
工作中sql是不可避免的应用,打好基础会提高工作效率
推荐一个在线练习的sql网站:https://sqlbolt.com/
sql select
SELECT column, another_column, …
FROM mytable
WHERE condition
AND/OR another_condition
AND/OR …;
SELECT column, another_column, …
FROM mytable
WHERE condition(s)
ORDER BY column ASC/DESC
LIMIT num_limit OFFSET num_offset;
SELECT column, another_column, …
FROM mytable
INNER/LEFT/RIGHT/FULL JOIN another_table
ON mytable.id = another_table.matching_id
WHERE condition(s)
ORDER BY column, … ASC/DESC
LIMIT num_limit OFFSET num_offset;
SELECT column, another_column, …
FROM mytable
WHERE column IS/IS NOT NULL
AND/OR another_condition
AND/OR …;

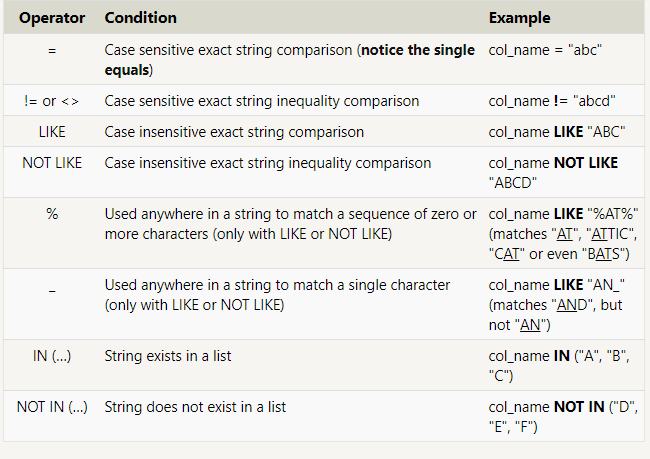
SELECT particle_speed / 2.0 AS half_particle_speed
FROM physics_data
WHERE ABS(particle_position) * 10.0 > 500;
SELECT column AS better_column_name, …
FROM a_long_widgets_table_name AS mywidgets
INNER JOIN widget_sales
ON mywidgets.id = widget_sales.widget_id;
SELECT AGG_FUNC(column_or_expression) AS aggregate_description, …
FROM mytable
WHERE constraint_expression;
SELECT AGG_FUNC(column_or_expression) AS aggregate_description, …
FROM mytable
WHERE constraint_expression
GROUP BY column;
SELECT group_by_column, AGG_FUNC(column_expression) AS aggregate_result_alias, …
FROM mytable
WHERE condition
GROUP BY column
HAVING group_condition;
SELECT DISTINCT column, AGG_FUNC(column_or_expression), …
FROM mytable
JOIN another_table
ON mytable.column = another_table.column
WHERE constraint_expression
GROUP BY column
HAVING constraint_expression
ORDER BY column ASC/DESC
LIMIT count OFFSET COUNT;

INSERT INTO mytable
(column, another_column, …)
VALUES (value_or_expr, another_value_or_expr, …),
(value_or_expr_2, another_value_or_expr_2, …),
…;
UPDATE mytable
SET column = value_or_expr,
other_column = another_value_or_expr,
…
WHERE condition;
DELETE FROM mytable
WHERE condition;
CREATE TABLE
CREATE TABLE IF NOT EXISTS mytable (
column DataType TableConstraint DEFAULT default_value,
another_column DataType TableConstraint DEFAULT default_value,
…
);
CREATE TABLE movies (
id INTEGER PRIMARY KEY,
title TEXT,
director TEXT,
year INTEGER,
length_minutes INTEGER
);
Altering table to add new column(s)
ALTER TABLE mytable
ADD column DataType OptionalTableConstraint
