开胃菜——同步和异步
举个栗子:你叫我去吃饭,我听到了就立刻和你去吃饭,如果我没听到,你就一直叫我,直到我听见和你一起去吃饭,这个过程叫同步;异步过程指你叫我去吃饭,然后你就去吃饭了,而不管我是否和你一起去吃饭。而我得到消息后可能立即就走,也可能过段时间再走。
官方解释:
同步是指:发送方发出数据后,等接收方发回响应以后才发下一个数据包的通讯方式。
异步是指:发送方发出数据后,不等接收方发回响应,接着发送下个数据包的通讯方式
初始化进程、线程与协成的概念
什么是进程?
进程,是计算机中的程序关于某数据集合上的一次运行活动,是系统进行资源分配和调度的基本单位,是操作系统结构的基础。前面的话我也没懂,用非官方的白话来解释就是——执行中的程序是进程,比如qq不是进程,但是当我们双击qq开始使用它的时候,它就变成了一个进程。我们写的Python程序,只有当我们执行它的时候,它才是进程。我们正在执行的IE浏览器,QQ,Pycharm都是进程,从操作系统的角度来讲,每一个进程都有它自己的内存空间,进程之间的内存是独立的。
什么是线程?
线程,有时候被称为轻量级进程,是程序执行流的最小单元。我们可以理解为,线程是属于进程的,我们平时写的简单程序,是单线程的,多线程和单线程的区别在于多线程可以同时处理多个任务,这时候我们可以理解为多线程和多进程是一样的,我可以在我的进程中开启一个线程放音乐,也可以开启另外的线程聊QQ,但是进程之间的内存独立,而属于同一个进程多个线程之间的内存是共享的,多个线程可以直接对它们所在进程的内存数据进行读写并在线程间进行交换。
进程与线程之间的关系
先推荐一个连接,这篇文章用漫画的形式讲解了进程与线程的关
系:http://www.ruanyifeng.com/blog/2013/04/processes_and_threads.html
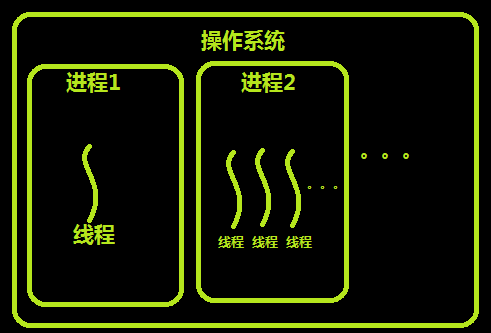
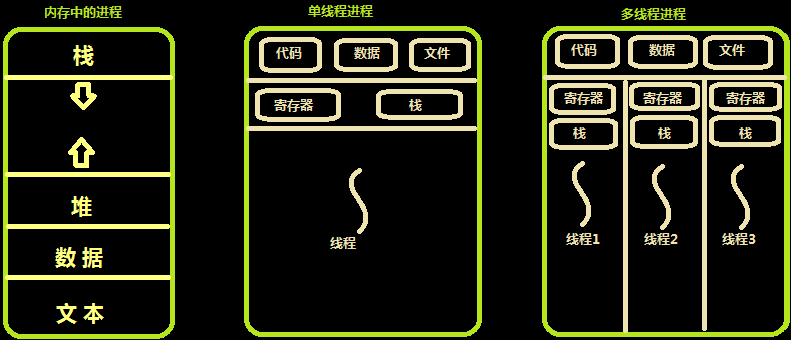
如上图,假装我们已经看完了上面的链接,这里来为偷懒的同志们解释一下,上图为进程与线程之间的关系。每个进程都有属于自己的线程,至少一个。下图为进程、单线程进程、多线程进程在内存中的情况。
关于python线程的那个传说:
在python界一直有着一个古老的传说,那就是python的多线程是鸡肋,那么这个传说的信度到底有多少呢?如果我们的代码是CPU密集型(涉及到大量的计算),多个线程的代码很有可能是线性执行的,所以这种情况下多线程是鸡肋,效率可能还不如单线程,因为有context switch(其实就是线程之间的切换和线程的创建等等都是需要消耗时间的);但是:如果是IO密集型,多线程可以明显提高效率。例如制作爬虫,绝大多数时间爬虫是在等待socket返回数据。这个时候C代码里是有release GIL的,最终结果是某个线程等待IO的时候其他线程可以继续执行。
那么,为什么我们大python会这么不智能呢?我们都知道,python是一种解释性语言,在python执行的过程中,需要解释器一边解释一边执行,我们之前也介绍了,同一个进程的线程之间内存共享,那么就会出现内存资源的安全问题,python为了线程安全,就设置了全局解释器锁机制,既一个进程中同时只能有一个线程访问cpu。作为解释型语言,python能引入多线程的概念就已经非常不易了,目前看到的资料php和perl等多线程机制都是不健全的。解释型语言做多线程的艰难程度可以想见。。。具体下面的链接推荐:python的最难问题。
正是由于python多线程的缺陷,我们在这里需要引入协成的概念。
什么是协程?
