FACTORY 模式
——《敏捷软件开发 原则、模式与实践(c#版)》第29章
依赖倒置原则(DIP)告诉我们应该优先依赖于抽象类,而避免依赖于具体类。当这些具体类不稳定时,更应该如此。因此,下面的代码片段违反了这个原则:
Circle 是一个具体类。所以,创建 Circle 类实例的模块肯定违反了 DIP。事实上,任何一行使用了 new 关键字的代码都违反了 DIP。
有时,违反 DIP 是无害的。一个具体类越有可能会改变,依赖于它就越有可能引发问题。但是如果这个具体类是稳定的,那么依赖于它就不会出现麻烦。例如,创建 string 类的实例就不会带来麻烦。因为 string 类不可能会随时改变,所以依赖于它是很安全的。
但是,在一个正在进行的应用程序开发中,有很多具体类都是非常易变的。依赖于它们会带来问题。我们应当依赖于抽象接口,以使我们免受大多数变化的影响。
FACTORY 模式允许我们只依赖于抽象接口就能创建出具体对象的实例。所以,在正在进行的开发期间,如果具体类是高度易变的,那么该模式是非常有用的。
图1-1展示了一个有问题的场景。其中类 SomeApp 依赖于接口 Shape。SomeApp 完全通过 Shape 接口来使用 Shape 类的实例。它没有使用 Square 类或者 Circle 类的任何特定的方法。槽糕的是,SomeApp 也创建了 Square 和 Circle 的实例,因此就不得不依赖于这些具体类。
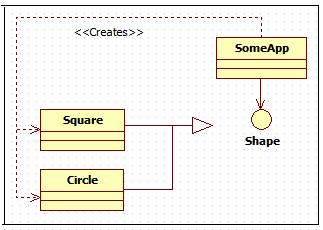
图1-1 一个违反了DIP原则创建具体类的应用程序
这个问题可以通过对 SomeApp 应用 FACTORY 模式来修正(如图1-2)。 其中我们看到了 ShapeFactory 接口。该接口中有两个方法:MakeSquare 和 MakeCircle。MakeSquare 方法返回一个 Square 类的实例。而 MakeCircle 方法返回一个 Circle 类的实例。不过,这二个函数返回值的类型都是Shape。

图1-2 在 SomeApp 中应用 FACTORY 模式
代码清单1-1 展示了 ShapeFactory 的代码。代码清单1-2 展示了 ShapeFactoryImplementation 的代码。
代码清单1-1 ShapeFactory.cs
{
Shape MakeCircle();
Shape MakeSquare();
}
代码清单1-2 ShapeFactoryImplementation.cs
{
public Shape MakeCircle()
{
return new Circle();
}
public Shape MakeSquare()
{
return new Square();
}
}
请注意,这完全解决了对具体类的依赖问题。应用程序代码不再依赖于 Circle 或者 Square,却仍然可以创建它们的实例。对这些实例的操作是通过 Shape 接口进行的,并且绝不会调用特定于 Square 或者 Circle 的方法。
依赖于具体类的问题已经解决了。虽然有人必须创建 ShapeFactoryImplementation,但是根本不需要创建 Square 或者 Circle。ShapeFactoryImplementation 往往由 Main 或者由一个隶属于 Main 的初始化函数创建出来的。
1.1 依赖问题
敏锐的读者会认识到这种形式的 FACTORY 模式存在一个问题。针对每个 Shape 的派生类,类 ShapeFactory 都要有一个对应的方法。这就产生了一个 仅仅名字上的依赖 问题,使得难以增加新的 Shape 派生类。每当增加一个新的 Shape 派生类时,都必须要向 ShapeFactory 接口中增加一个方法。在大多数的情况下,这意味着必须要重新编译、重新部署 ShapeFactory 的所有使用者(当然这在c#中不是完全必要的。可以不重新编译和重新部署一个被更改的接口的客户,但这是一个冒险行为。)。
