闭包函数
闭包函数:函数内部定义函数,成为内部函数。该内部函数包含对外部作用域,而不是对全局作用域名字的引用,那么该内部函数成为闭包函数。
name='alex' #定义全局变量name='alex' def func(): name='egon' #定义局部变量name='egon' def bar(): print(name) return bar #返回bar函数名 b=func() #执行func()结果为bar的函数名 相当于b=bar name='haha' #重新定义全局变量name='haha' print(b) #打印bar b() #执行bar(),name='egon'
执行结果: <function func.<locals>.bar at 0x000000000222BAE8> egon
def func(): name='egon' x=1000000000000000000000 def bar(): print(name) print(x) return bar f=func() print(f.__closure__) #打印出闭包函数外层作用域的变量 print(f.__closure__[0].cell_contents) #打印出闭包函数外层作用域的第一个变量的值 print(f.__closure__[1].cell_contents) #打印出闭包函数外层作用域的第一个变量的值 运行结果: (<cell at 0x0000000001E16528: str object at 0x0000000001E993B0>, <cell at 0x0000000001E16558: int object at 0x0000000001EA3C10>) egon 1000000000000000000000
闭包函数:1 内部函数 2 包含对外部作用域而非全局作用域的引用
闭包函数的特点:
自带作用域
延迟计算
以上两个实例都是包一层,闭包函数可以包多层:
#包两层的闭包函数 def func(): name='egon' #第2层作用域的变量 def wrapper(): money=1000 #第1层作用域的变量 def tell_info(): print('my namn is %s' % name) #使用第2层作用域的变量 print('egon have money %s' %(money)) #使用第1层作用域的变量 print(tell_info.__closure__) #打印闭包函数的变量 return tell_info return wrapper w=func() tell_info=w() print(tell_info.__closure__[0].cell_contents) #闭包函数变量位置在定义时就定下来了,不因为使用的顺序变化 print(tell_info.__closure__[1].cell_contents) 运行结果: (<cell at 0x0000000001E16558: int object at 0x000000000048AED0>, <cell at 0x0000000001E16528: str object at 0x0000000001E993B0>) 1000 egon
定义闭包函数的基本形式:
def 外部函数名(): 内部函数需要的变量 def 内部函数(): 引用外部变量 return 内部函数 def deco(): x=1 def wrapper(): print(x) return wrapper wrapper=deco() print(wrapper)
#包两层 def deco1(): y=2 def deco(): x=1 def wrapper(): print(x) print(y) return wrapper return deco deco=deco1() wrapper=deco() wrapper()
装饰器
- 不修改被装饰对象的源代码
- 不修改被装饰对象的调用方式
- 被装饰函数的正上方,单独一行
一、无参装饰器
1、开放封闭原则,对扩展是开放的,对修改是封闭的
2、装饰器,装饰器本质可以任意可调用对象,被装饰的对象也可以是任意
可调用对象,
装饰器的功能是:
在不修改被装饰对象源代码以及调用方式的前提下为期添加新功能
原则:
1.不修改源代码
2.不修改调用方法
目标:添加新功能
无参装饰器=高级函数+函数嵌套
基本框架
#这就是一个实现一个装饰器最基本的架子 def timer(func): def wrapper(): func() return wrapper
加上参数
def timer(func): def wrapper(*args,**kwargs): func(*args,**kwargs) return wrapper
加上功能
import time def timer(func): def wrapper(*args,**kwargs): start_time=time.time() func(*args,**kwargs) stop_time=time.time() print('函数[%s],运行时间是[%s]' %(func.__name__,stop_time-start_time)) return wrapper
加上返回值
import time def timer(func): def wrapper(*args,**kwargs): start_time=time.time() res=func(*args,**kwargs) stop_time=time.time() print('函数[%s],运行时间是[%s]' %(func.__name__,stop_time-start_time)) return res return wrapper
使用装饰器的方法一:
import time def timer(func): def wrapper(*args,**kwargs): start_time=time.time() res=func(*args,**kwargs) stop_time=time.time() print('函数[%s],运行时间是[%s]' %(func.__name__,stop_time-start_time)) return res return wrapper def cal(array): res=0 for i in array: res+=i return res cal=timer(cal) cal(range(100000)) 运行结果: 函数[cal],运行时间是[0.0070002079010009766]
使用@装饰器名称的方法:
import time def timer(func): def wrapper(*args,**kwargs): start_time=time.time() res=func(*args,**kwargs) stop_time=time.time() print('函数[%s],运行时间是[%s]' %(func.__name__,stop_time-start_time)) return res return wrapper @timer def cal(array): res=0 for i in array: res+=i return res cal(range(100000)) 函数[cal],运行时间是[0.007000446319580078]