协程是一种用户态的轻量级线程。如果说多进程对应多CPU,多线程对应多核CPU,那么事件驱动和协程则是在充分挖掘不断提高性能的单核CPU的潜力。我们既可以利用异步优势,又可以避免反复系统调用,还有进程切换造成的开销,这就是协程。协程也是单线程,但是它能让原来要使用异步+回调方式写的非人类代码可以用看似同步的方式写出来。它是实现推拉互动的所谓非抢占式协作的关键。对于Python来说,由于Python多线程中全局解释器导致的同时只能有一个线程访问CPU,所以对协程需求就相比于其他语言更为紧迫。一句话:单线程下实现并发。
进程、线程与协程
从硬件发展来看,从最初的单核单CPU,到单核多CPU,似乎已经到了极限了,但是单核CPU性能却还在不断提升。server端也在不断的发展变化。如果将程序分为IO密集型应用和CPU密集型应用,二者的server的发展如下:
IO密集型应用:多进程->多线程->事件驱动->协程
CPU密集型应用:多进程-->多线程
调度和切换的时间:进程 > 线程 > 协程
以下是关于进程、线程、协程的关键字和相关模块的解释:
进程:
1 、进程和程序的区别:程序就只是一段代码,在硬盘上的一堆文件,进程就时正在运行的程序的过程,进程是有优先级的过程。
2、(1)什么是并发:看起来是多个程序一起执行,但其实是每个程序在内存中切换着执行。
(2)什么是并行:同时多个CPU同时执行多个程序。
(3)什么是串行:一个程序执行完后才能执行其他的程序。
3、(1)阻塞:卡住,就是在执行一个程序的时候,需要从硬盘中寻找一些资料,在寻找资料的同时会将程序挂起,这个停止的过程就是阻塞。
(2)非阻塞:没有被卡住,一个程序启动,需要的资料已经全部读到了内存,不需要再去从硬盘中寻找,直接执行出了程序的结果,这就叫做非阻塞。
(3)阻塞和非阻塞针对的就是进程和线程,阻塞就是将程序挂起,非阻塞就是不会挂起当前的进程。
4、multiprocessing模块: 多进程模块
5、Process:multiprocessing模块下的一个类,开启进程
6、target=:Process里面的一个方法,后面跟要开启的进程名
7、 args:后面是传入的参数以元组的格式
8、 kwargs:传入参数,以字典的格式
9、 start:执行子程序
基本格式:子进程=multiproceessing.Process(target=进程,args=(参数,))
子进程.start()
两种进程方式
例1

例2
10、僵尸进程:在子进程没有执行完,而主进程已经挂掉了,而这些还没有执行完的子进程就是僵尸进程
11、谁启动谁就是主进程的父ID
12、主进程和父进程都有自己的内存空间。
13、join:等待子进程执行完过后再执行主进程。
14、termainate:干掉进程。
15、is_alive:是否已干掉进程
16、name:进程名
17、pid:进程ID
socketserver模块:只用于服务端,服务端利用多线程实现并发,使用方法:在服务端创建一个类,而类下面必须要有一个handle方法。如下:
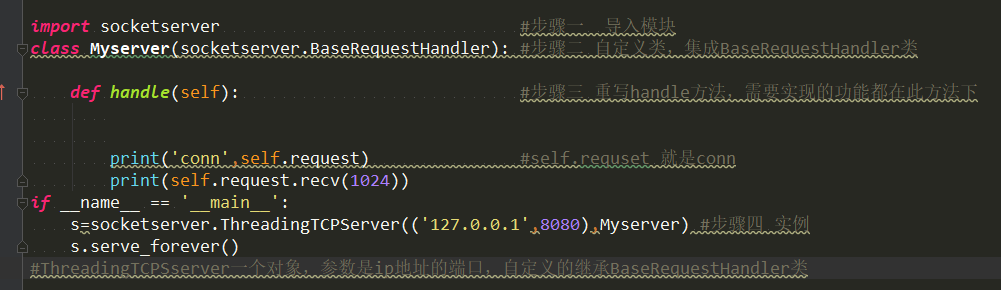
详情:http://www.cnblogs.com/kellyseeme/p/5525023.html
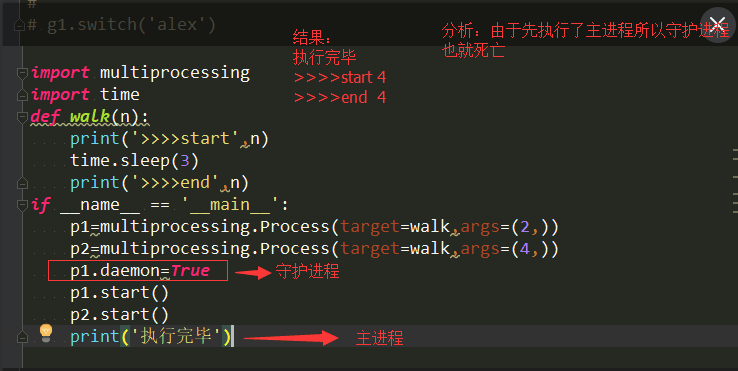
18、守护进程:守护进程就是辅助主程序代码的执行,主程序的代码执行完毕后,守护进程就没有存在的必要,所以守护进程会在主程序代码执行完毕之后自动终止。
daemon=True:创建守护进程,daemon默认等于False。
例1:
例2:

例3

注意:进程与进程之间是相互独立的,只要主进程中的代码没有执行完,守护进程中的代码还是会执行的。
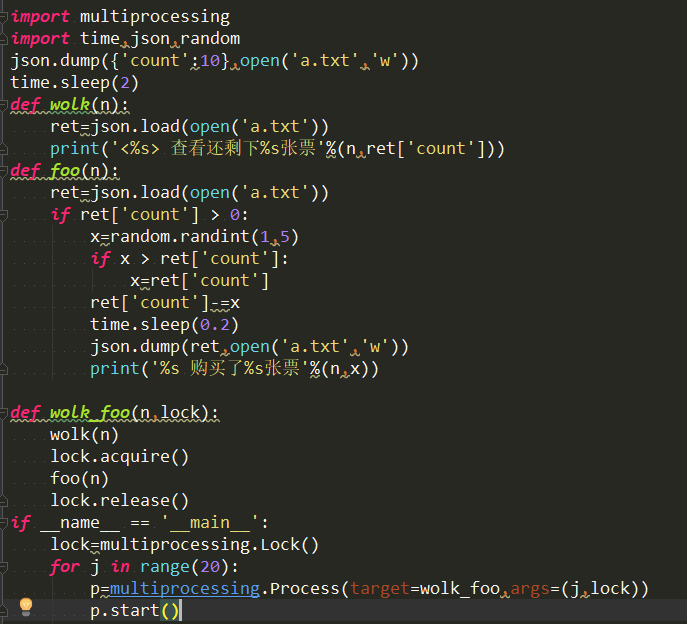
19、同步锁也叫互斥锁
同步锁的作用:把并发变成串行,将竞争变的有序化
Lock:锁
acquire:加上锁
release:解锁
如下:
with 锁:自动加上锁,执行完毕后自动解开锁。如下:
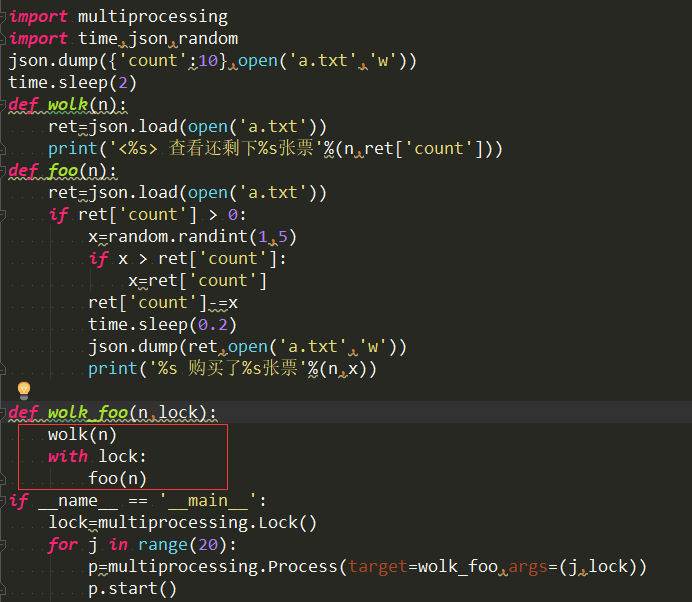
加上锁是为了实现串行,保证代码的安全性,但是减低了代码的执行率