通过牺牲一点类型安全性,可以解决这个依赖问题。我们可以只给 ShapeFactory 提供一个以 string 作为参数的 make 函数,而不是为每个 Shape 的派生类都在 ShapeFactory 中提供一个方法。请参加代码清单1-3.这项技术要求 ShapeFactoryImplementation 使用 if/else 链对传入的参数进行判断,选择出要实例化的 Shape 的派生类。如代码清单1-4和代码清单1-5
代码清单1-3 创建 Circle 实例的代码片段
public void TestCreateCircle()
{
Shape s = factory.Make("Circle");
Assert.IsTrue(s is Circle);
}
代码清单1-4 ShapeFactory.cs
{
Shape Make(string name);
}
代码清单1-5 ShapeFactoryImplementation.cs
{
public Shape Make(string name)
{
if(name.Equals("Circle"))
{
return new Circle();
}
else if(name.Equals("Square"))
{
return new Square();
}
else
{
throw new Exception("ShapeFactory cannot create:{0}",name);
}
}
}
有人也许会认为这样做是危险的,因为那些把 Shape 的名字拼错的调用者会得到一个运行期错误而不是一个编译期错误。这种想法是正确的。然而,如果编写了适当的单元测试并且应用测试驱动的开发方法,那么远在这些运行期错误成为问题之前就可以捕获到它们。
1.2 静态类型与动态类型
我们刚刚看到的关于类型安全和灵活之间的权衡很好地代表了目前关于语言风格的争论。 一边是静态类型语言,比如C#、C++和Java,它们是在编译期间进行类型检查的,当类型声明有不一致的地方时,就会触发编译错误。另一边是动态类型语言,比如Python、Ruby、Groovy和Smalltalk,它们在运行时进行类型检查,编译器并不强调类型的一致性,事实上,这些语言在语法上也没有对这种检查的支持。
正如我们在FACTORY 示例中看到的那样,静态类型会导致依赖问题,这种问题会迫使我们仅仅为了保持类型的一致性而去修改源文件。在我们的例子中,每当增加一个新的Shape 派生类时都必须得更改 ShapeFactory 接口。这种更改会迫使我们进行重新构建和重新部署工作,而如果不进行这种更改,这些工作则是没有必要做的。我们通过降低类型的安全性并使用单元测试来捕获类型错误的方法解决了这个问题;我们得到了无需更改 ShapeFactory 即可增加新的 Shape 派生类的灵活性。
静态类型语言的拥护者认为相对编译期的安全性来说,那些小的依赖问题、增加的源代码修改率以及增加的重新构建和重新部署率都是值得的。另以方则认为单元测试会找出绝打多数静态类型能够找出的问题,因此那些源代码修改、重新构建和重新部署的负担都是不要的。
我发现了有一点很有趣,那就是迄今为止,动态类型语言流行度是随着测试驱动开发(TDD)采用度的升高而升高的。也许,那些采用了 TDD 的程序员发现 TDD 改变了安全性和灵活性之间的平衡关系。也许,这些程序员逐渐确信了动态类型语言灵活性带来的好处要超过静态类型检查的好处。
也许,我们正处在静态类型语言最为流行的时代。但是,如果当前的趋势能够持续下去的话,我们就会发现下一个主要的工业语言更可能是 Smalltalk 而非 C++。
1.3 可替换的工厂
使用工厂的一个主要好处就是可以把工厂的一种实现替换为另一种实现。这样,就可以在应用程序中替换一系列相关的对象。
例如,如果一个应用程序必须要适应于许多不通的数据库实现。在本例中,假设用户既可以使用平面文件也可以购买一个Oracle 适配器。我们可以使用 PROXY 模式来隔离应用程序和数据库实现。我们还可以使用工厂来实例化一个代理对象。图1-3展示了这个结构
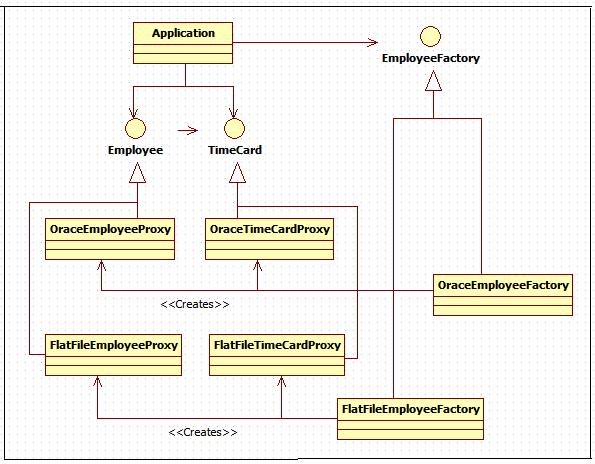
图1-3 可替换的工厂
请注意二个 EmployeeFactory 的实现。一个创建于平面文件一起工作的代理,另一个创建与Oracle 一起工作的代理。同样请注意,应用程序并不知道也不关心它在使用那一个实现。
