变量
一、定义方式
- 下划线(推荐使用) age_of_oldboy = 56
- 变量名只能是 字母、数字或下划线的任意组合
- 变量名的第一个字符不能是数字
- 关键字不能声明为变量名['and', 'as', 'assert', 'break', 'class', 'continue', 'def', 'del', 'elif', 'else', 'except', 'exec', 'finally', 'for', 'from', 'global', 'if', 'import', 'in', 'is', 'lambda', 'not', 'or', 'pass', 'print', 'raise', 'return', 'try', 'while', 'with', 'yield']
二、id、type、value、is、in、hash
- 身份:即内存地址,可以用id()来获取
- 类型:决定了该对象保存的类型,需要遵循什么规则,可用type()来获取该数据类型
- 值:对象的保存的的真实数据
- 等号比较的是value
- is比较的是id
- id相同,意味着type和value必定相同
- value相同type肯定相同,但id可能不同
- 可变:值变,id不变。可变==不可hash
- 不可变:值变,id就变。不可变==可hash
- is运算符用于比较两个对象的身份
- in主要用来判断某一元素是否在某种元素集合中
- 可hash的就是不可变数据类型,不可hash的就是可变数据类型
三、类型分类
- 可变类型:在id不变的情况下,value可以变,则称为可变类型,如列表,字典
- 不可变类型:value一旦改变,id也改变,则称为不可变类型(id变,意味着创建了新的内存空间)
四、变量的声明和引用
name='egon' #变量的声明 name #通过变量名,引用变量的值 print(name) #引用并且打印变量名name对应的值,即'egon'
name1='lhf' name2='egon'
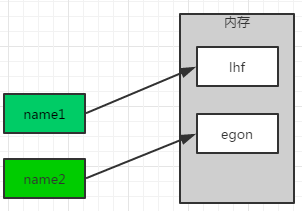
name1='lhf' name2=name1

注:变量名没有储藏值的作用,只起到绑定值的作用,改变一个变量的值,变量名重新指向一个值,原值物理地址不变。
常量
- 常量即指不变的量,如圆周率 3.1415926..., 在Python中没有一个专门的语法代表常量,程序员约定俗成用变量名全部大写代表常量AREAS = 56
解释器
1. 解释器:即时调试代码,代码无法永久保存
2. 文件:永久保存代码
在D:\python_test\目录下新建文件hello.py,编写代码如下
print('hello world')
执行hello.py,即python D:\python_test\hello.py
python内部执行过程如下:
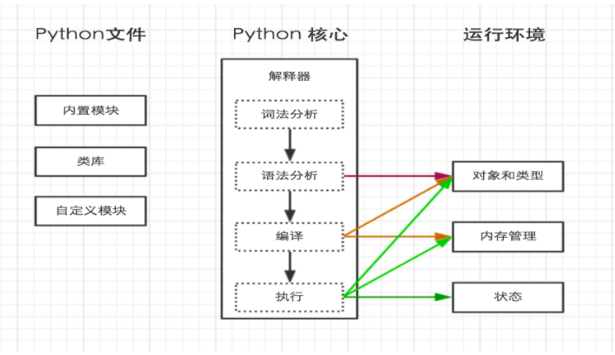
上一步中执行python D:\python_test\hello.py时,明确的指出 hello.py 脚本由 python 解释器来执行。
在linux平台中如果想要类似于执行shell脚本一样执行python脚本,例: ./hello.py ,那么就需要在 hello.py 文件的头部指定解释器,如下:
#!/usr/bin/env python #该行只对linux有效
print('hello world')
ps:执行前需给予 hello.py 执行权限,chmod 755 hello.py
程序交互
python3中统一都是input,python2中有raw_input等同于python3的input,另外python2中也有input
1.res=input("python3: ").strip()
2.res=raw_input("python2: ")
3.res=input("python2: ")
1,2无论接收何种输入,都被存为字符串赋值给res,
3的意思是,用户输入何种类型,就以何种类型赋值给res
- 在python3中 input:用户输入任何值,都存成字符串类型
1.1文件头
#!/usr/bin/env python #Linux系统下有效
# -*- coding: utf-8 -*-1.2注释
注释当前行:#
注释多行'''
被注释内容
'''
1.3执行脚本传入参数
Python有大量的模块,从而使得开发Python程序非常简洁。类库有包括三中:
- Python内部提供的模块
- 业内开源的模块
- 程序员自己开发的模块
Python内部提供一个 sys 的模块,其中的 sys.argv 用来捕获执行执行python脚本时传入的参数
1 #!/usr/bin/env python 2 # -*- coding: utf-8 -*- 3 4 import sys 5 6 print sys.argv
执行
