1. Paddle框架
目前支持Window、Linux多平台,v2.0后,也已支持python3.8。MacOS似乎不支持GPU,具体请查看官网最新说明。
1.1. 基于pip安装
使用pip3的话,需要注意 pip3>20.2.2 :
pip3 install -U pip
-
CPU版本
pip3 install paddlepaddle -i https://mirror.baidu.com/pypi/simple -
GPU版本
pip3 install paddlepaddle-gpu -i https://mirror.baidu.com/pypi/simple
测试安装是否成功:
python3 -c 'import paddle; paddle.utils.run_check()'
1.2. 编译安装
2. PP-OCR
2.1. 安装
安装paddlepaddle模块后,克隆PaddleOCR repo代码:
git clone https://gitee.com/paddlepaddle/PaddleOCR
安装第三方库
cd PaddleOCR
pip3 install -r requirements.txt
2.2. 下载推理模型
接下来配置模型:
推理模型用于python预测引擎推理,即实际部署是所使用的模型训练模型是基于预训练模型在真实数据与竖排合成文本数据上finetune得到的模型,在真实应用场景中有着更好的表现预训练模型则是直接基于全量真实数据与合成数据训练得到,更适合用于在自己的数据集上finetune
以超轻量级模型为例:
mkdir inference && cd inference
# 下载超轻量级中文OCR模型的检测模型并解压
wget https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_det_infer.tar && tar xf ch_ppocr_mobile_v2.0_det_infer.tar
# 下载超轻量级中文OCR模型的识别模型并解压
wget https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_rec_infer.tar && tar xf ch_ppocr_mobile_v2.0_rec_infer.tar
# 下载超轻量级中文OCR模型的文本方向分类器模型并解压
wget https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_cls_infer.tar && tar xf ch_ppocr_mobile_v2.0_cls_infer.tar
解压完毕后应有如下文件结构:
├── ch_ppocr_mobile_v2.0_cls_infer
│ ├── inference.pdiparams
│ ├── inference.pdiparams.info
│ └── inference.pdmodel
├── ch_ppocr_mobile_v2.0_det_infer
│ ├── inference.pdiparams
│ ├── inference.pdiparams.info
│ └── inference.pdmodel
├── ch_ppocr_mobile_v2.0_rec_infer
├── inference.pdiparams
├── inference.pdiparams.info
└── inference.pdmodel
注意:PaddleOCR的优势在于中文识别,但其也提供了在无需单独的 (英文+数字) 的组合识别模型,地址如下:gitee_paddleocr_doc
说明:2.0版模型和1.1版模型的主要区别在于动态图训练vs.静态图训练,模型性能上无明显差距。而v1.1版本的模型分类各细致,并提供了slim高度裁剪的lite版本,地址如下gitee_paddle_doc_v1.1。
而v2.0版本的模型库中,多语言支持已经极大地丰富了!
2.3. 模型文件的深度解析
-
checkpoints模型,是训练过程中保存的模型,文件中只记录了模型的参数,多用于恢复训练等。
-
inference模型(paddle.jit.save保存的模型),一般是模型训练,把模型结构和模型参数保存在文件中的固化模型,多用于预测部署场景。
与checkpoints模型相比,inference 模型会额外保存模型的结构信息,在预测部署、加速推理上性能优越,灵活方便,适合于实际系统集成。
2.3.1. 检测模型转inference模型
wget -P ./ch_lite/ https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_det_train.tar
tar xf ./ch_lite/ch_ppocr_mobile_v2.0_det_train.tar -C ./ch_lite/
-c后面设置训练算法的yml配置文件-o配置可选参数Global.pretrained_model参数设置待转换的训练模型地址,不用添加文件后缀 .pdmodel,.pdopt或.pdparams。Global.load_static_weights参数需要设置为 False。Global.save_inference_dir参数设置转换的模型将保存的地址。
python3 tools/export_model.py
-c configs/det/ch_ppocr_v2.0/ch_det_mv3_db_v2.0.yml
-o Global.pretrained_model=./ch_lite/ch_ppocr_mobile_v2.0_det_train/best_accuracy
Global.load_static_weights=False
Global.save_inference_dir=./inference/det_db/
转inference模型时,使用的配置文件和训练时使用的配置文件相同。另外,还需要设置配置文件中的 Global.pretrained_model 参数,其指向训练中保存的模型参数文件。
转换成功后,在模型保存目录下有三个文件:
inference/det_db/
├── inference.pdiparams # 检测inference模型的参数文件
├── inference.pdiparams.info # 检测inference模型的参数信息,可忽略
└── inference.pdmodel # 检测inference模型的program文件
2.3.2. 识别模型转inference模型