注意:在这两个实例中,最开始dump文件的时候是需要一段时间的(也就是I/O阻塞),所以在dump文件的后停一段时间,假如不加上停顿时间,文件数据就会错乱或者报错。
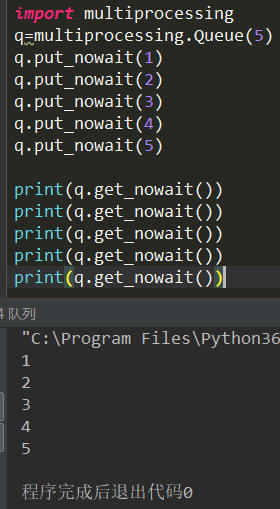
20、IPC机制:IPC机制就是进程之间的相互通信,分别有两种方式:一种是队列,另一种是管道
· 队列的原理是:先进先出,只能是一头传入数据,另一头读取数据。管道+锁就能实现队列(推荐使用:队列)
管道的原理是:链接进程与进程之间的桥梁
队列和管道实现了多个进程之间的共享空间
Queue:指定队列中存放的数据个数
put:写入数据
get:读取数据
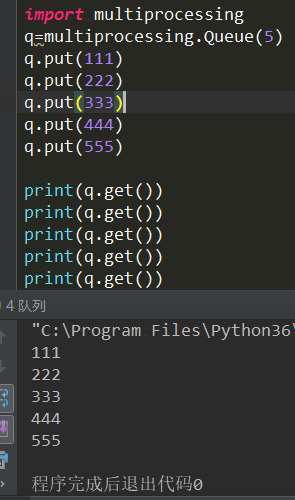
注意:如果put和get超出了定义存放的个数,就会阻塞
put_nowait:上传数据,如果超出了存放数据的个数就会抛出异常
get_nowait:读取数据,如果超出了存放数据的个数就会抛出异常
生产者和消费者
生产者:创建数据
消费者:读取(处理)数据
生产者和消费者都是由都列分离开的。
生产者创建数据,然后存放到队列里面,接着消费者在队列里面读取数据
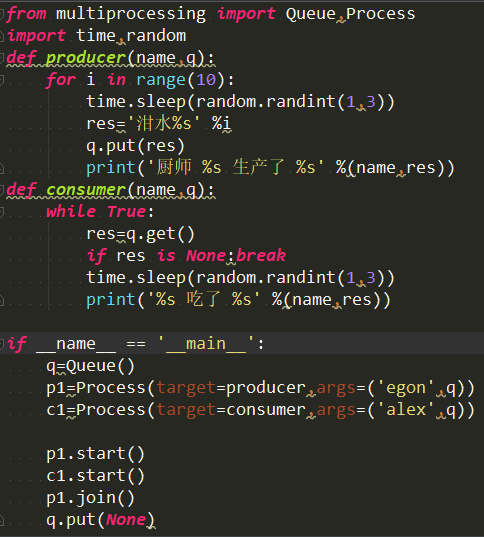
注意:在消费者执行完过后需要加上一个终止条件,不然代码就会一直在那里等待着。
处理生产者和消费者直接的数据平衡的速度差
如何平衡:生产者——>队列——>消费者 (生产者和消费者解藕)
21、什么叫做水平扩展:增加计算机的数量,并没有提高计算机的性能
什么叫开源:开放源代码
什么叫做虚拟化:同时跑多个系统。(
)
什么是分布式和集中式:集中式就是在一台机器上执行任务;分布式就是将任务分散到多台机器上。
22、JoinableQueue模块:比Queue多了两个函数,一个是task_done,另一个是join,都是专用于全球进行编程的,大多数用于生产者和消费者之间的。
task_done:是用在get后面的,告诉os已经处理完了内容。
join:是说Queue里面的生产数据全部处理完了。
使用方法如下:
# import multiprocessing
# import time
# import random
# def sheng(name,q,wuping):
# for i in range(5):
# time.sleep(random.random())
# ret='%s%s'%(wuping,i)
# q.put(ret)
# print('厨师%s创建了%s'%(name,ret))
# q.join()
# def xiao(name,q):
# while True:
# time.sleep(random.random())
# ret=q.get()
# print('%s吃了%s'%(name,ret))
# q.task_done()
# if __name__=='__main__':
# q=multiprocessing.JoinableQueue()
# s1=multiprocessing.Process(target=sheng,args=('egon1',q,'包子'))
# s2=multiprocessing.Process(target=sheng,args=('egon2',q,'rou'))
# s3=multiprocessing.Process(target=sheng,args=('egon3',q,'骨头'))
# x1=multiprocessing.Process(target=xiao,args=('alex1',q))
# x2=multiprocessing.Process(target=xiao,args=('alex2',q))
# x1.daemon=True
# x2.daemon=True
# s1.start()
# s2.start()
# s3.start()
# x1.start()
# x2.start()
# s1.join()
# s2.join()
# s3.join()
23、Manager:共享内存空间
dict:共享的以恶搞字典,能够被多个共享
如下1:
# import multiprocessing
# def walk(d):
# d['count']-=1
# if __name__=='__main__':
# m=multiprocessing.Manager()
# d=m.dict({'count':100})
# for i in range(100):
# w=multiprocessing.Process(target=walk,args=(d,))
# w.start()
# w.join()
# print(d)
如下2:
# import multiprocessing
# def walk(d,loak):
# with loak:
# d['count']-=1
# if __name__=='__main__':
# m=multiprocessing.Manager()
# d=m.dict({'count':100})
# lock=multiprocessing.Lock()
# li=[]
# for i in range(100):
# w=multiprocessing.Process(target=walk,args=(d,lock))
# li.append(w)
# w.start()
# for j in li:
# j.join()
# print(j)
# print(d)
24、进程池:创建一定数量的进程个数。
同步和异步:提交任务的两种方式。
pool:创建进程池和控制进程的数目,默认的个数是根据CPU的核数。
apply:传入两个参数,第一个是指任务。向进程池提交一个任务,实现了串行和同步调用。结束任务后,立马会拿到结果。
开启的进程数目有几个,就会有几个pid。
什么是同步调用:提交一个任务,等到任务结束后菜菜能执行下一个任务。
# import multiprocessing
# import time
# import random
# import os
# def walk(n):
# print('%s is walking'%os.getpid())
# time.sleep(random.random())
# return n
#
# if __name__=='__main__':
# p=multiprocessing.Pool(4)
# for i in range(10):
# q=p.apply(walk,args=(i,))
# print(q)
apply_async:向进程池提交任务,提交完任务后就不管了,只管提交任务,不能直接执行任务。实现了一个并发和异步调用
执行方法:先close:关闭任务,好让任务结束。
然后join:等待一个进程池不在提交任务,并且任务结束和计算任务个数。
最后get:获取返回值
什么是异步调用:提交完一个任务过后不会在原地等待,而是继续提交下一个任务。等待所有的任务结束后在用get获取任务
如下图:
# import multiprocessing
# import time
# import random
# import os
# def walk(n):
# print('%s is walking'%os.getpid())
# time.sleep(random.random())
# return n
#
# if __name__=='__main__':
# p=multiprocessing.Pool(4)
# li=[]
# for i in range(10):
# q=p.apply_async(walk,args=(i,))
# li.append(q)
# p.close()
# p.join()
# for i in li:
# print(i.get())
#
进程池没有任务了,进程就会被回收掉。
如下:
from multiprocessing import Pool
import os,time,random
def work(n):
print('%s is working' %os.getpid())
if __name__ == '__main__':
p=Pool(4)
for i in range(50):