C:\Users\Administrator>python D:\python_test\hello.py arg1 arg2 arg3 ['D:\\python_test\\hello.py', 'arg1', 'arg2', 'arg3']
1.4了解pyc文件
执行Python代码时,如果导入了其他的 .py 文件,那么,执行过程中会自动生成一个与其同名的 .pyc 文件,该文件就是Python解释器编译之后产生的字节码。
ps:代码经过编译可以产生字节码;字节码通过反编译也可以得到代码。
range
- range用来指定范围,生成指定的数字。
|
1
2
3
4
5
6
7
|
for item in range(5,10,2): print(item)"""579""" |
基本数据类型
- 数据即变量的值,变量的是用来反映/保持状态以及状态变化的,毫无疑问针对不同的状态就应该用不同类型的数据去标识
一、数字
定义:a=1
特性:
1.只能存放一个值
2.一经定义,不可更改
3.直接访问
分类:整型,长整型,布尔,浮点,复数
1.1整形
- 定义:age=10 #age=int(10)
- 用于标识:年龄,等级,身份证号,qq号,个数
Python的整型相当于C中的long型,Python中的整数可以用十进制,八进制,十六进制表示。
>>> 10 10 --------->默认十进制 >>> oct(10) '012' --------->八进制表示整数时,数值前面要加上一个前缀“0” >>> hex(10) '0xa' --------->十六进制表示整数时,数字前面要加上前缀0X或0x
python2.*与python3.*关于整型的区别
python2.*
在32位机器上,整数的位数为32位,取值范围为-2**31~2**31-1,即-2147483648~2147483647
在64位系统上,整数的位数为64位,取值范围为-2**63~2**63-1,即-9223372036854775808~9223372036854775807
python3.*整形长度无限制
1.2长整形long
python2.*:
跟C语言不同,Python的长整型没有指定位宽,也就是说Python没有限制长整型数值的大小,但是实际上由于机器内存有限,所以我们使用的长整型数值不可能无限大。
在使用过程中,我们如何区分长整型和整型数值呢?
通常的做法是在数字尾部加上一个大写字母L或小写字母l以表示该整数是长整型的,例如:
a = 9223372036854775808L
注意,自从Python2起,如果发生溢出,Python会自动将整型数据转换为长整型,
所以如今在长整型数据后面不加字母L也不会导致严重后果了。
python3.*
长整型,整型统一归为整型
1.3布尔bool
True 和 False
1 和 0
1.4浮点数float
- 定义:salary=3.1 #salary=float(3.1)
- 用于标识:工资,身高,体重
Python的浮点数就是数学中的小数,类似C语言中的double。
在运算中,整数与浮点数运算的结果是浮点数
浮点数也就是小数,之所以称为浮点数,是因为按照科学记数法表示时,
一个浮点数的小数点位置是可变的,比如,1.23*109和12.3*108是相等的。
浮点数可以用数学写法,如1.23,3.14,-9.01,等等。但是对于很大或很小的浮点数,
就必须用科学计数法表示,把10用e替代,1.23*109就是1.23e9,或者12.3e8,0.000012可以写成1.2e-5,等等。
整数和浮点数在计算机内部存储的方式是不同的,整数运算永远是精确的而浮点数运算则可能会有四舍五入的误差。
1.5复数complex
复数由实数部分和虚数部分组成,一般形式为x+yj,其中的x是复数的实数部分,y是复数的虚数部分,这里的x和y都是实数。
注意,虚数部分的字母j大小写都可以。
>>> 1.3 + 2.5j == 1.3 + 2.5J
True
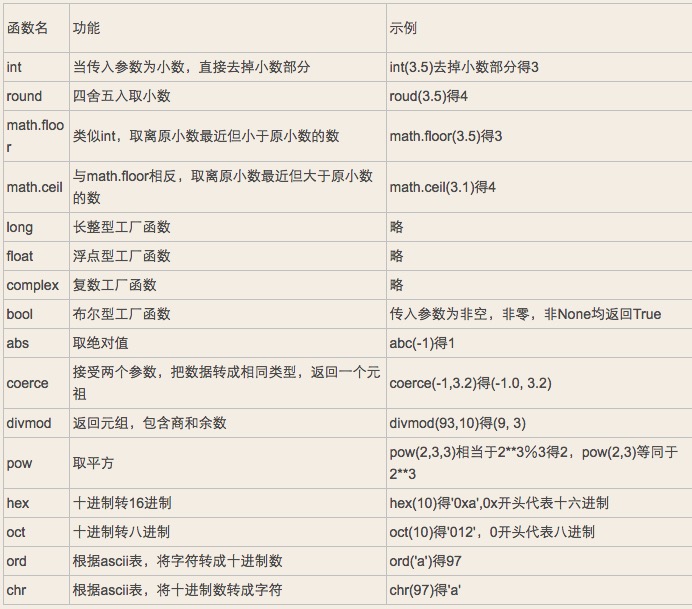
1.6数字相关内建函数
二、布尔
- 判断一个条件成立时,用True标识,不成立则用False标识
- *****None,0,空(空字符串,空列表,空字典等)三种情况下布尔值为False*****
三、字符串
- 定义:name='tom' #name=str('tom')
- 用于标识:描述性的内容,如姓名,性别,国籍,种族
- 加了引号的字符就是字符串类型,单引号、双引号、多引号都一样,注意单双引号的嵌套
定义:它是一个有序的字符的集合,用于存储和表示基本的文本信息,‘’或“”或‘’‘ ’‘’中间包含的内容称之为字符串
特性:
1.只能存放一个值
2.不可变
3.按照从左到右的顺序定义字符集合,下标从0开始顺序访问,有序
补充:
1.字符串的单引号和双引号都无法取消特殊字符的含义,如果想让引号内所有字符均取消特殊意义,在引号前面加r,如name=r'l\thf'
2.unicode字符串与r连用必需在r前面,如name=ur'l\thf'