import time def timer(func): def wrapper(*args,**kwargs): start_time=time.time() res=func(*args,**kwargs) stop_time=time.time() print('run time is %s' %(stop_time-start_time)) return res return wrapper @timer #把@timer放到foo()函数的定义处,相当于执行了foo=timer(foo) def foo(): time.sleep(3) print('from foo') foo() """执行结果 from foo run time is 3.000171661376953 """
import time from functools import wraps#### def timer(func): @wraps(func) #### def wrapper(*args,**kwargs): start_time=time.time() res=func(*args,**kwargs) stop_time=time.time() print('run time is %s' %(stop_time-start_time)) return res return wrapper @timer #把@timer放到foo()函数的定义处,相当于执行了foo=timer(foo) def foo(): time.sleep(1) print('from foo') foo() """执行结果 from foo run time is 1.000171661376953 """
def timer(name): def wrapper(func): print(name) return func return wrapper @timer('tom') def foo(a,b): return a*b print(foo(2,3))
import time def timmer(func): """timmer doc""" def inner(*args, **kwargs): """inner doc""" start = time.time() res = func(*args, **kwargs) end = time.time() print("函数运行时间为 %s" % (end - start)) return res return inner @timmer def func_test(): """func_test doc""" time.sleep(2) return print(func_test.__name__) # inner print(func_test.__doc__) # inner doc import time from functools import wraps def timmer(func): """timmer doc""" @wraps(func) #不改变使用装饰器原有函数的结构(如__name__, __doc__) def inner(*args, **kwargs): """inner doc""" start = time.time() res = func(*args, **kwargs) end = time.time() print("函数运行时间为 %s" % (end - start)) return res return inner @timmer def func_test(): """func_test doc""" time.sleep(2) return print(func_test.__name__) # func_test print(func_test.__doc__) # func_test doc
二、有参装饰器
有参装饰器也就是在无参装饰器外面再包一层函数,带上参数。
def timer2(ms = 'file'): def timer(func): def wrapper(*args, **kwargs): if ms == 'file': name = 'file_name' res = func(*args, **kwargs) print('%s login successful'%name) return res elif ms == 'mysql': name = 'mysql_name' res = func(*args, **kwargs) print('%s login successful'%name) return res else: name = 'other_name' res = func(*args, **kwargs) print('%s login successful'%name) return res return wrapper return timer @timer2(ms = 'file') #timer2(ms = 'file')返回timer函数引用 就和无参的一样了 def foo(name): print('from foo %s'%name) foo('rose') """ from foo rose file_name login successful """
三、多装饰器
- 加载顺序(outter函数的调用顺序):自下而上
- 执行顺序(wrapper函数的执行顺序):自上而下
# 叠加多个装饰器 # 1. 加载顺序(outter函数的调用顺序):自下而上 # 2. 执行顺序(wrapper函数的执行顺序):自上而下 def outter1(func1): # func1=wrapper2的内存地址 print('加载了outter1') def wrapper1(*args, **kwargs): print('执行了wrapper1') res1 = func1(*args, **kwargs) return res1 return wrapper1 def outter2(func2): # func2=wrapper3的内存地址 print('加载了outter2') def wrapper2(*args, **kwargs): print('执行了wrapper2') res2 = func2(*args, **kwargs) return res2 return wrapper2 def outter3(func3): # func3=最原始的那个index的内存地址 print('加载了outter3') def wrapper3(*args, **kwargs): print('执行了wrapper3') res3 = func3(*args, **kwargs) return res3 return wrapper3 # 被装饰函数的正上方,单独一行 @outter1 # outter1(wrapper2的内存地址)======>index=wrapper1的内存地址 @outter2 # outter2(wrapper3的内存地址)======>wrapper2的内存地址 @outter3 # outter3(最原始的那个index的内存地址)===>wrapper3的内存地址 def index(): # index=outter1(outter2(outter3(index))) print('from index') print('==========================') index() """ 加载了outter3 加载了outter2 加载了outter1 ========================== 执行了wrapper1 执行了wrapper2 执行了wrapper3 from index """
迭代器
一、为何要有迭代器?
