https://www.youtube.com/watch?v=Ilg3gGewQ5U
What is backpropagation really doing?
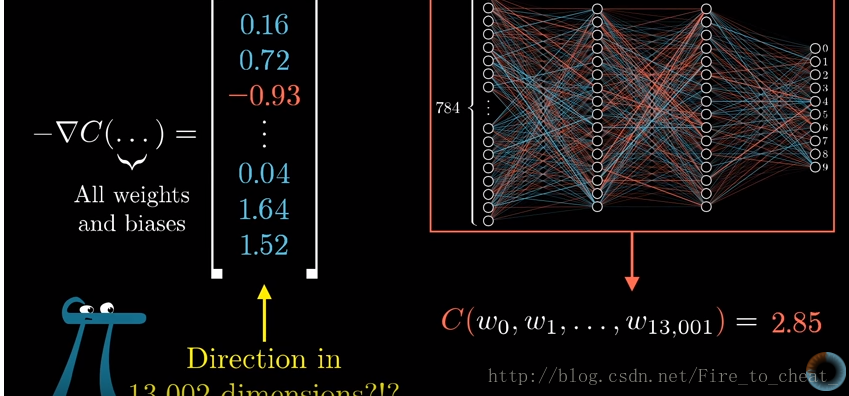
梯度向量的每一项大小是在告诉大家,代价函数对于每一个参数有多敏感。
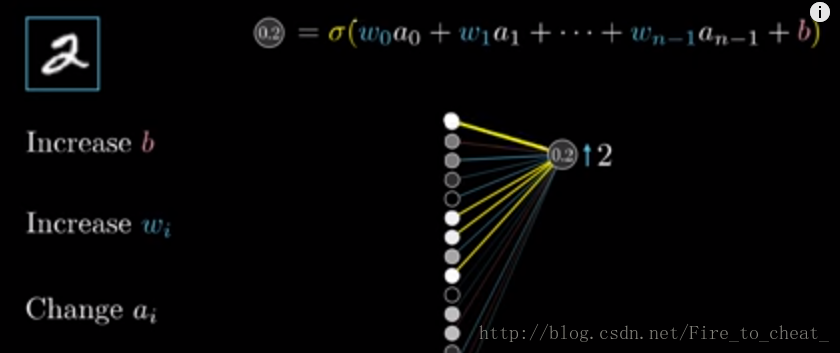
对于改变激活值,可以有三种方法:
1.增加偏置
2.增加权重
3.改变上一层的激活值
对于梯度下降,我们不知看每个参数是该增大还是减小,我们还看哪个参数的性价比最高。
反向传播的原理
把最后一层的神经元期待全部加起来,作为对如何改变倒数第二层神经元的指示,这些期待变化不仅是权重的倍数,也是每个神经元激活值改变量的倍数,这就是反向传播的实现原理。我们把所有期待的改变加起来,就得到了一串对倒数第二层改动的变化量。有了这些,我们就可以重复这个过程,改变影响倒数第二层神经元激活值的相关参数,从后一层带前一层,把这个过程一直循环到第一层。
小结
反向传播(backpropagation)算法算的是单个训练样本想怎样修改权重和偏置,不仅是说每个参数应该变大还是变小,还包括了这些变化的比例是多大,才能最快的降低代价。
真正的梯度下降,得对好几万个训练样本都这么操作。然后对这些变化值取平均,但是这样算起来太慢了。所以可以先把所有的样本分到各个minibatch中,计算一个minibatch来作为梯度下降的一步,计算每一个minibatch的梯度,来调整参数,不断循环。最终你就会收敛到代价函数的一个局部最小值上。