|
1
2
3
4
5
6
7
8
|
s = "watch ,'套路'"#多行字符串必须用多引号msg = '''种一棵树最好的时间是十年前,其次是现在。所有的成功都是你行动以后对你行动的奖励。'''print(s) #watch ,'套路'print(msg) |
1、字符串常用操作
res='hello world '
移除空白
res='hello world ' print(res.strip()) hello world #移除字符串后面的空白
分割
print(res.split()) ['hello', 'world']
长度
res='hello world ' print(len(res)) 17
索引
res='hello world ' print(res[4]) o
切片
res='hello world ' print(res[1:4]) ell
字符串中的搜索和替换:
S.find(substr, [start, [end]]) #返回S中出现substr的第一个字母的标号,如果S中没有substr则返回-1。start和end作用就相当于在S[start:end]中搜索
S.index(substr, [start, [end]]) #与find()相同,只是在S中没有substr时,会返回一个运行时错误
S.rfind(substr, [start, [end]]) #返回S中最后出现的substr的第一个字母的标号,如果S中没有substr则返回-1,也就是说从右边算起的第一次出现的substr的首字母标号
S.rindex(substr, [start, [end]])
S.count(substr, [start, [end]]) #计算substr在S中出现的次数
S.replace(oldstr, newstr, [count]) #把S中的oldstr替换为newstr,count为替换次数。这是替换的通用形式,还有一些函数进行特殊字符的替换
S.strip([chars]) #把S中前后chars中有的字符全部去掉,可以理解为把S前后chars替换为None
注:可用于判断字符串是否为空,字符串为空返回False,不为空时返回Ture。
S.lstrip([chars]) #把S中前chars中有的字符去掉
S.rstrip([chars]) #把S中后chars中有的字符全部去掉
S.expandtabs([tabsize]) #把S中的tab字符替换没空格,每个tab替换为tabsize个空格,默认是8个
字符串的分割和组合:
S.split([sep, [maxsplit]]) #以sep为分隔符,把S分成一个list。maxsplit表示分割的次数。默认的分割符为空白字符
S.rsplit([sep, [maxsplit]])
S.splitlines([keepends]) #把S按照行分割符分为一个list,keepends是一个bool值,如果为真每行后而会保留行分割符。
S.join(seq) #把seq代表的序列──字符串序列,用S连接起来
字符串的mapping,这一功能包含两个函数:
String.maketrans(from, to) #返回一个256个字符组成的翻译表,其中from中的字符被一一对应地转换成to,所以from和to必须是等长的。
S.translate(table[,deletechars]) # 使用上面的函数产后的翻译表,把S进行翻译,并把deletechars中有的字符删掉。需要注意的是,如果S为unicode字符串,那么就不支持 deletechars参数,可以使用把某个字符翻译为None的方式实现相同的功能。此外还可以使用codecs模块的功能来创建更加功能强大的翻译 表。
字符串中字符大小写的变换:
S.lower() #小写
S.upper() #大写
S.swapcase() #大小写互换
S.capitalize() #首字母大写
String.capwords(S) #这是模块中的方法。它把S用split()函数分开,然后用capitalize()把首字母变成大写,最后用join()合并到一起
S.title() #只有首字母大写,其余为小写,模块中没有这个方法
字符串的测试函数
这些函数返回的都是bool值
S.starstwith(prefix[,start[,end]]) #是否以prefix开头
S.endswith(suffix[,start[,end]]) #以suffix结尾
S.isalnum() #是否全是字母和数字,并至少有一个字符
S.isalpha() #是否全是字母,并至少有一个字符
S.isdigit() #是否全是数字,并至少有一个字符
S.isspace() #是否全是空白字符,并至少有一个字符
S.islower() #S中的字母是否全是小写
S.isupper() #S中的字母是否便是大写
S.istitle() #S是否是首字母大写的
字符串在输出时的对齐:
S.ljust(width,[fillchar]) #输出width个字符,S左对齐,不足部分用fillchar填充,默认的为空格。
S.rjust(width,[fillchar]) #右对齐
S.center(width, [fillchar]) #中间对齐
S.zfill(width) #把S变成width长,并在右对齐,不足部分用0补足
格式化字符串:
s='name:{},age:{},sex:{}'
print(s.format('ogen',18,'male','asdasda'))#多余的参数不会影响结果,少参数会报错。
四、列表
定义:[]内以逗号分隔,按照索引,存放各种数据类型,每个位置代表一个元素。
特性:
1.可存放多个值。
2.可修改指定索引位置对应的值,可变。
3.按照从左到右的顺序定义列表元素,下标从0开始顺序访问,有序。
1、列表创建
list_test=['lhf',12,'ok']
或
list_test=list('abc')
或
list_test=list(['lhf',12,'ok'])
2、列表常用操作
>>> classmates = ['Michael', 'Bob', 'Tracy']
>>> classmates
['Michael', 'Bob', 'Tracy']
索引
>>> classmates[0]
'Michael'
>>> classmates[1]
'Bob'
>>> classmates[2]
'Tracy'
>>> classmates[3]
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
IndexError: list index out of range
>>> classmates[-1]
'Tracy'
切片
>>> classmates[0:]
['Michael', 'Bob', 'Tracy']
>>> classmates[0::2]
['Michael', 'Tracy']
>>> classmates[:2]
['Michael', 'Bob']
>>> classmates[-2:-1]
['Bob']
>>> classmates[-2:0]
[]
>>> classmates[-3:-1]
['Michael', 'Bob']
追加
>>> classmates.append('Adam')
>>> classmates
['Michael', 'Bob', 'Tracy', 'Adam']
>>> classmates.insert(1, 'Jack')
>>> classmates
['Michael', 'Jack', 'Bob', 'Tracy', 'Adam']
删除
>>> classmates.pop()
'Adam'
>>> classmates
['Michael', 'Jack', 'Bob', 'Tracy']
>>> classmates.pop(1)
'Jack'
>>> classmates
['Michael', 'Bob', 'Tracy']
长度
>>> len(classmates)
3
循环
>>> for i in classmates:
... print(i)
...
Michael
Bob
Tracy
包含
>>> 'Bob' in classmates
True
>>> 'ogen' in classmates
False
|
1
2
|
students_info=[['tom',18,['sing',]],['rose',18,['play','sleep']]]print(students_info[0][2][0]) #取出第一个学生的第一个爱好 #sing |
五、元组
定义:与列表类似,只不过[]改成()
特性:
1.可存放多个值。
2.不可变。
3.按照从左到右的顺序定义元组元素,下标从0开始顺序访问,有序。
1、元组创建
ages = (11, 22, 33, 44, 55)
或
ages = tuple((11, 22, 33, 44, 55))
定义一个空的元组 t=()
定义只有1个元素的元组
t=(1) 这样t的类型就是整形
t=(1,) 这样t的类型就是元组
一个“可变的”tuple:
>>> t = ('a', 'b', ['A', 'B'])
>>> t[2][0] = 'X'
>>> t[2][1] = 'Y'
>>> t
('a', 'b', ['X', 'Y'])
定义的时候tuple包含的3个元素:
当我们把list的元素'A'和'B'修改为'X'和'Y'后,tuple变为:
表面上看,tuple的元素确实变了,但其实变的不是tuple的元素,而是list的元素。tuple一开始指向的list并没有改成别的list,所以,tuple所谓的“不变”是说,tuple的每个元素,指向永远不变。即指向'a',就不能改成指向'b',指向一个list,就不能改成指向其他对象,但指向的这个list本身是可变的!