# res=p.apply(work,args=(i,))
obj=p.apply_async(work,args=(i,))
p.close()
p.join()
如果在执行和提交任务的时间非常快,有时会提交任务后,第一个任务没有执行结束,就会开启一个新的进程执行这个任务;有时会在提交任务后,某进程刚好执行完毕,并且没有被回收掉,那么这次提交的任务就会被这个进程执行。
为什么要用进程池:为了实现并发,然后在并发的基础上对进程的数目进行一个限制。
25、回调函数:回调函数就是一个通过函数指针调用的函数。如果你把函数的指针(地址)作为参数传递给另一个函数,当这个指针被用来调用其所指向的函数时,我们就说这是回调函数。回调函数不是由该函数的实现方直接调用,而是在特定的事件或条件发生时由另外的一方调用的,用于对该事件或条件进行响应。
callback:后面加上的就是回调函数
回调函数的进程其实就是主进程。
回调函数实现一个网络爬虫:需要用到requests模块
get:获取网址
status_code:返回状态码
text:查看下载网址的内容
from multiprocessing import Pool,Process
import requests
import os
import time,random
def get(url):
print('%s GET %s' %(os.getpid(),url))
response=requests.get(url)
time.sleep(random.randint(1,3))
if response.status_code == 200:
print('%s DONE %s' % (os.getpid(), url))
return {'url':url,'text':response.text}
def parse(dic):
print('%s PARSE %s' %(os.getpid(),dic['url']))
time.sleep(1)
res='%s:%s
' %(dic['url'],len(dic['text']))
with open('db.txt','a') as f:
f.write(res)
if __name__ == '__main__':
urls=[
'https://www.baidu.com',
'https://www.python.org',
'https://www.openstack.org',
'https://help.github.com/',
'http://www.sina.com.cn/'
]
p=Pool(2)
start_time=time.time()
objs=[]
for url in urls:
obj=p.apply_async(get,args=(url,),callback=parse) #主进程负责干回调函数的活
objs.append(obj)
p.close()
p.join()
print('主',(time.time()-start_time))
线程:
1、什么是线程:线程就是开启一个进程,而执行进程里任务的就是线程。在一个进程里面可以创建多个线程,也叫做多线程。
每创建一个主进程,同时就会产生一个控制线程,来执行主进程里面的任务。而这个线程就叫做主线程。
在一个进程中创建的多个线程都可以共享这个进程里面的资源。
为什么线程开销小:创建线程是不会产生单独的内存空间的,而是在它的进程里面直接就会产生。
2、线程和进程的区别
区别1:在同一个进程下的多个线程是可以共享这个进程里面的资源的。
进程之间都会有独立的内存空间的,他们之间没有人任何关系的。
区别2:线程之间是可以直接访问他们共同进程下的数据并进行修改。
而进程之间的访问是需要依赖于ipc的。
区别3:线程的创建是不需要重新开启单独的内存空间的。
每一个进程的产生,就会产生一个内存空间的。
区别4:同一个进程下的多个线程之间是可以相互影响的
进程之间是没有任何影响的。
区别5:同一个进程下的多个线程修改数据,都会影响到其他线程的
进程之间,修改数据对其他的进程是没有任何影响的
3、为什么要多用线程
多个任务在一个进程里面完成,那就必须在这个进程里面开启多个线程。
(1) 多线程共享着一个进程的内存空间