DEFAULT default_value;
Altering table to remove column(s)
ALTER TABLE mytable
DROP column_to_be_deleted;
Altering table name
ALTER TABLE mytable
RENAME TO new_table_name;
Drop table statement
DROP TABLE IF EXISTS mytable;
subqueries
SELECT *
FROM sales_associates
WHERE salary >
(SELECT AVG(revenue_generated)
FROM sales_associates);
SELECT *
FROM employees
WHERE salary >
(SELECT AVG(revenue_generated)
FROM employees AS dept_employees
WHERE dept_employees.department = employees.department);
Select query with subquery constraint
SELECT *, …
FROM mytable
WHERE column
IN/NOT IN (SELECT another_column
FROM another_table);
Select query with set operators
SELECT column, another_column
FROM mytable
UNION / UNION ALL / INTERSECT / EXCEPT
SELECT other_column, yet_another_column
FROM another_table
ORDER BY column DESC
LIMIT n;

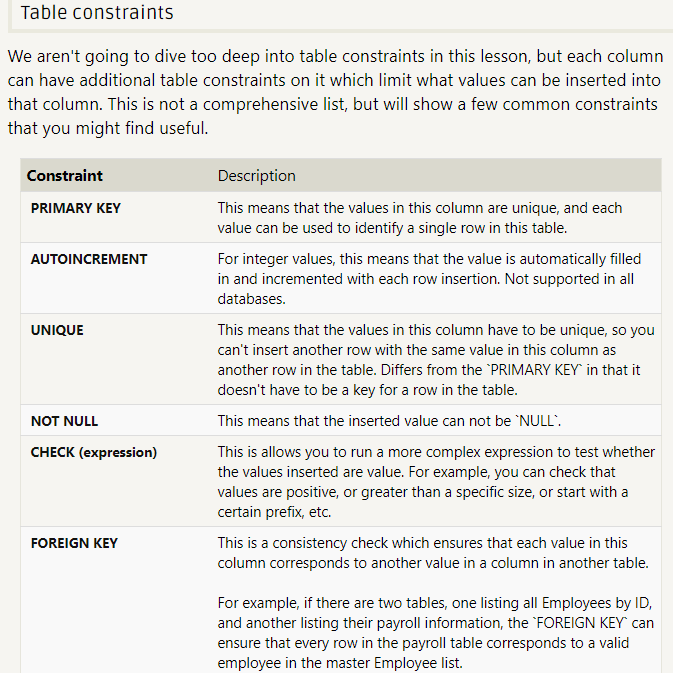
更新sql --
- duplicate
适合可能重复写入主键或唯一索引相同的值的时候,这样会更新其他的值而不会报错
下面两个表不会报错,用duplicate 没用
r_cms_online_result 主键id order_no , 索引 order_no 会写入重复的order_no 不报错
r_cms_complain_detail 主键id, 索引 register_time order_no 会写入重复的order_no 不报错
INSERT INTO table (column_list)
VALUES (value_list)
ON DUPLICATE KEY UPDATE
c1 = v1,
c2 = v2,
...;
https://stackoverflow.com/questions/548541/insert-ignore-vs-insert-on-duplicate-key-update
在有主键时:replace 会删除旧的生成新的一行,而duplicate不会
2. union
select count(*),'0' as stat from midatadb.r_nfis_record_time where status=0 and save_time BETWEEN 1547481600000 and 1547568000000
union
select count(*),'1' from midatadb.r_nfis_record_time where status=1 and save_time BETWEEN 1547481600000 and 1547568000000
- update .. join ,用子查询insert时报错
update midatadb.r_nfis_record_time a
join midatadb.r_application b on a.uid=b.uid
set a.status=2
where a.status=0 and b.country_id=3 and b.status=4;
update midatadb.r_nfis_record_time set status=1 where status=0 and uid in
(select ra.uid from midatadb.r_application ra
join midatadb.r_nfis_record_time rt on ra.uid=rt.uid where ra.country_id=3 and ra.status=7)
- delete 和join结合
删除rp的数据,条件在ra中
delete rp from midatadb.r_pic_verify_assigned rp join midatadb.r_application ra on rp.application_id=ra.id where status in (7,8);
- 使用case 分类统计
select FROM_UNIXTIME(atime/1000,'%Y%m%d') as some,count(*),