2、元组的操作
索引
>>> ages = (11, 22, 33, 44, 55)
>>> ages[0]
11
切片
>>> ages[0:]
(11, 22, 33, 44, 55)
>>> ages[0:3]
(11, 22, 33)
>>> ages[:3]
(11, 22, 33)
>>> ages[:3:2]
(11, 33)
>>> ages[-3:-1]
(33, 44)
循环
>>> for i in ages:
... print(i)
...
11
22
33
44
55
包含
>>> 11 in ages
True
>>> 12 in ages
False
六、字典
定义:{key1:value1,key2:value2},key-value结构,key必须可hash
特性:
1.可存放多个值。
2.可修改指定key对应的值,可变。
3.无序。
1、字典的创建
person = {"name": "sb", 'age': 18}
或
person = dict(name='sb', age=18)
person = dict({"name": "sb", 'age': 18})
person = dict((['name','sb'],['age',18]))
{}.fromkeys(seq,100) #不指定100默认为None
注意:
>>> dic={}.fromkeys(['k1','k2'],[])
>>> dic
{'k1': [], 'k2': []}
>>> dic['k1'].append(1)
>>> dic
{'k1': [1], 'k2': [1]}
2、字典的操作
索引
>>> d = {'Michael': 95, 'Bob': 75, 'Tracy': 85}
>>> d['Michael']
95
新增
>>> d['alex']=100
>>> d
{'Michael': 95, 'Bob': 75, 'Tracy': 85, 'alex': 100}
如果key不存在,就会报错。
避免key不存在的错误,有两种判断key是否存在的方式
1.通过in判断:
>>> 'Thomas' in d
False
2.通过get()判断,如果key不存在,可以返回None,或者自己指定的value:
>>> d.get('Thomas')
>>> d.get('Thomas', -1)
-1
删除
>>> d.pop('Bob')
75
>>> d
{'Michael': 95, 'Tracy': 85}
循环
>>> for i in d:
... print(i,d[i])
...
Michael 95
Bob 75
Tracy 85
alex 100
长度
>>> len(d)
4
请务必注意,dict内部存放的顺序和key放入的顺序是没有关系的。
和list比较,dict有以下几个特点:
- 查找和插入的速度极快,不会随着key的增加而变慢;
- 需要占用大量的内存,内存浪费多。
而list相反:
- 查找和插入的时间随着元素的增加而增加;
- 占用空间小,浪费内存很少。
所以,dict是用空间来换取时间的一种方法。
dict可以用在需要高速查找的很多地方,在Python代码中几乎无处不在,正确使用dict非常重要,需要牢记的第一条就是dict的key必须是不可变对象。
这是因为dict根据key来计算value的存储位置,如果每次计算相同的key得出的结果不同,那dict内部就完全混乱了。这个通过key计算位置的算法称为哈希算法(Hash)。
要保证hash的正确性,作为key的对象就不能变。在Python中,字符串、整数等都是不可变的,因此,可以放心地作为key。而list是可变的,就不能作为key:
3、字典的常用函数
