【问题】
在上一篇(https://www.cnblogs.com/bruceChan0018/p/15195706.html)的[缩小范围]这一部分中,末尾有句where查询时会出现慢查询的情况,今天来具体说明这种场景。
还是之前的表和100万+条数据,按照缩小范围的思路:
可以看到第1条和第3条的速度很慢,但是第2条的查询在可以接受的范围内。1可以理解,范围很大,但是第3条在确定了一个很小的范围之后为什么速度这么慢呢?
在有了第2条的速度之后,可以明确的是这跟limit后堆的大小已经没关系了。那么换一种写法: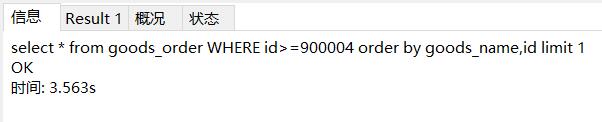
这一句和第3条的速度差不多,也就是说where后order by limit 1的速度很慢,这是为什么?并且在此过程中,我还发现语句的速度也不总是这么慢(更换了id的界定范围):

------------------------------------------------------------------------------------
【解决】
我们先用explain看看两个语句的执行计划:
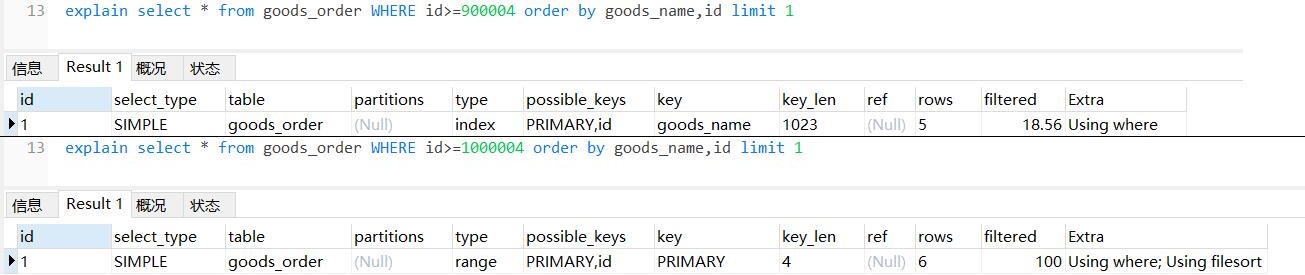
区别在于第1句使用了goods_name作为索引,而第2句使用了PRIMARY作为索引。当我们把两句查询的索引分别都指定为PRIMARY和goods_name时看看效果:
指定PRIMARY的情况:
指定goods_name的情况:
这里需要说明的是,真实环境中的查询语句在不同的配置以及优化器的作用下,表现出来的执行计划会很不相同。这里只提供了一种解决问题的思路,具体场景中的问题还是要进行具体地分析,这里的解决方案并不一定适合所有场景。
------------------------------------------------------------------------------------
【拓展】
我们看到了MySQL在自动查询优化时也并不是十全十美的,在复杂的场景中,我们有时候也要进行手动干预,MySQL本身也是提供了很多增强查询性能的选项:
0.查询缓存
在my.ini文件中设置query_cache_type=1时,在一定时间内可以使用历史查询的结果作为本次的查询结果,在对实时性要求不高的场景中可以这么做。此时可以设置临时关闭缓存的语句:
SELECT SQL_NO_CALHE * FROM TABLE1;
相应的,也可以将query_cache_type=2,此时必须在语句中指定是否使用cache:
SELECT SQL_CALHE * FROM TABLE1;
1.STRAIGHT_JOIN 强制连接顺序:
当我们将两个或多个表连接起来进行查询时,我们并不用关心MySQL先连哪个表,后连哪个表。而这一切都是由MySQL内部通过一系列的计算、评估,最后得出的一个连接顺序决定的。如下列的SQL语句中,TABLE1和TABLE2并不一定是谁连接谁:
SELECT TABLE1.FIELD1, TABLE2.FIELD2 FROM TABLE1 ,TABLE2 WHERE …
如果开发人员需要人为地干预连接的顺序,就得使用STRAIGHT_JOIN关键字,如下列的SQL语句:
SELECT TABLE1.FIELD1, TABLE2.FIELD2 FROM TABLE1 STRAIGHT_JOIN TABLE2 WHERE …
由上面的SQL语句可知,通过STRAIGHT_JOIN强迫MySQL按TABLE1、TABLE2的顺序连接表。如果你认为按自己的顺序比MySQL推荐的顺序进行连接的效率高的话,就可以通过STRAIGHT_JOIN来确定连接顺序。
2. 干预索引使用,提高性能
在上面已经提到了索引的使用。一般情况下,在查询时MySQL将自己决定是否使用索引,使用哪一个索引。但在一些特殊情况下,我们希望MySQL只使用一个或几个索引,或者不希望使用某个索引。这就需要使用MySQL的控制索引的一些查询选项。
--限制使用索引的范围
有时我们在数据表里建立了很多索引,当MySQL对索引进行选择时,这些索引都在考虑的范围内。但有时我们希望MySQL只考虑几个索引,而不是全部的索引,这就需要用到USE INDEX对查询语句进行设置。
SELECT * FROM TABLE1 USE INDEX (FIELD1, FIELD2) …
从以上SQL语句可以看出,无论在TABLE1中已经建立了多少个索引,MySQL在选择索引时,只考虑在FIELD1和FIELD2上建立的索引。
--限制不使用索引的范围
如果我们要考虑的索引很多,而不被使用的索引又很少时,可以使用IGNORE INDEX进行反向选取。在上面的例子中是选择被考虑的索引,而使用IGNORE INDEX是选择不被考虑的索引。
SELECT * FROM TABLE1 IGNORE INDEX (FIELD1, FIELD2) …
在上面的SQL语句中,TABLE1表中只有FIELD1和FIELD2上的索引不被使用。
--强迫使用某一个索引
上面的两个例子都是给MySQL提供一个选择,也就是说MySQL并不一定要使用这些索引。而有时我们希望MySQL必须要使用某一个索引(由于 MySQL在查询时只能使用一个索引,因此只能强迫MySQL使用一个索引)。这就需要使用FORCE INDEX来完成这个功能。
SELECT * FROM TABLE1 FORCE INDEX (FIELD1) …
以上的SQL语句只使用建立在FIELD1上的索引,而不使用其它字段上的索引。
3. 使用临时表提供查询性能
当我们查询的结果集中的数据比较多时,可以通过SQL_BUFFER_RESULT.选项强制将结果集放到临时表中,这样就可以很快地释放MySQL的表锁(这样其它的SQL语句就可以对这些记录进行查询了),并且可以长时间地为客户端提供大记录集。
SELECT SQL_BUFFER_RESULT * FROM TABLE1 WHERE …
和SQL_BUFFER_RESULT.选项类似的还有SQL_BIG_RESULT,这个选项一般用于分组或DISTINCT关键字,这个选项通知MySQL,如果有必要,就将查询结果放到临时表中,甚至在临时表中进行排序。
SELECT SQL_BUFFER_RESULT FIELD1, COUNT(*) FROM TABLE1 GROUP BY FIELD1
【参考】
拓展部份参考来自:https://www.cnblogs.com/sand-tiny/p/3977780.html