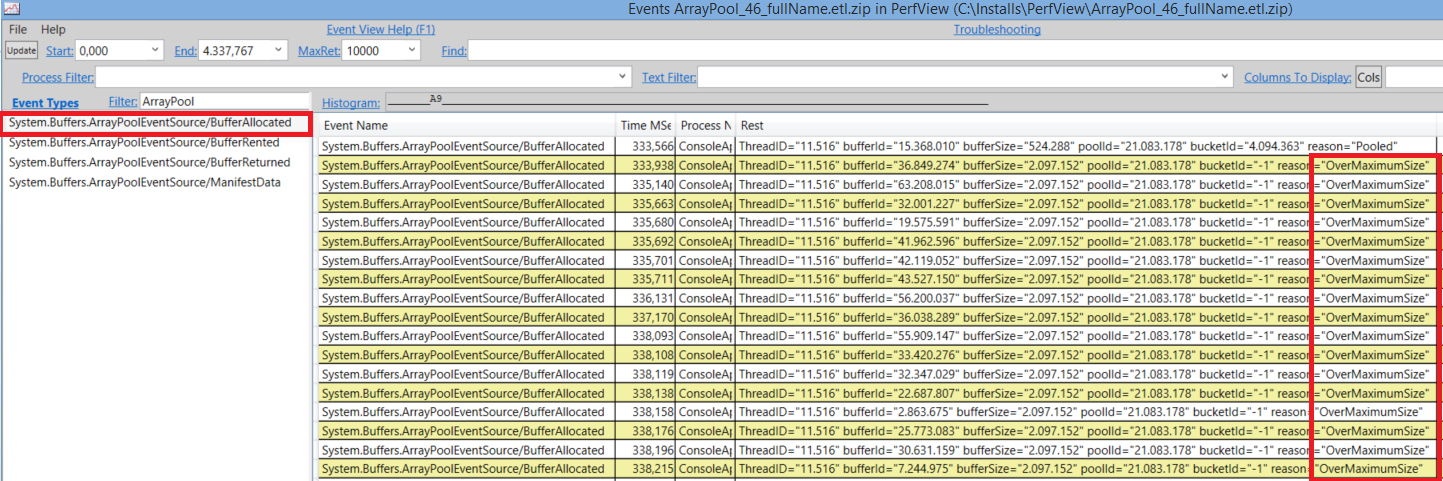
为了避免这种问题,你可以使用ArrayPool
MemoryStream的池化
有时,为了避免LOH的分配一个数组可能不是很够,有个第三方API的,
感谢Victor Baybekov我发现了Microsoft.IO.RecyclableMemoryStream库,这个库提供了MemoryStream对象的池化,这个是Bing的工程师为了解决LOH问题所涉及的。想要知道更多细节可以查看Ben Watson写的这篇博客。
总结
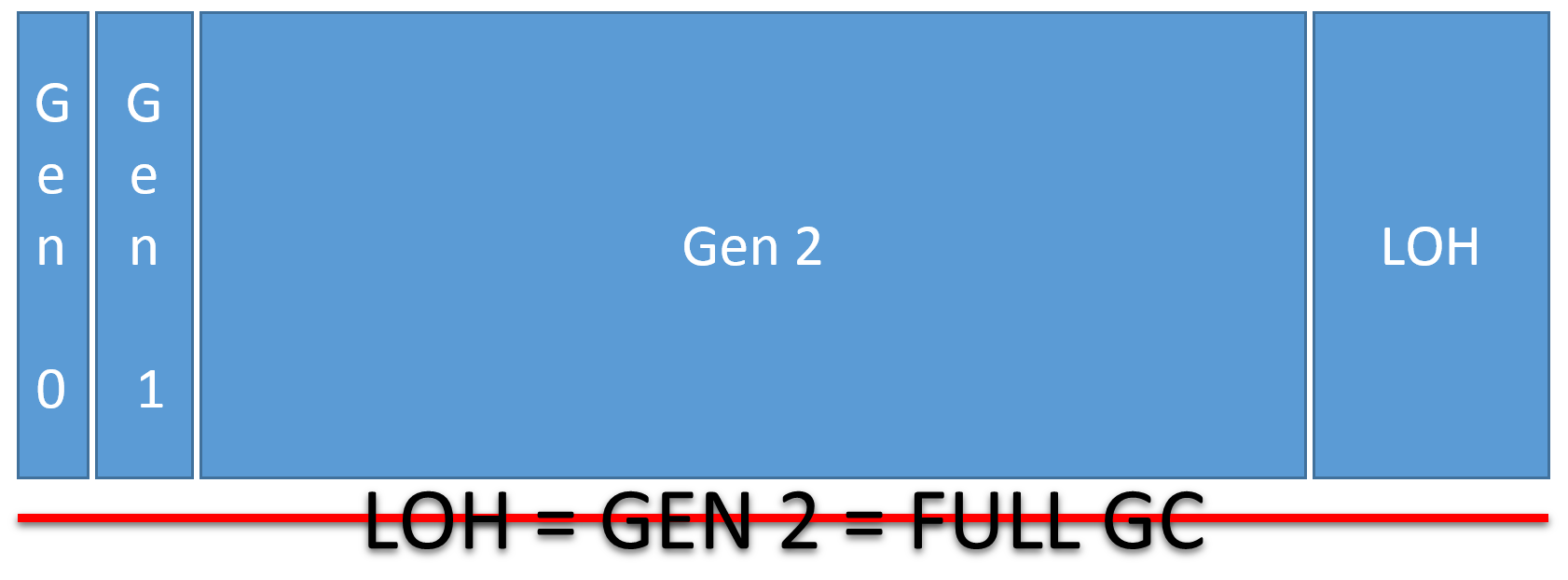
- LOH = 第2代 = Full GC = 糟糕的性能
- ArrayPool 被设计为更好的性能
- 如果你能控制生命周期可以使用池化
- 默认使用ArrayPool
.Shared - 池化的时候分配的内存不要超过最大数组长度限制
- 池越少,LOH就会越小,效率越好