.pop(key,'str') 删除key对应的键值对,返回value。key不存在返回str。
.popitem() 随机删除键值对
.keys() 返回字典的所有key到dict_keys中。可以使用list(d.keys())
.values() 返回字典的valu到dict_values中,可以使用list(d.keys())
.items() 返回键值对。
.get(key,'str') 返回key对应的值value,key不存在返回自定义的str。
.clear() 清空字典
.copy() 复制字典
{}.fromkeys([],None) 初始化字典
.update(dict) 将新字典ditct更新到原字典中,键存在覆盖值,键不存在创建键值对
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
info={ 'name':'tom', 'hobbies':['sing','sleep'], 'company':{ 'name':'google', 'type':'it', 'fund':8000000000, }}print(info['company']['fund']) #取公司现金储备 #8000000000students=[ {'name':'tom','age':18,'hobbies':['sing','play']}, {'name':'rose','age':88,'hobbies':['read','sleep']}, {'name':'jack','age':99,'hobbies':['swim','watchTV','talk']},]print(students[2]['hobbies'][1]) #取第3个学生的第2个爱好watchTV |
流程控制之if...else
|
1
2
3
4
5
6
7
8
9
10
11
12
|
"""rose --> 超级管理员tom --> 普通管理员其他 --> 普通用户"""name = input('请输入用户名字:').strip()if name == 'rose': print('超级管理员')elif name == 'tom': print('普通管理员')else: print('普通用户') |
流程控制之while循环
一、条件循环
|
1
2
3
4
5
|
count=0while count <= 10: if count%2 == 0: print('loop',count) count+=1 |
二、死循环
|
1
2
|
while True: print('hello world') |
三、循环嵌套与tag
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
name='tom'password='123'tag=Truewhile tag: inp_name=input('用户名: ').strip() inp_pwd=input('密码: ').strip() if inp_name == name and inp_pwd == password: while tag: cmd=input('>>: ') if not cmd:continue if cmd == 'q': tag=False continue print('run <%s>' %cmd) else: print('用户名或密码错误') |
四、break与continue
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