对于序列类型:字符串、列表、元组,我们可以使用索引的方式迭代取出其包含的元素。但对于字典、集合、文件等类型是没有索引的,若还想取出其内部包含的元素,则必须找出一种不依赖于索引的迭代方式,这就是迭代器,迭代器有节省内存的好处。
二、什么是可迭代对象iterable?
可迭代对象指的是内置有__iter__方法的对象,即obj.__iter__,如下
- 'hello'.__iter__
- (1,2,3).__iter__
- [1,2,3].__iter__
- {'a':1}.__iter__
- {'a','b'}.__iter__
- open('a.txt').__iter__
三、什么是迭代器对象iterator?
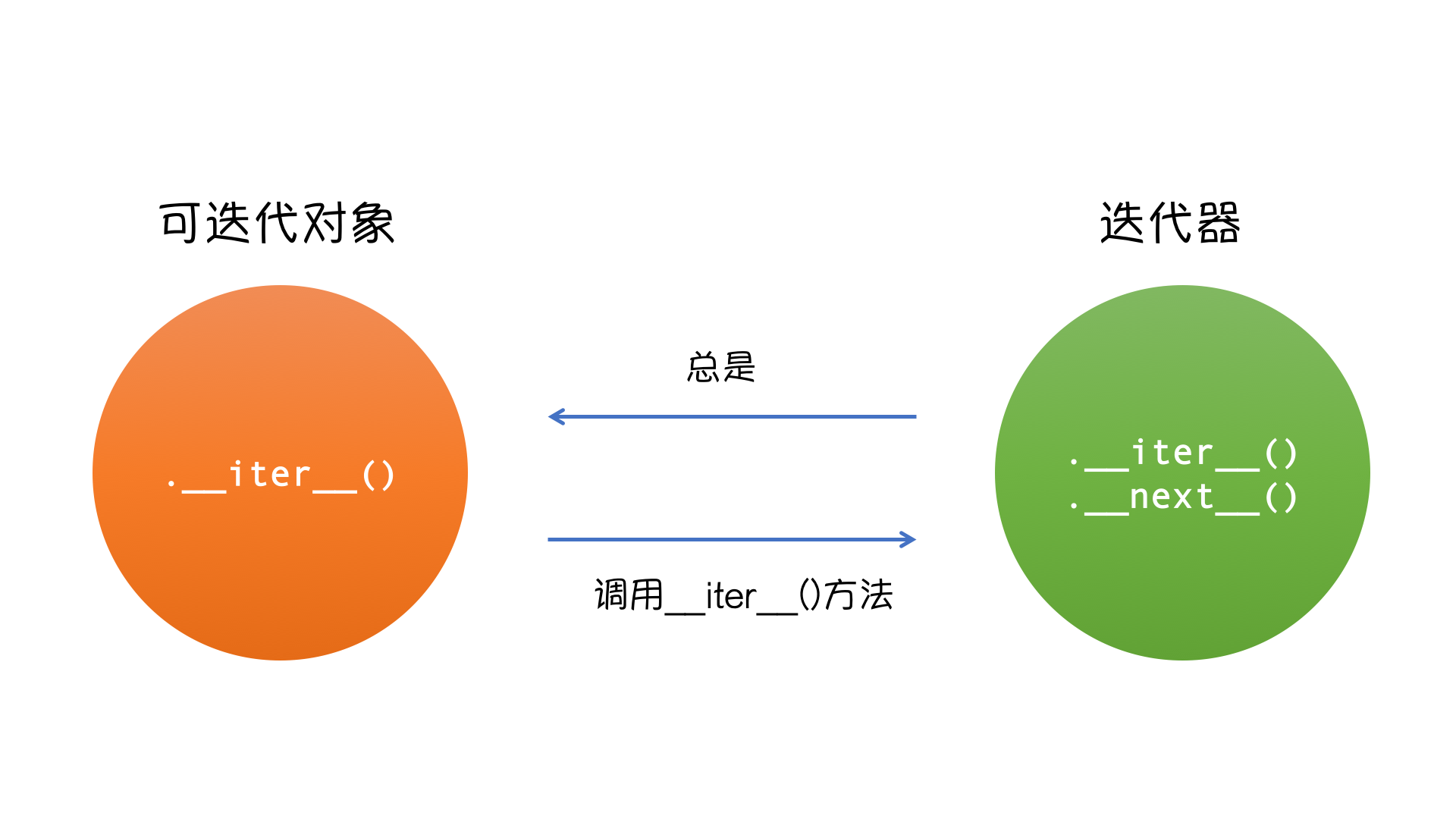
- 内置有__iter__方法的对象就是可迭代对象。
- 内置有__iter__方法和__next__方法的对象就是迭代器对象。
- 可迭代对象执行obj.__iter__()得到的结果就是迭代器对象。
- 迭代器对象指的是即内置有__iter__又内置有__next__方法的对象。
- 迭代器对象.__iter__()后仍然是迭代器对象本身,文件类型是迭代器对象open('a.txt').__iter__()open('a.txt').__next__()
- 迭代器遵循迭代器协议 :必须拥有__iter__方法和__next__方法。
- for循环就是基于迭代器协议提供了一个统一的可以遍历所有对象的方法,即在遍历之前,先调用对象的__iter__方法将其转换成一个迭代器,然后使用迭代器协议去实现循环访问,这样所有的对象就都可以通过for循环来遍历了
1、迭代
迭代就是重复,下一次的重复是基于上一次的结果。
2、迭代器
python为了提供一种不依赖于索引的迭代方式,
python会为一些对象内置__iter__方法
obj.__iter__称为可迭代的对象
可以直接作用于for循环的数据类型有以下几种:
一类是集合数据类型,如list、tuple、dict、set、str等;
一类是generator,包括生成器和带yield的generator function。
这些可以直接作用于for循环的对象统称为可迭代对象:Iterable。
可以使用isinstance()判断一个对象是否是Iterable对象:
>>> from collections import Iterable >>> isinstance([], Iterable) True >>> isinstance({}, Iterable) True >>> isinstance('abc', Iterable) True >>> isinstance((x for x in range(10)), Iterable) True >>> isinstance(100, Iterable) False
而生成器不但可以作用于for循环,还可以被next()函数不断调用并返回下一个值,直到最后抛出StopIteration错误表示无法继续返回下一个值了。
可以被next()函数调用并不断返回下一个值的对象称为迭代器:Iterator。
可以使用isinstance()判断一个对象是否是Iterator对象:
>>> from collections import Iterator >>> isinstance((x for x in range(10)), Iterator) True >>> isinstance([], Iterator) False >>> isinstance({}, Iterator) False >>> isinstance('abc', Iterator) False
生成器都是Iterator对象,但list、dict、str虽然是Iterable,却不是Iterator。
把list、dict、str等Iterable变成Iterator可以使用iter()函数:
>>> isinstance(iter([]), Iterator) True >>> isinstance(iter('abc'), Iterator) True
你可能会问,为什么list、dict、str等数据类型不是Iterator?
这是因为Python的Iterator对象表示的是一个数据流,Iterator对象可以被next()函数调用并不断返回下一个数据,直到没有数据时抛出StopIteration错误。可以把这个数据流看做是一个有序序列,但我们却不能提前知道序列的长度,只能不断通过next()函数实现按需计算下一个数据,所以Iterator的计算是惰性的,只有在需要返回下一个数据时它才会计算。
Iterator甚至可以表示一个无限大的数据流,例如全体自然数。而使用list是永远不可能存储全体自然数的。
小结
凡是可作用于for循环的对象都是Iterable类型;
凡是可作用于next()函数的对象都是Iterator类型,它们表示一个惰性计算的序列;
集合数据类型如list、dict、str等是Iterable但不是Iterator,不过可以通过iter()函数获得一个Iterator对象。
迭代器的优点
1:提供了一种不依赖于索引的取值方式
2:惰性计算。节省内存
迭代器的缺点:
1:取值不如按照索引取值方便
2:一次性的。只能往后走不能往前退
3:无法获取长度
Python的for循环本质上就是通过不断调用next()函数实现的,例如:
for x in [1, 2, 3, 4, 5]: pass
实际上完全等价于:
# 首先获得Iterator对象: it = iter([1, 2, 3, 4, 5]) # 循环: while True: try: # 获得下一个值: x = next(it) except StopIteration: # 遇到StopIteration就退出循环 break
""" #优点: - 提供一种统一的、不依赖于索引的迭代方式 - 惰性计算,节省内存 #缺点: - 无法获取长度(只有在next完毕才知道到底有几个值) - 一次性的,只能往后走,不能往前退,迭代完,就不能再次迭代 """ dic={'a':1,'b':2,'c':3} iter_dic=dic.__iter__() #得到迭代器对象,迭代器对象即有__iter__又有__next__ 迭代器对象.__iter__()后仍然是迭代器对象本身 print(iter_dic) #<dict_keyiterator object at 0x0000000000BA99F8> print(iter_dic.