wget -P ./ch_lite/ https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_rec_train.tar
tar xf ./ch_lite/ch_ppocr_mobile_v2.0_rec_train.tar -C ./ch_lite/
python3 tools/export_model.py
-c configs/rec/ch_ppocr_v2.0/rec_chinese_lite_train_v2.0.yml
-o Global.pretrained_model=./ch_lite/ch_ppocr_mobile_v2.0_rec_train/best_accuracy
Global.load_static_weights=False
Global.save_inference_dir=./inference/rec_crnn/
2.3.3. 方向分类模型转inference模型
wget -P ./ch_lite/ https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_cls_train.tar
tar xf ./ch_lite/ch_ppocr_mobile_v2.0_cls_train.tar -C ./ch_lite/
python3 tools/export_model.py
-c configs/cls/cls_mv3.yml
-o Global.pretrained_model=./ch_lite/ch_ppocr_mobile_v2.0_cls_train/best_accuracy
Global.load_static_weights=False
Global.save_inference_dir=./inference/cls/
2.4. 使用:图像预测
# 预测image_dir指定的单张图像
python3 tools/infer/predict_system.py --image_dir="./doc/imgs/11.jpg" --det_model_dir="./inference/ch_ppocr_mobile_v2.0_det_infer/" --rec_model_dir="./inference/ch_ppocr_mobile_v2.0_rec_infer/" --cls_model_dir="./inference/ch_ppocr_mobile_v2.0_cls_infer/" --use_angle_cls=True --use_space_char=True
# 预测image_dir指定的图像集合
python3 tools/infer/predict_system.py --image_dir="./doc/imgs/" --det_model_dir="./inference/ch_ppocr_mobile_v2.0_det_infer/" --rec_model_dir="./inference/ch_ppocr_mobile_v2.0_rec_infer/" --cls_model_dir="./inference/ch_ppocr_mobile_v2.0_cls_infer/" --use_angle_cls=True --use_space_char=True
# 如果想使用CPU进行预测,需设置use_gpu参数为False
python3 tools/infer/predict_system.py --image_dir="./doc/imgs/11.jpg" --det_model_dir="./inference/ch_ppocr_mobile_v2.0_det_infer/" --rec_model_dir="./inference/ch_ppocr_mobile_v2.0_rec_infer/" --cls_model_dir="./inference/ch_ppocr_mobile_v2.0_cls_infer/" --use_angle_cls=True --use_space_char=True --use_gpu=False
注意:
- 如果希望使用不支持空格的识别模型,在预测的时候需要注意:请将代码更新到最新版本,并添加参数
--use_space_char=False。 - 如果不希望使用方向分类器,在预测的时候需要注意:请将代码更新到最新版本,并添加参数
--use_angle_cls=False。
2.5. 部署
PaddleOCR提供2种Server端部署服务的方式:
- 基于PaddleHub Serving的部署:代码路径为"./deploy/hubserving",按照本教程使用;
(coming soon) - 基于PaddleServing的部署:代码路径为"./deploy/pdserving",使用方法参考文档。
2.5.1. 启动服务
-
命令行启动(仅支持CPU)服务
$ hub serving start --modules [Module1==Version1, Module2==Version2, ...] --port XXXX --use_multiprocess --workers -
配置文件启动(支持CPU、GPU)
hub serving start -c config.json
2.5.2. 发送预测请求
配置好服务端,可使用以下命令发送预测请求,获取预测结果:
python tools/test_hubserving.py server_url image_path
需要给脚本传递2个参数:
- server_url:服务地址,例如
http://127.0.0.1:8868/predict/ocr_system - image_path:测试图像路径,可以是单张图片路径,也可以是图像集合目录路径
访问示例:
python3 tools/test_hubserving.py http://127.0.0.1:8868/predict/ocr_system ./doc/imgs/
2.6. 数据标注与合成
2.6.1. 半自动标注工具: PPOCRLabel

运行:
# Windows + Anaconda
pip install pyqt5
cd ./PPOCRLabel # 将目录切换到PPOCRLabel文件夹下
python PPOCRLabel.py --lang ch
# Ubuntu Linux
pip3 install pyqt5 trash-cli
cd ./PPOCRLabel # 将目录切换到PPOCRLabel文件夹下
python3 PPOCRLabel.py --lang ch
2.6.2. 数据合成工具: Style-Text
2.7. FAQ精选
对于中文行文本识别,CTC和Attention哪种更优?