count(case when status=1 then 1 else null end) one,
count(case when status=12 then 1 else null end) t12,
count(case when status=13 then 1 else null end) t13,
count(case when status=4 then 1 else null end) t4,
count(case when status=5 then 1 else null end) t5,
count(case when status=7 then 1 else null end) t7,
count(case when status=8 then 1 else null end) t8,
count(case when reject_type=1 then 1 else null end) reject1,
count(case when reject_type=3 then 1 else null end) reject3
from table.whichone
where atime >UNIX_TIMESTAMP('20190705') * 1000 and country_id=4 group by 1;
- 关于 字段类型是 decimal, datetime 等这些查出来是带了类型的,在做运算时要注意先处理 如 float(decimal)
- NULL查询出来在python中是None ,注意直接转换类型时会报错。
- 使用CONCAT 和 IFNULL 来拼接字段, 字段间可以做运算
sql = """select tu.uid relate_uid, phone_number phone_no, `value` id_no, tu.create_time register_time,
ifnull(first_name, "") first_name, ifnull(middle_name, "") middle_name, ifnull(last_name, "") last_name
from installmentdb.t_user tu join
installmentdb.t_user_authentication tua on tu.uid=tua.uid where entry_id=%s """
name_d = {"name": " ".join([data[0]["first_name"], data[0]["middle_name"], data[0]["last_name"]])}
改变为一句sql就可以
sql = """select tu.uid relate_uid, phone_number phone_no, `value` id_no, tu.create_time register_time,
concat(ifnull(first_name,''), ifnull(middle_name,''), ifnull(last_name,'')) `name`
from installmentdb.t_user tu join
installmentdb.t_user_authentication tua on tu.uid=tua.uid where entry_id=%s """
https://segmentfault.com/a/1190000008304821
SQL中AVG()、COUNT()、SUM()等函数对NULL值处理
AVE()忽略NULL值
COUNT(*) 对表中行数进行计数, 不管是否有NULL
COUNT(字段名)
对特定列有数据的行进行计数
忽略NULL值
SUM()
可以对单个列求和,也可以对多个列运算后求和
忽略NULL值,且当对多个列运算求和时,如果运算的列中任意一列的值为NULL,则忽略这行的记录。
例如: SUM(A+B+C),A、B、C 为三列,如果某行记录中A列值为NULL,则不统计这行。
为空的判断
is null/ is not null
Mysql写出高质量的sql语句的几点建议
建议一:尽量避免在列上运算,日期运算,+-*/
select * from system_user where date(createtime) >= '2015-06-01' ==>
select * from system_user where createtime >= '2015-06-01'
select * from system_user where age + 10 >= 20
select * from system_user where age >= 10
建议二:用整型设计索引
用整型设计的索引,占用的字节少,相对与字符串索引要快的多。特别是创建主键索引和唯一索引的时候。 1)设计日期时候,建议用int取代char(8)。例如整型:20150603。 2)设计IP时候可以用bigint把IP转化为长整型存储。
建议三:join时,使用小结果集驱动大结果集
