1. 基本概念
1.1. 算法分类
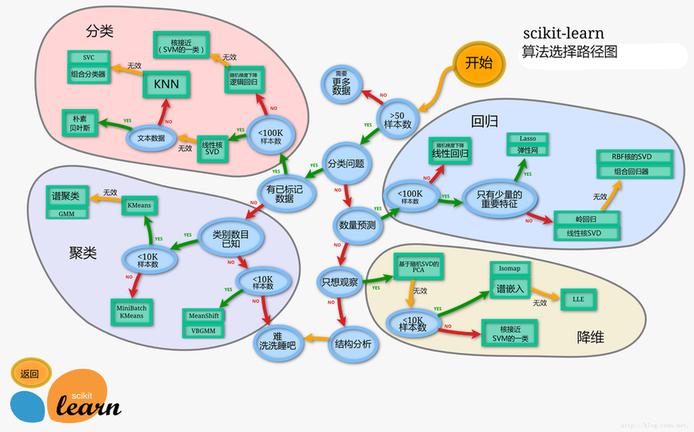
回归算法(药物反应,股票价格):
- 线性回归
- 逻辑回归
- 岭回归
分类算法(垃圾邮件检测,图像识别):
- k近邻(KNN)
- 贝叶斯
- 支持向量机(SVM)
- 决策树
- 随机森林
聚类,无监督学习算法(客户细分,分组实验结果):
- 聚类(k-Means)
- 谱聚类
- 均值漂移
降维(可视化,提高效率):
- PCA
- 特征选择
- 非负矩阵分解
1.2. 基本流程
预估器(估计器)estimator:sklearn机器学习算法的实现都属于estimator的子类,estimator定义了每一种算法模型的操作流:
-
划分训练集与测试集
from sklearn.model_selection import train_test_split X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=0) -
数据预处理
-
标准化
from sklearn.preprocessing import StandardScaler scaler = StandardScaler().fit(X_train) standardized_X = scaler.transform(X_train) standardized_X_test = scaler.transform(X_test) -
归一化
from sklearn.preprocessing import Normalizer scaler = Normalizer().fit(X_train) normalized_X = scaler.transform(X_train) normalized_X_test = scaler.transform(X_test) -
二值化
from sklearn.preprocessing import Binarizer binarizer = Binarizer(threshold=0.0).fit(X) binary_X = binarizer.transform(X) -
模型选择与构建
-
模型训练
clf = svm.SVC(gamma=0.001, C=100.) clf.fit(Xtrain, Ytrain) -
模型测试 & 评估
from sklearn.metrics import accuracy_score Ypred = clf.predict(Xtest) accuracy_score(Ytest, Ypred)或:
estimator.score(x_test, y_test) -
模型保存与加载
from sklearn.externals import joblib joblib.dump(clf, 'digits_svm.pk1') clf = joblib.load('digits_svm.pk1')
scikit所有的评估模型对象都有 fit() 这个接口,是用来训练模型的接口。针对有监督学习的机器学习,使用 fit(X,y) 来进行训练,其中y是标记数据。针对无监督的机器学习算法,使用 fit(X) 来进行训练,因为无监督机器学习算法的数据集是没有标记的,不需要传入y。
针对所有的监督学习算法,scikit模型对象提供了 predict() 接口,经过训练的模型,可以用这个接口来进行预测。针对分类问题,有些模型还提供了 predict_proba() 的接口,用来输出一个待预测的数据,属于各种类型的可能性,而 predict() 接口直接返回了可能性最高的那个类别。
几乎所有的模型都提供了 scroe() 接口来评价一个模型的好坏,得分越高越好。不是所有的问题都只有准确度这个评价标准,比如异常检测系统,一些产品不良率可以控制到10%以下,这个时候最简单的模型是无条件地全部预测为合格,即无条件返回1,其准确率将达99.999%以上,但实际上这是一个不好的模型。评价这种模型,就需要使用查准率和召回率来衡量。
针对无监督的机器学习算法,scikit的模型对象也提供了 predict() 接口,用来对数据进行聚类分析,把新数据归入某个聚类里。无监督学习算法还有 transform() 接口,这个接口用来进行转换,比如PCA算法对数据进行降维处理时,把三维数据降为二维数据,此时调用 transform() 算法即可把一个三维数据转换为对应的二维数据。
模型接口也是scikit工具包的最大优势之一,即把不同的算法抽象出来,对外提供一致的接口调用。
1.3. Pipeline
Pipeline可以将许多算法模型串联起来,可以用于把多个estamitors级联成一个estamitor,比如将特征提取、归一化、分类组织在一起形成一个典型的机器学习问题工作流。
Pipleline中,除最后一个之外的所有estimators都必须是变换器(transformers),最后一个estimator可以是任意类型(transformer,classifier,regresser)。如果最后一个estimator是个分类器,则整个pipeline就可以作为分类器使用;如果最后一个estimator是个聚类器,则整个pipeline就可以作为聚类器使用。