A:(1)从效果上来看,通用OCR场景CTC的识别效果优于Attention,因为带识别的字典中的字符比较多,常用中文汉字三千字以上,如果训练样本不足的情况下,对于这些字符的序列关系挖掘比较困难。中文场景下Attention模型的优势无法体现。而且Attention适合短语句识别,对长句子识别比较差。
(2)从训练和预测速度上,Attention的串行解码结构限制了预测速度,而CTC网络结构更高效,预测速度上更有优势。
PaddleOCR项目中的中文超轻量和通用模型用了哪些数据集?训练多少样本,gpu什么配置,跑了多少个epoch,大概跑了多久?
A: (1)检测的话,LSVT街景数据集共3W张图像,超轻量模型,150epoch左右,2卡V100 跑了不到2天;通用模型:2卡V100 150epoch 不到4天。 (2) 识别的话,520W左右的数据集(真实数据26W+合成数据500W)训练,超轻量模型:4卡V100,总共训练了5天左右。通用模型:4卡V100,共训练6天。
超轻量模型训练分为2个阶段: (1)全量数据训练50epoch,耗时3天 (2)合成数据+真实数据按照1:1数据采样,进行finetune训练200epoch,耗时2天
通用模型训练: 真实数据+合成数据,动态采样(1:1)训练,200epoch,耗时 6天左右。
PaddleOCR中,对于模型预测加速,CPU加速的途径有哪些?基于TenorRT加速GPU对输入有什么要求?
A:(1)CPU可以使用mkldnn进行加速;对于python inference的话,可以把enable_mkldnn改为true,参考代码,对于cpp inference的话,在配置文件里面配置use_mkldnn 1即可,参考代码
(2)GPU需要注意变长输入问题等,TRT6 之后才支持变长输入
目前OCR普遍是二阶段,端到端的方案在业界落地情况如何?
A:端到端在文字分布密集的业务场景,效率会比较有保证,精度的话看自己业务数据积累情况,如果行级别的识别数据积累比较多的话two-stage会比较好。百度的落地场景,比如工业仪表识别、车牌识别都用到端到端解决方案。
如何更换文本检测/识别的backbone?
A:无论是文字检测,还是文字识别,骨干网络的选择是预测效果和预测效率的权衡。一般,选择更大规模的骨干网络,例如ResNet101_vd,则检测或识别更准确,但预测耗时相应也会增加。而选择更小规模的骨干网络,例如MobileNetV3_small_x0_35,则预测更快,但检测或识别的准确率会大打折扣。幸运的是不同骨干网络的检测或识别效果与在ImageNet数据集图像1000分类任务效果正相关。飞桨图像分类套件PaddleClas汇总了ResNet_vd、Res2Net、HRNet、MobileNetV3、GhostNet等23种系列的分类网络结构,在上述图像分类任务的top1识别准确率,GPU(V100和T4)和CPU(骁龙855)的预测耗时以及相应的117个预训练模型下载地址。
(1)文字检测骨干网络的替换,主要是确定类似与ResNet的4个stages,以方便集成后续的类似FPN的检测头。此外,对于文字检测问题,使用ImageNet训练的分类预训练模型,可以加速收敛和效果提升。
(2)文字识别的骨干网络的替换,需要注意网络宽高stride的下降位置。由于文本识别一般宽高比例很大,因此高度下降频率少一些,宽度下降频率多一些。可以参考PaddleOCR中MobileNetV3骨干网络的改动。
对于CRNN模型,backbone采用DenseNet和ResNet_vd,哪种网络结构更好?
