参考:
https://zh.wikipedia.org/wiki/%E4%B8%80%E8%87%B4%E5%93%88%E5%B8%8C
1、概念
一致哈希 是一种特殊的哈希算法。在使用一致哈希算法后,哈希表槽位数(大小)的改变*均只需要对


2、问题
在使用n台缓存服务器来缓存m个资源时,一种常用的负载均衡方式是,对资源o的请求使用hash(o) = o mode n 来映射到某一台缓存服务器,这种方法可以有效的将m资源请求均衡的分散在n个节点。

代码示例:
void hash_test(){ int items = 1000000; int nodes = 10; int node_stat[nodes]; long hash_key = 0; for(int i = 0;i < items;i++){ char buf[128]; snprintf(buf,127,"%s-00%d","object",i); hash_key = conhash_hash_fun_md5(buf); node_stat[hash_key%nodes]++; } int avg = items/10; int max = get_max(node_stat,nodes); int min = get_min(node_stat,nodes); printf("avg valus is %d ",items/nodes); printf("max valus is %d (%2.2f %%) ",max,max*100.0/avg); printf("min valus is %d (%2.2f %%) ",min,min*100.0/avg); }
输出结果:
avg valus is 100000
max valus is 1000515 (100.52 %)
min valus is 99271 (99.27 %)
从上面的输出结果我们可以看出10000个资源几乎是均匀散落在10个节点上面,每个节点散落的资源和*均值的差值都在1%之内。
但是该方法会带来比较严重的后果,就是当增加或减少一台缓存服务器时这种方式可能会改变所有资源对应的hash值,也就是所有的缓存都失效了,这会使得缓存服务器大量集中地向原始内容服务器更新缓存。
代码示例:
int items = 1000000; int nodes = 10; int nodes2 = 11; long hash_key = 0; int change = 0; for(int i = 0;i < items;i++){ char buf[128]; snprintf(buf,127,"%s-00%d","object",i); hash_key = conhash_hash_fun_md5(buf); if((hash_key % nodes) != (hash_key % nodes2)) change++; } printf("%d (%2.3f%%) ",change,change*100.0/items);
输出结果:
change is 909144 (90.914%)