#break用于退出本层循环while True: print ('go...') break print('stop')#只打印go... 就退出了,下面的 print('stop')根本不执行#continue用于退出本次循环,继续下一次循环while True: print ('go...') continue print('stop')#打印go... 就退出本次循环,本次循环下面的 print('stop')根本来不及执行,就继续下一次循环,所有一直打印 go... 也就是死循环了 |
五、while+else和for+else
- 其它语言else 一般只与if 搭配不同
- 在Python 中还有个while ...else 语句和for ...else 语句
- while 后面的else 作用是指当while 循环正常执行完,中间没有被break 中止的话,就会执行else后面的语句
- for 后面的else 作用是指当for 循环正常执行完,中间没有被break 中止的话,就会执行else后面的语句
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
|
count = 0while count <= 5 : count += 1 print("Loop",count)else: print("循环正常执行完啦")print("-----out of while loop ------")"""Loop 1Loop 2Loop 3Loop 4Loop 5Loop 6循环正常执行完啦-----out of while loop ------"""#如果执行过程中被break,就不会执行else的语句count = 0while count <= 5 : count += 1 if count == 3:break print("Loop",count)else: print("循环正常执行完啦")print("-----out of while loop ------")"""Loop 1Loop 2-----out of while loop ------""" |
流程控制之for循环
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
|
for i in range(1,10): for j in range(1,i+1): print('%s*%s=%s' %(i,j,i*j),end=' ') print()"""1*1=1 2*1=2 2*2=4 3*1=3 3*2=6 3*3=9 4*1=4 4*2=8 4*3=12 4*4=16 5*1=5 5*2=10 5*3=15 5*4=20 5*5=25 6*1=6 6*2=12 6*3=18 6*4=24 6*5=30 6*6=36 7*1=7 7*2=14 7*3=21 7*4=28 7*5=35 7*6=42 7*7=49 8*1=8 8*2=16 8*3=24 8*4=32 8*5=40 8*6=48 8*7=56 8*8=64 9*1=9 9*2=18 9*3=27 9*4=36 9*5=45 9*6=54 9*7=63 9*8=72 9*9=81 """max_level=6for cur_level in range(1,max_level+1): for i in range(max_level-cur_level): print(' ',end='') #在一行中连续打印多个空格 for j in range(2*cur_level-1): print('*',end='') #在一行中连续打印多个空格 print()""" * *** ***** ******* ********************""" |
规范代码
断点调试
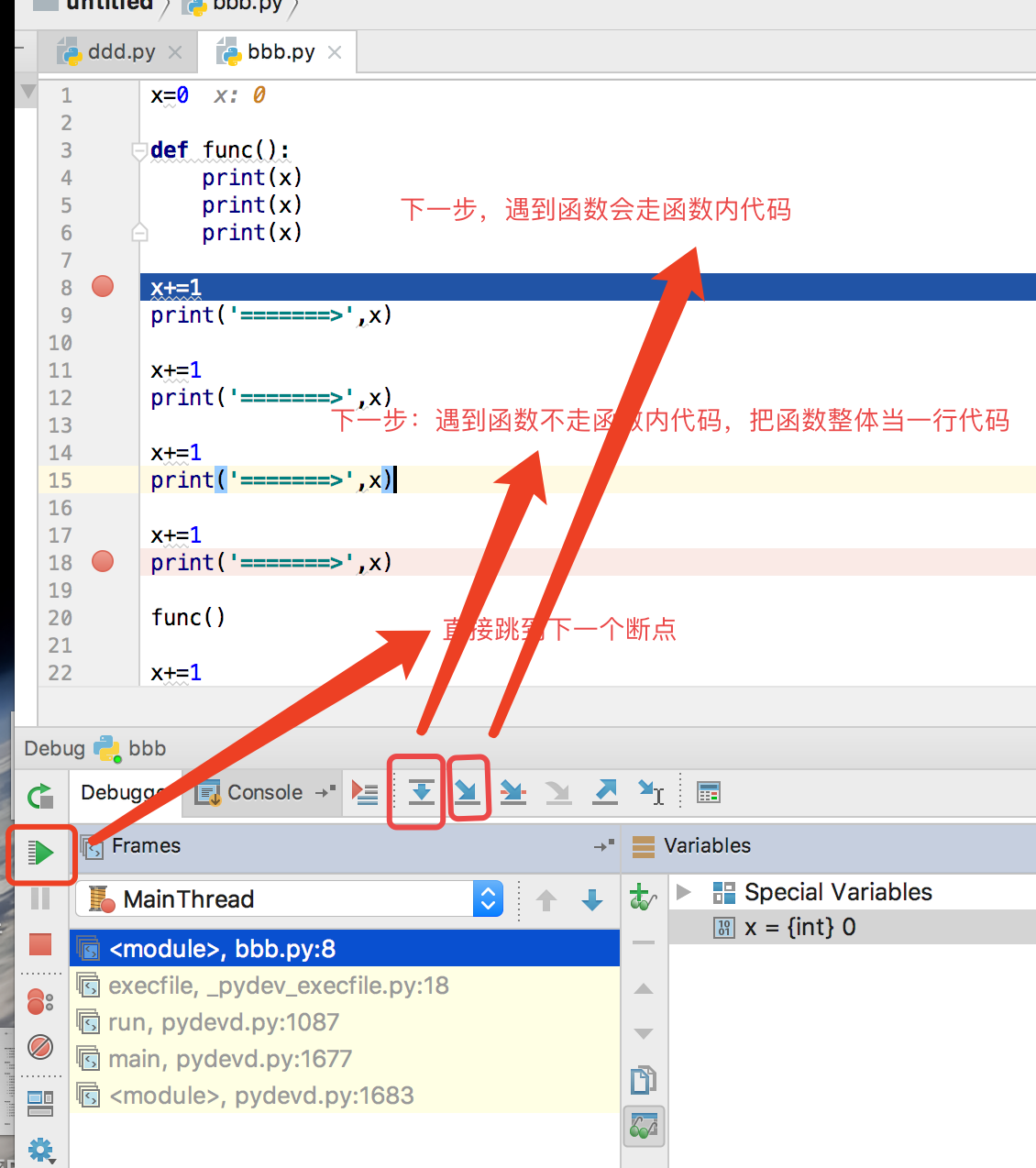