(2) 线程比进程更轻量级,而线程比进程更加容易的创建和撤销。创建一个线程的速度会比创建一个进程的速度快上10到100倍之间。
(3) 如果多个线程都是CPU密集型时,并不能获得性能上的提升。拥有多线程允许任务之间互相重叠运行,从而加快程序的执行速度
(4) 为了利用多核,开启多个线程比开启多个进程的开销要小的多。在同一时候,一个CPU只能执行一个线程,所以CPU有几核,就能同时执行几个线程(而在cpython中,这个并不能实用,因为在cpython中,一个进程里面只能让一个线程运行。)
线程才是被CPU真正执行的,而在进程之间的线程是没有任何关系的。
4、threading模块:开启子线程的模块
Thread:开启子线程
target:后面加上一个函数名
args:传参数,以元组的格式传入
格式:线程=threading.Thread(target=函数名,args=(参数,))
start:向操作系统发送开启线程的信息(启动线程)
线程的创建方式:
方式一:
# import threading
# import os
# def work(n):
# print('%s is working %s'%(os.getpid(),n))
#
#
# if __name__=='__main__':
# for i in range(10):
# t=threading.Thread(target=work,args=(i,))
# t.start()
# print('主线程》》》',os.getpid())
方式二:
import threading
class Mythread(threading.Thread):
def __init__(self,n):
super().__init__()
self.n=n
def run(self):
print('%s is working' % self.n)
if __name__=='__main__':
for i in range(10):
t=Mythread(i)
t.start()
print('主线程》》》')
在同一个进程下,子线程和主线程使用的是统一的pid
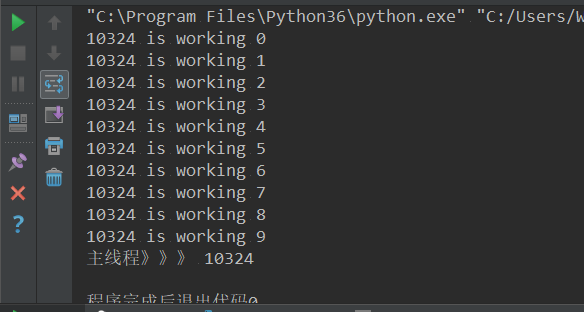
join:等待线程执行结束
import threading
import os
import time
import random
def work(n):
time.sleep(random.random())
print('%s is working %s'%(os.getpid(),n))
if __name__=='__main__':
for i in range(10):
t=threading.Thread(target=work,args=(i,))
t.start()
t.join()
print('主线程》》》',os.getpid())
threading的其他使用方法:
getName:获取线程名
setName:设置线程名
carrent_thread:获取当前的线程对象
enumerate:查看当前活跃的线程对象,以列表的格式返回
activeCount:查看当前活跃的线程数目
import threading
import os
import time
import random
def work(n):
time.sleep(random.random())
print('%s is working %s'%(os.getpid(),n))
print(threading.current_thread().getName()) #获取当前线程名
if __name__=='__main__':
for i in range(10):
t=threading.Thread(target=work,args=(i,))
t.start()
print(threading.enumerate()) #查看当前活跃的对象
print(threading.activeCount()) #查看活跃的数目
print('主线程》》》',os.getpid())
线程执行完毕,被回收的时间长短是不一样的。
5、守护线程:守护线程会在主线程执行结束后,自动的结束。