从上面的结果我们可以看到一当增加(或减少)了一个节点,超过90%的缓存改变了其散落的节点,也就是说超过90%的缓存数据需要做迁移。
需要一种新的算法来避免这样的问题,该算法尽可能使得同一个资源映射到同一个节点上。这种方式要求增加一个节点时候,新的节点尽量分担存储其他节点缓存的资源。减少一台服务器时候,其他节点也可以尽量分担存储资源。
3、一致性哈希
一致哈希将每个对象映射到圆环边上的一个点,系统再将可用的节点机器映射到圆环的不同位置。查找某个对象对应的机器时,需要用一致哈希算法计算得到对象对应圆环边上位置,沿着圆环边上查找直到遇到某个节点机器,这台机器即为对象应该保存的位置。 当删除一台节点机器时,这台机器上保存的所有对象都要移动到下一台机器。添加一台机器到圆环边上某个点时,这个点的下一台机器需要将这个节点前对应的对象移动到新机器上。 更改对象在节点机器上的分布可以通过调整节点机器的位置来实现。
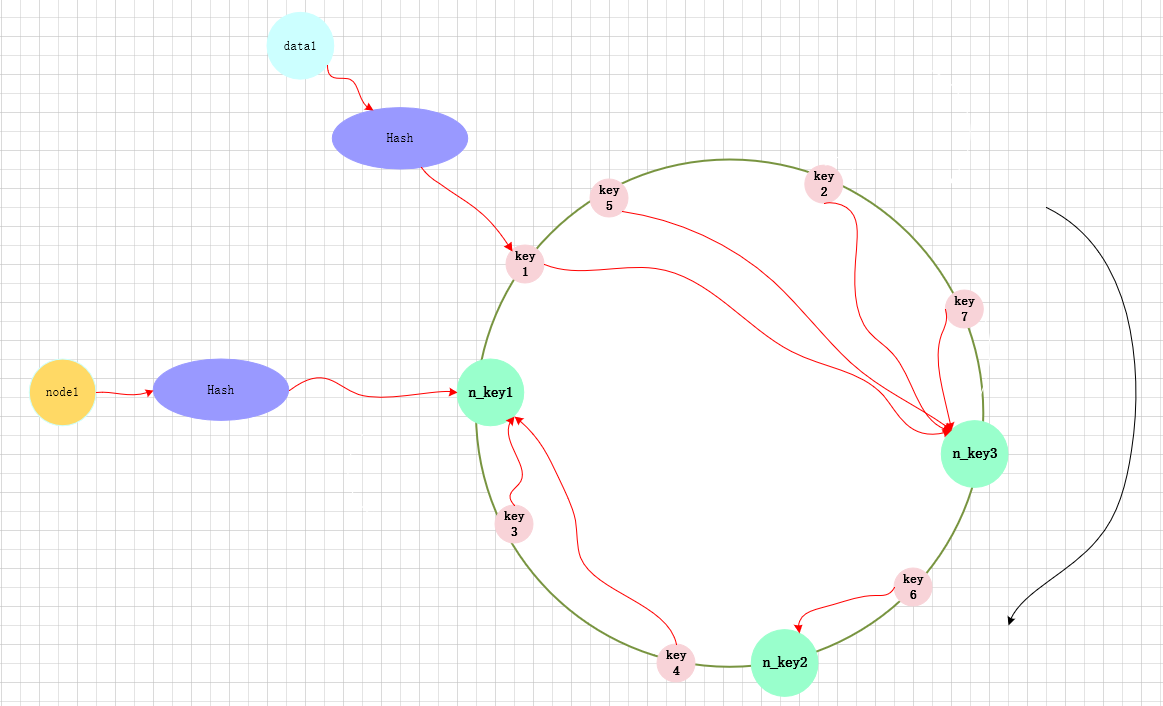
增加一个节点:

减少一个节点:
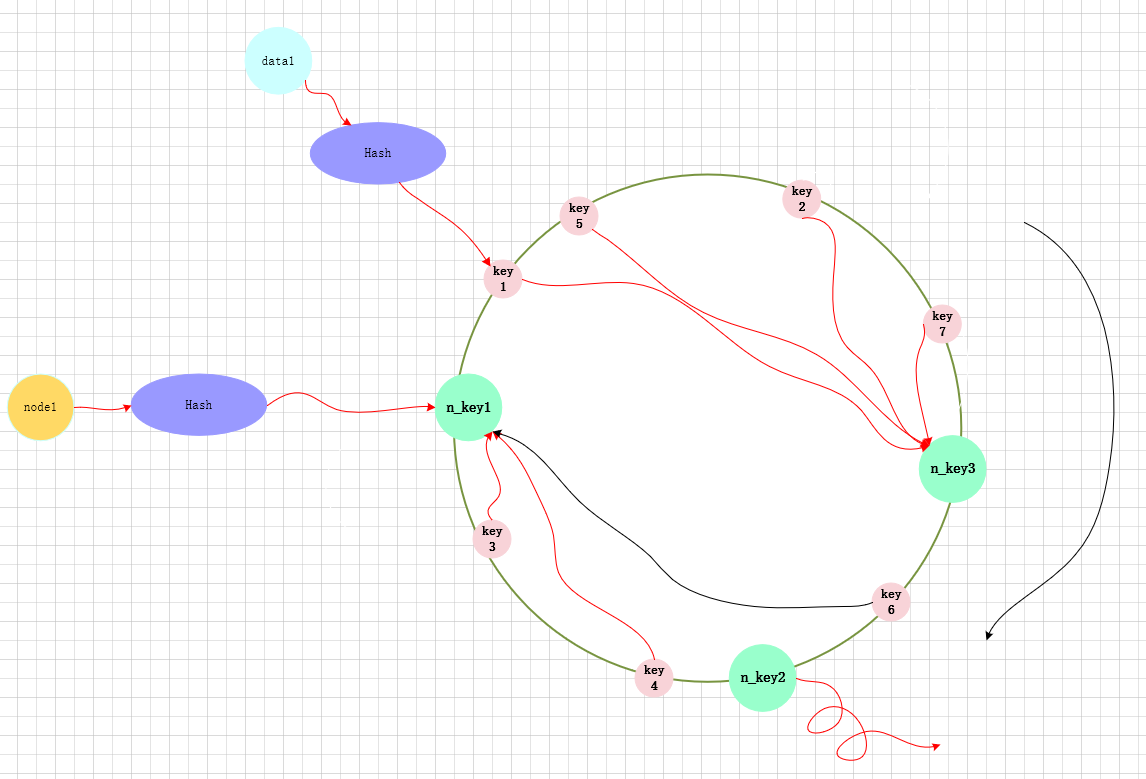
代码示例:
char *nodes[]={"node1","node2","node3","node4","node5","node6","node7","node8","node9","node0"}; int node_stat[10] = {0}; int items = 1000000; conhash_t *conhash = conhash_init(NULL,nodes,10,1); if(conhash == NULL) return ; for(int i = 0;i < items;i++){ char buf[128]; snprintf(buf,127,"%s-00%d","object",i); node_t *node = conhash_lookup(conhash,buf); for(int j = 0;j < 10;j++){ if(strcmp(node->iden,nodes[j]) == 0) node_stat[j]++; } } int avg = items/10; int max = get_max(node_stat,10); int min = get_min(node_stat,10); printf("avg valus is %d ",items/10); printf("max valus is %d (%2.2f%%) ",max,max*100.0/avg); printf("min valus is %d (%2.2f%%) ",min,min*100.0/avg); conhash_free(conhash);
输出:
avg valus is 100000
max valus is 407371 (407.37%)
min valus is 8367 (8.37%)