__iter__()) #<dict_keyiterator object at 0x0000000000BD99F8> print(iter_dic.__iter__() is iter_dic) #True 迭代器对象.__iter__()后仍然是迭代器对象本身 print(iter_dic.__next__()) #等同于next(iter_dic) print(iter_dic.__next__()) #等同于next(iter_dic) print(iter_dic.__next__()) #等同于next(iter_dic) # print(iter_dic.__next__()) #抛出异常StopIteration,或者说结束标志 #有了迭代器,我们就可以不依赖索引迭代取值了 iter_dic=dic.__iter__() while 1: try: k=next(iter_dic) print(k,dic[k]) except StopIteration: # 需要我们自己捕捉异常 break #基于for循环,我们可以完全不再依赖索引去取值了 dic={'a':1,'b':2,'c':3} for k in dic: print(k, dic[k]) print('123123213') for k in dic: print(k, dic[k]) #for循环的工作原理 #1:执行in后对象的dic.__iter__()方法,得到一个迭代器对象iter_dic #2: 执行next(iter_dic),将得到的值赋值给k,然后执行循环体代码 #3: 重复过程2,直到捕捉到异常StopIteration,结束循环
dir([1,2].__iter__())#是列表迭代器中实现的所有方法, dir([1,2]) #是列表中实现的所有方法,都是以列表的形式返回,为了看的更清楚,分别把他们转换成集合,然后取差集。 # print(dir([1,2].__iter__())) # 返回一个列表 # print(dir([1,2])) print(set(dir([1,2].__iter__()))-set(dir([1,2]))) #{'__length_hint__', '__next__', '__setstate__'} #列表迭代器中多了三个方法 iter_l = [1,2,3,4,5,6].__iter__() #获取迭代器中元素的长度 print(iter_l.__length_hint__()) #6 #根据索引值指定从哪里开始迭代 print('*',iter_l.__setstate__(4)) #* None #一个一个的取值 print('**',iter_l.__next__()) #** 5 print('***',iter_l.__next__()) #*** 6 print('__next__' in dir(range(12))) #False print('__iter__' in dir(range(12))) #True from collections import Iterator print(isinstance(range(100000000),Iterator)) # False 验证range执行之后得到的结果不是一个迭代器
