1. str
str.count(sub[, start[, end]])
str.encode(encoding="utf-8", errors="strict")
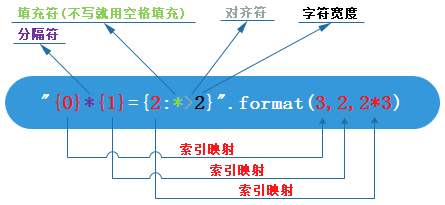
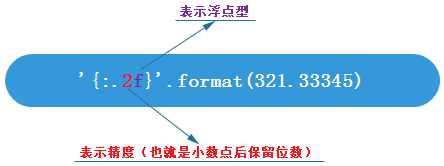
str.format(*args, **kwargs) # s = "this is from {}".format(__file__)
str.find(sub[, start[, end]]) # 没有查找到子串,返回-1
str.rfind(sub[, start[, end]]) # 没有查找到子串,则报Except
str.index(sub[, start[, end]])
str.replace(old, new[, count])
str.join(iterable)
str.split(sep=None, maxsplit=-1)
str.splitlines([keepends]) # keepends: 在输出结果里是否保留换行符('
', '
', '
'),默认为False,不包含换行符;如果为True,则保留换行符。
str.strip([chars])
str.lstrip([chars])
str.rstrip([chars])
str.partition(sep) # 通过sep将字符串分成三部分
str.rpartition(sep)
In [85]: "what do you do wait".rpartition("do")
Out[85]: ('what do you ', 'do', ' wait')
str.expandtabs(tabsize=8) # 把字符串中的 tab 符号(' ')转为空格
str.zfill(width) # 返回指定长度width的字符串,原字符串右对齐,前面填充0
str.upper()
str.lower()
str.islower()
c.isalpha() # 字母
c.isdecimal() # Unicode数字,,全角数字(双字节)
c.isdigit() # Unicode数字,byte数字(单字节),全角数字(双字节),罗马数字
c.isnumeric() # Unicode数字,全角数字(双字节),罗马数字,汉字数字
str.startswith(prefix[, start[, end]])
str.endswith(suffix[, start[, end]])
eval(source[, globals[, locals]]) # 将str作为有效表达式并返回结果
2. bytes / bytearray
classmethod
- fromhex(string)
- encode()
bytes.count(sub[, start[, end]])
bytes.decode(encoding="utf-8", errors="strict")
bytearray.decode(encoding="utf-8", errors="strict")
bytes.find(sub[, start[, end]])
bytearray.find(sub[, start[, end]])
bytes.join(iterable)
bytearray.join(iterable)
bytes.replace(old, new[, count])
bytearray.replace(old, new[, count])
bytes.startswith(prefix[, start[, end]])
bytearray.startswith(prefix[, start[, end]])
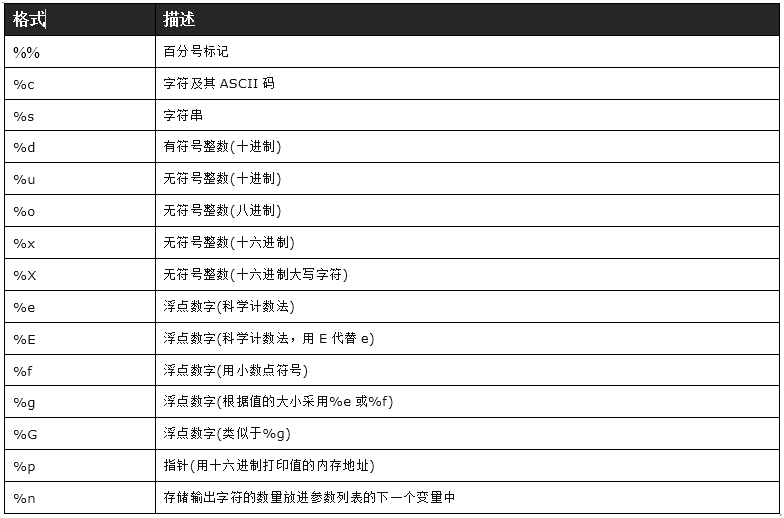
3. printf-style String Formatting