无需为程序所有代码加断点,只需要在关键代码加上断点,以debug模式调试时,程序会停在断点处。
基本运算符
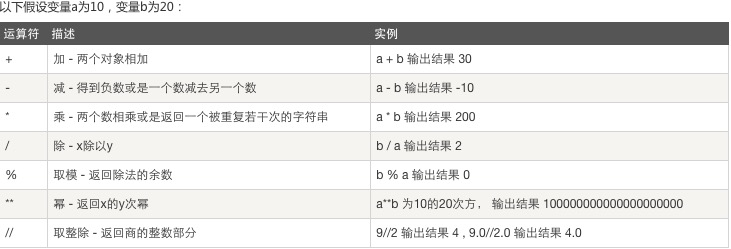
一、算数运算:
二、比较运算

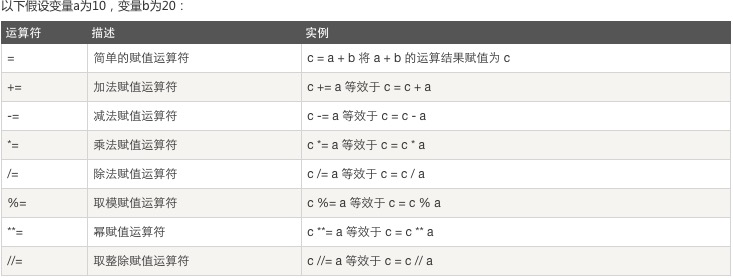
三、赋值运算符
四、逻辑运算

and注解:
- 在Python 中,and 和 or 执行布尔逻辑演算,如你所期待的一样,但是它们并不返回布尔值;而是,返回它们实际进行比较的值之一。
- 在布尔上下文中从左到右演算表达式的值,如果布尔上下文中的所有值都为真,那么 and 返回最后一个值。
- 如果布尔上下文中的某个值为假,则 and 返回第一个假值
or注解:
- 使用 or 时,在布尔上下文中从左到右演算值,就像 and 一样。如果有一个值为真,or 立刻返回该值
- 如果所有的值都为假,or 返回最后一个假值
- 注意 or 在布尔上下文中会一直进行表达式演算直到找到第一个真值,然后就会忽略剩余的比较值
and-or结合使用:
- 结合了前面的两种语法,推理即可。
- 为加强程序可读性,最好与括号连用,例如:
(1 and 'x') or 'y'
五、成员运算

|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
|
#字符串st = "abcdefg"s = "d"if s in st: print("in st")else: print("not in st")#列表lis = [1, 2, 3, 4]li = 5if li in lis: print("in lis")else: print("not in lis")#元组tup = (1, 2, 3, 4)t = 2if t in tup: print("in tup")else: print("not in tup")#字典 判断的是keydic = {'name':'tom','age':18}d = 'name'if d in dic: print("in dic")else: print("not in dic")#集合sett = {18,'age','name',20}se = 'name'if se in sett: print("in sett")else: print("not in sett") |
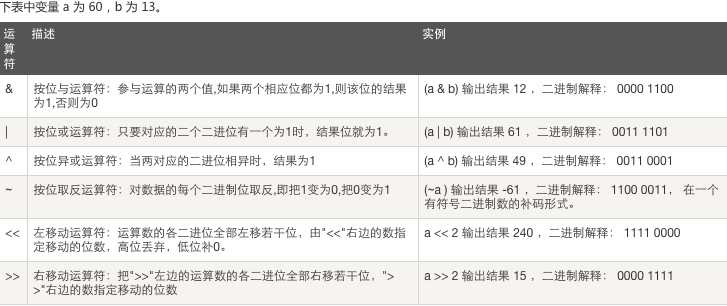
六、位运算
七、身份运算

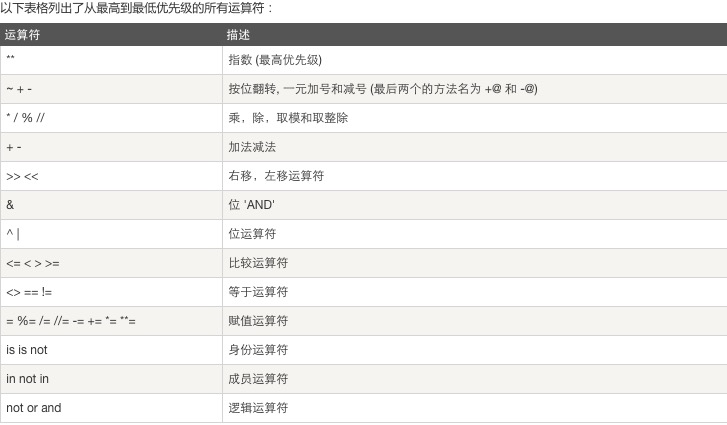
八、运算符优先级:自上而下,优先级从高到低
颜色设置


#格式: 设置颜色开始 :\033[显示方式;前景色;背景色m #说明: 前景色 背景色 颜色 --------------------------------------- 30 40 黑色 31 41 红色 32 42 绿色 33 43 黃色 34 44 蓝色 35 45 紫红色 36 46 青蓝色 37 47 白色 显示方式 意义 ------------------------- 0 终端默认设置 1 高亮显示 4 使用下划线 5 闪烁 7 反白显示 8 不可见 #例子: \033[1;31;40m <!--1-高亮显示 31-前景色红色 40-背景色黑色--> \033[0m <!--采用终端默认设置,即取消颜色设置--> print('\033[0;32;40m欢迎使用学生选课系统\033[0m') try: num = int(input('请输入数字选择功能 :')) except Exception as e: print('\033[31m对不起!您输入的内容有误~\033[0m')