使用join的时候,应该尽量让小结果集驱动大的结果集,把复杂的join查询拆分成多个query。因为join多个表的时候,可能会有表的锁定和阻塞。如果大结果集非常大,而且被锁了,那么这个语句会一直等待
select * from table_a a
left join table_b b on a.id = b.id
left join table_c c on a.id = c.id
where a.id > 100 and b.id < 200
select * from (select * from table_a where id > 100) a
left join(select * from table_b where id < 200 )b
on a.id = b.id left join table_c on a.id = c.id
建议四:使用批量插入节省交互
insert into (x,y,z) values(1,2,3), (4,5,6)
建议五:多习惯使用explain分析sql语句,多使用profiling分析sql语句时间开销
参考:https://blog.csdn.net/CleverCode/article/details/46310835
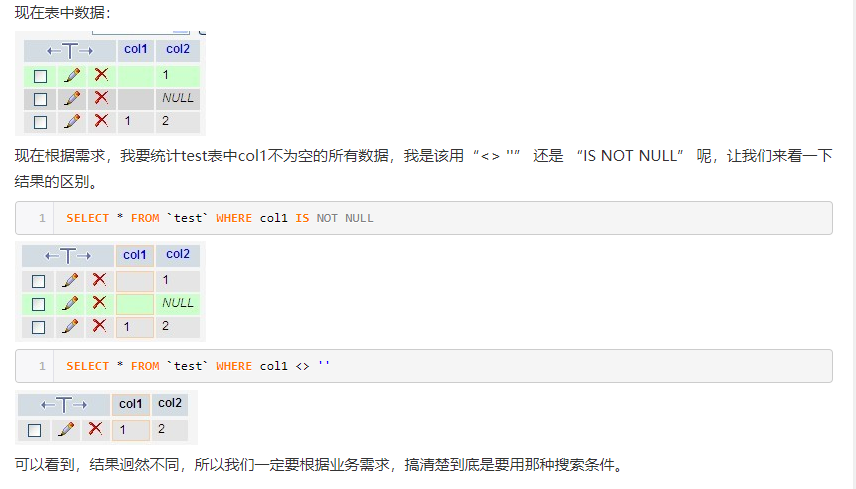
null 和空的区别
1、空值是不占用空间的
2、mysql中的NULL其实是占用空间的
NOT NULL 的字段是不能插入“NULL”的,只可能插入“空值”
时间戳转时间的处理
- 使用 FROM_UNIXTIME(application_time/1000,'%Y-%m-%d') 手动格式化
使用举例:
select count(*),FROM_UNIXTIME(create_time/1000,'%Y%m%d') as date,
count(case when status=0 then 1 else null end) 0wait,
count(case when status=1 then 1 else null end) 1reject,
count(case when status=2 then 1 else null end) 2pass,
count(case when status=3 then 1 else null end) 3nodata
from midatadb.r_nfis_record_time where create_time>1555718400000 group by 2;
- 使用函数(也可以完成格式化到年月日)
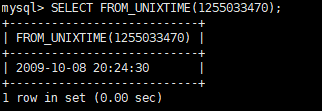
使用date 到日
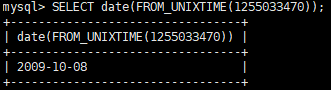
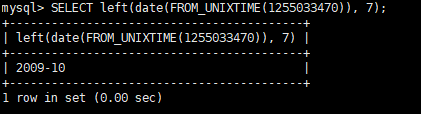
使用 left 保留到年或月
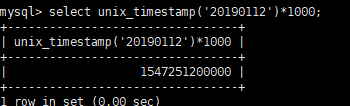
使用 unix_timestamp可以转时间戳
key = str(datetime.date.today() - datetime.timedelta(days=i))
recent_30[key] = {}
new = await db_conn.select_one_value(
"""select count(*) from midatadb.r_cms_complain_detail where
FROM_UNIXTIME(register_time/1000, "%%Y-%%m-%%d") = %s""", [key]
) or 0
修改字段
mysql修改字段类型:
--能修改字段类型、类型长度、默认值、注释
--对某字段进行修改
ALTER TABLE 表名 MODIFY COLUMN 字段名 新数据类型 新类型长度 新默认值 新注释; -- COLUMN可以省略
alter table table1 modify column column1 decimal(10,1) DEFAULT NULL COMMENT '注释'; -- 正常,能修改字段类型、类型长度、默认值、注释
mysql修改字段名:
ALTER TABLE 表名 CHANGE 旧字段名 新字段名 新数据类型;
alter table table1 change column1 column1 varchar(100) DEFAULT 1.2 COMMENT '注释'; -- 正常,此时字段名称没有改变,能修改字段类型、类型长度、默认值、注释
alter table table1 change column1 column2 decimal(10,1) DEFAULT NULL COMMENT '注释' -- 正常,能修改字段名、字段类型、类型长度、默认值、注释
alter table table1 change column2 column1 decimal(10,1) DEFAULT NULL COMMENT '注释' -- 正常,能修改字段名、字段类型、类型长度、默认值、注释
原文链接:https://blog.csdn.net/u010002184/article/details/79354136