主线程从执行的意义上来讲就是一个主进程,主线程的结束会在除守护线程执行结束后就会结束
daemon=True:创建守护线程
import threading
import os
import time
import random
def work(n):
print('%s is working %s'%(os.getpid(),n))
time.sleep(random.random())
print('%s is ending %s'%(os.getpid(),n))
def foo(n):
print('%s is fooing %s'%(os.getpid(),n))
time.sleep(random.random())
print('%s is ending %s'%(os.getpid(),n))
if __name__=='__main__':
t1=threading.Thread(target=work,args=(100,))
t2=threading.Thread(target=foo,args=(200,))
t1.daemon=True
t1.start()
t2.start()
print('主线程》》》',os.getpid())
守护线程等待非守护线程的结束是为了关闭进程。
6、GIL(互斥锁)
(1) 全局解释互斥锁:保证了数据的安全性。而GIL是cpython解释器的一种特性。
(2) 互斥锁(mutex):限制了cpython中多个线程的执行数量。与cpython的内存管理有关。
(3) cpython中有一个回收机制,绑定的关系引用技术为0时,就会自动的回收调。
一把互斥锁只能保证一类数据的安全性。
import threading
import time
import random
n=20
def work():
global n
loak.acquire()
time.sleep(random.random())
n-=1
loak.release()
if __name__=='__main__':
li=[]
loak=threading.Lock()
for i in range(20):
t=threading.Thread(target=work)
li.append(t)
t.start()
for t in li:
t.join()
print(n)
假如不加上锁,结果会不一样,如下:
import threading
import time
import random
n=200
def work():
global n
time.sleep(random.random())
n-=1
if __name__=='__main__':
for i in range(200):
t=threading.Thread(target=work)
t.start()
t.join()
print(n)
GIL锁只能保证cpython解释器中的代码安全,不能保证自己的代码安全性,如果想要保证自己代码的安全性,就需要给自己的代码加上一把互斥锁
有了GIL锁,就能保证cpython中的进程中的多个线程一只能执行一个。
对于计算密集型来说,在多核CPU下开启多个进程的效率比较高
#使用线程进行计算密集型 # import threading # import time # def work(): # a=1 # for i in range(1000000): # a*=i # if __name__=='__main__': # li=[] # start = time.time() # for i in range(100): # t=threading.Thread(target=work) #13.447768926620483 # li.append(t) # t.start() # for t in li: # t.join() # print(time.time() - start) # 使用进程实现计算密集型 # import multiprocessing # import time # def work(): # a=1 # for i in range(1000000): # a*=i # if __name__=='__main__': # li=[] # start = time.time() # for i in range(100): # t=multiprocessing.Process(target=work) #8.421481609344482 # li.append(t) # t.start() # for t in li: # t.join() # print(time.time() - start)