char *nodes[]={"node0","node1","node2","node3","node4","node5","node6","node7","node8","node9"}; //char *nodes2[]={"node10","node1","node2","node3","node4","node5","node6","node7","node8","node9","uuuuzzz0000"}; char *nodes2[]={"node0","node1","node2","node3","node4","node5","node6","node7","node8","node9","node10"}; int items = 1000000; int nodes_num = 10; int nodes2_num = 11; int change = 0; conhash_t *conhash = conhash_init(NULL,nodes,nodes_num,1); if(conhash == NULL) return ; conhash_t *conhash2 = conhash_init(NULL,nodes2,nodes2_num,1); if(conhash2 == NULL){ free(conhash); return ; } for(int i = 0;i < items;i++){ char buf[128]; snprintf(buf,127,"%s-00%d","object",i); node_t *node = conhash_lookup(conhash,buf); node_t *node2 = conhash_lookup(conhash2,buf); if(strcmp(node->iden,node2->iden) != 0) change++; } printf("change %d (%2.2f%%) ",change,change*100.0/items);
输出:
change 26133 (2.61%)
显然使用了一致性哈希之后缓存改变了其散落的节点明显的减少了(注:这个改变的数量应该在item/nodes振幅之中,目前为止这个振幅其实是相对较大,题注在做实验时改变的节点比率有出现1%一下的也有20以上),但是其资源散落的非常不均匀,实际上以上两个问题时间上都是由于节点散落不均匀导致的问题。
为了改进以上这个问题,一致性哈希有引进了虚拟节点,将一个真实节点映射成多个虚拟节点,在将虚拟节点映射到Hash换上。
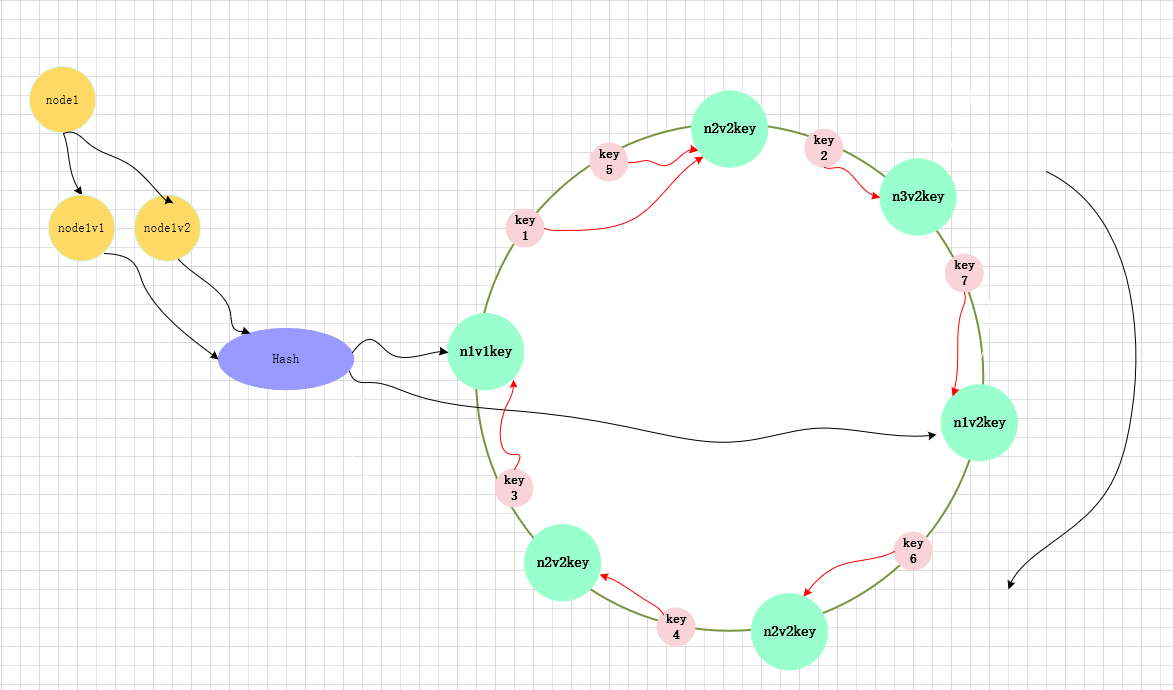
使用虚拟节点之后,测试的输出为:
avg valus is 100000
max valus is 114414 (114.41%)
min valus is 77407 (77.41%)
change 98665 (9.87%)
散落的均匀性虽然没有普通的hash好,但是基本上是一个可以接受的数据,并且随这副本数的增大,也将各个节点散落的资源也越趋*于*均值。
而改变的数目基本上也将达到items/nodes,其振幅也同样随副本数而大大减少。