A:Backbone的识别效果在CRNN模型上的效果,与Imagenet 1000 图像分类任务上识别效果和效率一致。在图像分类任务上ResnNet_vd(79%+)的识别精度明显优于DenseNet(77%+),此外对于GPU,Nvidia针对ResNet系列模型做了优化,预测效率更高,所以相对而言,resnet_vd是较好选择。如果是移动端,可以优先考虑MobileNetV3系列。
对于特定文字检测,例如身份证只检测姓名,检测指定区域文字更好,还是检测全部区域再筛选更好?
A:两个角度来说明一般检测全部区域再筛选更好。
(1)由于特定文字和非特定文字之间的视觉特征并没有很强的区分行,只检测指定区域,容易造成特定文字漏检。
(2)产品的需求可能是变化的,不排除后续对于模型需求变化的可能性(比如又需要增加一个字段),相比于训练模型,后处理的逻辑会更容易调整。
3. paddle2onnx
ONNX(Open Neural Network Exchange)是一种针对机器学习所设计的开放式的文件格式,用于存储训练好的模型。它使得不同的人工智能框架,可以采用相同格式存储模型数据并交互。简而言之,ONNX相当于是一套统一的深度学习模型格式。基于这一套统一的格式,很多厂商的硬件和软件天然支持运行ONNX格式的模型。
关注飞桨的用户此前就应该了解到,Paddle Lite不仅可以支持飞桨原生模型部署,同时也支持PyTorch模型的部署,其技术路径就是通过PyTorch导出ONNX格式模型,再通过X2Paddle转换为飞桨模型格式进行部署。
安装
pip install paddle2onnx
静态图模型导出(Paddle2.0后主推动态图版本)
# Paddle模型的参数保存为多个文件(not combined)
paddle2onnx --model_dir paddle_model
--save_file onnx_file
--opset_version 10
--enable_onnx_checker True
# Paddle模型的参数保存在一个单独的二进制文件中(combined)
paddle2onnx --model_dir paddle_model
--model_filename model_filename
--params_filename params_filename
--save_file onnx_file
--opset_version
动态图版本
import paddle
from paddle import nn
from paddle.static import InputSpec
import paddle2onnx as p2o
class LinearNet(nn.Layer):
def __init__(self):
super(LinearNet, self).__init__()
self._linear = nn.Linear(784, 10)
def forward(self, x):
return self._linear(x)
layer = LinearNet()
# configure model inputs
x_spec = InputSpec([None, 784], 'float32', 'x')
# convert model to inference mode
layer.eval()
save_path = 'onnx.save/linear_net'
p2o.dygraph2onnx(layer, save_path + '.onnx', input_spec=[x_spec])
# when you paddlepaddle>2.0.0, you can try:
# paddle.onnx.export(layer, save_path, input_spec=[x_spec])
3.1. 实例:转换英文识别模型
# 注意:下载训练模型
wget -P ~/ch_lite/ https://paddleocr.bj.bcebos.com/dygraph_v2.0/multilingual/en_number_mobile_v2.0_rec_train.tar && tar xf ~/ch_lite/en_number_mobile_v2.0_rec_train.tar -C ~/ch_lite/
# 转换为inference预测模型
cd ~/PaddleOCR
python3 tools/export_model.py -c configs/rec/multi_language/rec_en_number_lite_train.yml -o Global.pretrained_model=/home/aistudio/ch_lite/en_number_mobile_v2.0_rec_train/best_accuracy Global.load_static_weights=False Global.save_inference_dir=/home/aistudio/inference_model/paddle/rec_en_crnn
# 转换为onnx模型
paddle2onnx -m /home/aistudio/inference_model/paddle/rec_en_crnn/ --model_filename inference.pdmodel --params_filename inference.pdiparams -s /home/aistudio/inference_model/onnx/rec_en_db/model.onnx --opset_version 11
注意,需要将model的目录修改,同时变更识别的字符集:
- rec_char_type
- rec_char_dict_path: 在
ppocr/utils/dict/目录下,如en_dict.txt。
参考PaddleOCR的源码 ppocr/postprocess/rec_postprocess.py :
support_character_type = [
'ch', 'en', 'EN_symbol', 'french', 'german', 'japan', 'korean',
'it', 'xi', 'pu', 'ru', 'ar', 'ta', 'ug', 'fa', 'ur', 'rs', 'oc',
'rsc', 'bg', 'uk', 'be', 'te', 'ka', 'chinese_cht', 'hi', 'mr',
'ne', 'EN'
]
if character_type == "en":
self.character_str = "0123456789abcdefghijklmnopqrstuvwxyz"
dict_character = list(self.character_str)
elif character_type == "EN_symbol":