对于IO密集型来说,多核CPU和单核CPU的效果是一样的,开启多线程的效率会比开启多进程的效率要高,并且还能保证数据的安全性。
#使用线程进行IO密集型 # import threading # import time # def work(): # time.sleep(2) # if __name__=='__main__': # li=[] # start = time.time() # for i in range(10): # t=threading.Thread(target=work) #2.0028274059295654 # li.append(t) # t.start() # for t in li: # t.join() # print(time.time() - start) # 使用进程实现IO密集型 # import multiprocessing # import time # def work(): # time.sleep(2) # if __name__=='__main__': # li=[] # start = time.time() # for i in range(10): # t=multiprocessing.Process(target=work) #2.953113079071045 # li.append(t) # t.start() # for t in li: # t.join() # print(time.time() - start)
ps:下面是连载的博客
进程、线程和协成的详解如下:
进程篇:http://www.cnblogs.com/Eva-J/articles/5110844.html
线程篇——基础篇:http://www.cnblogs.com/Eva-J/articles/5109737.html
线程篇——进阶篇:http://www.cnblogs.com/Eva-J/articles/5110160.html
线程篇——线程池:http://www.cnblogs.com/Eva-J/articles/5106564.html
进程篇——进程池:http://www.cnblogs.com/kaituorensheng/p/4465768.html
进程篇——回调函数:http://www.cnblogs.com/hainan-zhang/p/6222552.html
协程篇:http://www.cnblogs.com/Eva-J/articles/5110969.html
参考文献:
同步和异步相关:http://jingyan.baidu.com/article/295430f1cbfa8f0c7e0050ab.html
python的最难问题【译】多线程相关:http://www.oschina.net/translate/pythons-hardest-problem
浅谈对协程的理解:http://blog.csdn.net/qq910894904/article/details/41699541
python多线程学习小结:http://www.myexception.cn/perl-python/1688021.html
python线程指南:http://www.cnblogs.com/huxi/archive/2010/06/26/1765808.html
threading.RLock和threading.Lock:http://blog.sina.com.cn/s/blog_5dd2af0901012rad.html
python的进程、线程与协程:http://www.cnblogs.com/wupeiqi/articles/5040827.html