1.4 对测试支架使用对象工厂
在编写单元测试时,通常希望把一个模块和它所使用的模块隔离,单独去测试该模块的行为。例如,有一个使用数据库的 Payroll 应用程序(图1-4)。我们可能希望在完全不使用数据库的情况下测试 Payroll 模块的功能。
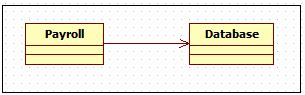
图1-4 Payroll 使用 DataBase
通过使用抽象的数据库接口, 可以到达这个目标。在这个抽象接口的一个实现中使用真正的数据库。在另一个实现中是测试代码,该测试代码模仿了数据库的行为,并且检查是否正确进行了数据库调用。图1-5展示了这个结构。PayrollTest 模块通过调用 payrollModule 来测试它。它也实现了 DataBase 接口。所以可以捕获到 Payroll 向数据库发出的调用。这就使得 PayrollTest 可以确保 Payroll 具有正确的行为。它同样也使得 PayrollTest 可以模仿多种类型的数据库失败和问题,而以别的方式则很难引发这些失败和问题。这是一个名为 SELF-SHUNT 的测试模式,有时也称为 mocking 或者 spoofing。

图1-5 PayrollTest 对数据库应用 SELF—SHUNT 模式
然而,Payroll 如何获得作为 DataBase 的 PayrollTest 的实例呢?当然,Payroll 不会去创建 PayrollTest。显然,Payroll 必须以某种方式获得它将要使用的 DataBase 实现的一个引用。
在某些情况下,PayrollTest 把 DataBase 的引用传递给 Payroll 是相当自然的。在另一些情况下,有可能 PayrollTest 必须设置一个全局变量保存对 DataBase 的引用。还有一些情况下,Payroll 可能完全期望自己来创建 DataBase 实例。在最后一种情况中,可以使用FACTORY 模式,通过传给 Payroll 另外一个工厂对象,来欺骗 Payroll 创建出 DataBase 的测试版本。
图1-6展示了一个可能的结构。Payroll 模块通过一个名为 GdatabaseFactory 的全局变量(或者全局类中的静态变量)来获取工厂。PayrollTest 模块实现了 DataBaseFactory 接口,并且把 GdatabaseFactory 设置为对自己的引用。当 Payroll 使用该工厂去创建 DataBase 实例时,PayrollTest 模块捕获这个调用并把指向自己的引用传回去。这样,Payroll 确信自己已经创建了 PayrollDatabase,而 PayrollTest 模块则可以完全欺骗 Payroll 模块并捕获所有的数据库调用。
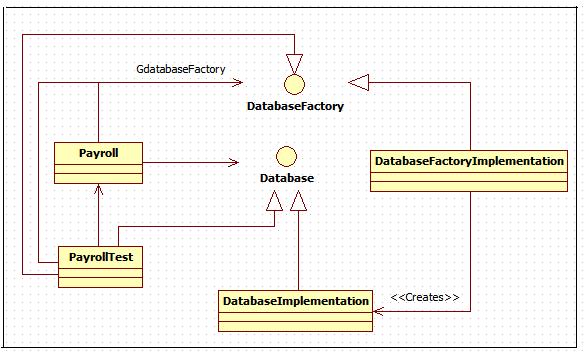
图1-6 欺骗对象工厂
1.5 工厂的重要性
严格按照 DIP 来讲,必须要对系统中的所有易变类使用工厂。此外,FACTORY 模式的威力也是诱人的。这两个因素有时会诱使开发者把工厂作为缺省方式使用。我不推荐这种极端的做法。
我不是一开始就使用工厂。只是在非常需要它们的情况下,我才把它们放入到系统中。例如,如果有必要使用 PROXY 模式,那么就可能有必要使用工厂去创建持久化对象。或者,在单元测试期间,如果遇到了必须要欺骗一个对象的创建者的情况时,那么我很可能会使用工厂。但是我不是一开始就假设工厂是必要的。
使用工厂会带来复杂性,这种复杂性通常是可以避免的,尤其是在一个正在演进的设计的初期。如果缺省的使用它们,就会极大地增加扩展设计的难度。为了创建一个新类,就必须要创建出4个新类,这4类是:2个表示该新类及其工厂的接口类, 2个实现这些接口的具体类。
1.6 结论
工厂是有效的工具。在遵循 DIP 方面工厂有着重大的作用。它们使得高层策略模块在创建类的实例是无需依赖于这些类的具体实现。它们同样也使得在一组类的完全不同系列的实现间进行交换成为可能。然而,使用工厂会带来复杂性,这种复杂性通常是可以避免的。缺省地使用它们通常不是最好的做法。
End.