# same with ASTER setting (use 94 char).
self.character_str = string.printable[:-6]
dict_character = list(self.character_str)
elif character_type in support_character_type:
self.character_str = ""
assert character_dict_path is not None, "character_dict_path should not be None when character_type is {}".format(
character_type)
with open(character_dict_path, "rb") as fin:
lines = fin.readlines()
for line in lines:
line = line.decode('utf-8').strip("
").strip("
")
self.character_str += line
if use_space_char:
self.character_str += " "
dict_character = list(self.character_str)
3.2. ONNXRunTime
参考上述教程,获取onnx模型。但项目依然依赖于paddle。为了解耦,做了以下工作:
-
从paddle项目中解耦
ppocr/data/imaug,这个项目用于图像增强。但实际onnx只需要调用其中的各种operators定义。无需
imgaug模块的安装(依赖scikit-image,项目庞大),但需要shapely的支持。而shapely又需要GEOS:
apt install libgeos-c1v5另,需要
pip install setuptools_scm pyclipper,一个图像分割时边缘关键点的处理工具,负责多边形裁剪(依赖setuptools_scm管理)。 -
从paddle项目中解耦
ppocr/post_process,这里主要是定义了多个模型的后处理器。可直接解除paddle框架的依赖。 -
挂载摄像头
-
优化内存和程序
嵌入式设备采用jetson_nano_2GB,运行时ONNX对模型的加载会占用300M左右的空间。程序本身运行并不吃力(相比于OpenCV_dnn的CUDA版本,内存被吃爆)。
最终运行起来,深度网络约占用了1.3GB的内存,无明显Swap消耗。
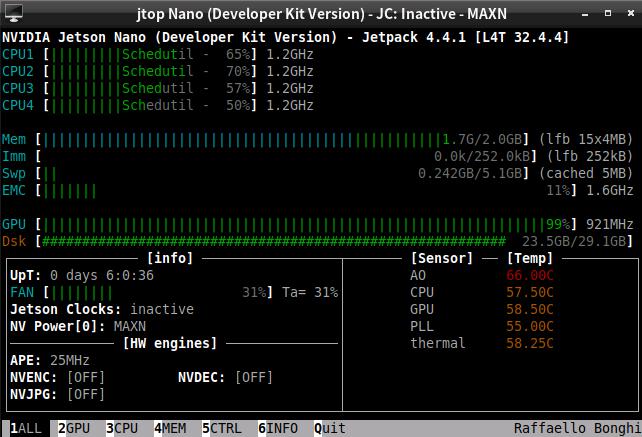
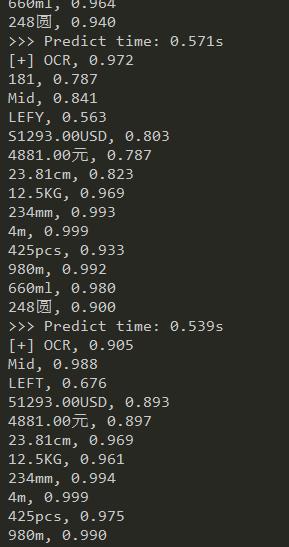
运行效果截图