from collections import Iterable,Iterator class Foo: def __init__(self,start): self.start=start def __iter__(self): return self def __next__(self): return 'aSB' f=Foo(0) print(isinstance(f,Iterable)) #True 可迭代 print(isinstance(f,Iterator)) #True 迭代器
三元表达式
格式:result=值1 if x<y else 值2
满足if条件result=值1,否则result=值2
>>> 3 if 3>2 else 10 3 >>> 3 if 3>4 else 10 10 >>> 3+2 if 3>0 else 3-1 5 >>> 3+2 if 3>0 and 3>4 else 3-1 2
列表解析
1 s='hello' 2 res=[i.upper() for i in s] 3 print(res) 4 5 ['H','E','L','L','O']
l=[1,31,73,84,57,22] l_new=[] #一般写法 for i in l: if i > 50: l_new.append(i) print(l_new) #解析式写法 res=[i for i in l if i > 50] print(res)
for i in obj1: if 条件1: for i in obj2: if 条件2: for i in obj3: if 条件3: ... l=[1,31,73,84,57,22] print([i for i in l if i > 50]) print([i for i in l if i < 50]) print([i for i in l if i > 20 and i < 50])
生成器Generator
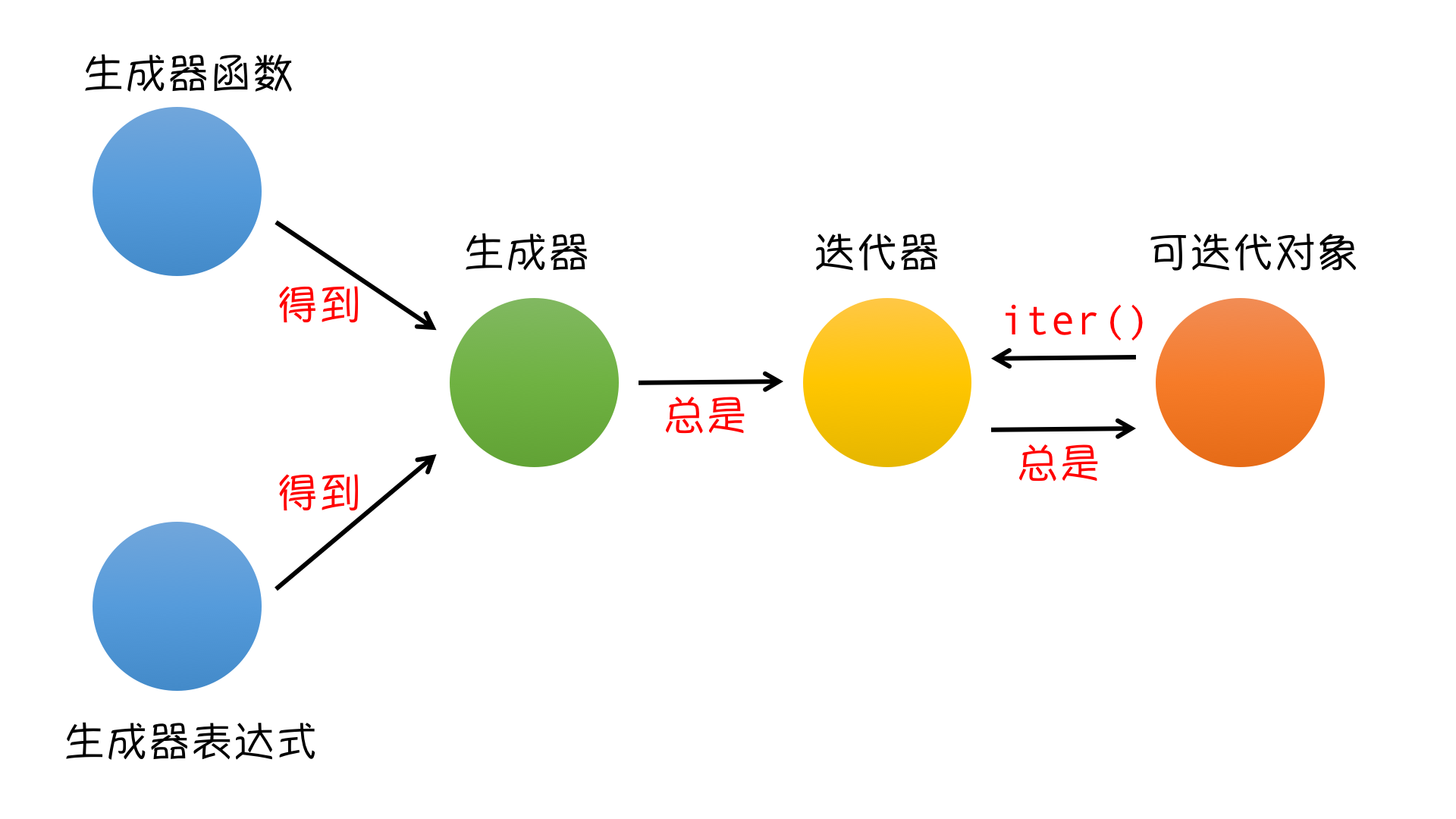
- 迭代器有两种:一种是调用方法直接返回的,一种是可迭代对象通过执行 iter方法得到的
- 迭代器有的好处是可以节省内存。
- 如果在某些情况下,我们也需要节省内存,就只能自己写。自己写的这个能实现迭代器功能的东西就叫生成器。
- 生成器本质:迭代器 ( 所以自带了 __iter__方法和 __next__方法,不需要我们去实现)
- 特点:惰性运算,开发者自定义
- 生成器本质上就是个迭代器,我们根据自己的想法创造的迭代器,支持for循环
一、生成器表达式
- 把列表解析的[]换成()得到的就是生成器表达式
- 列表解析与生成器表达式都是一种便利的编程方式,只不过生成器表达式更节省内存
- Python不但使用迭代器协议,让for循环变得更加通用。大部分内置函数,也是使用迭代器协议访问对象的。
通过列表生成式,我们可以直接创建一个列表。但是,受到内存限制,列表容量肯定是有限的。而且,创建一个包含100万个元素的列表,不仅占用很大的存储空间,如果我们仅仅需要访问前面几个元素,那后面绝大多数元素占用的空间都白白浪费了。
所以,如果列表元素可以按照某种算法推算出来,那我们是否可以在循环的过程中不断推算出后续的元素呢?这样就不必创建完整的list,从而节省大量的空间。在Python中,这种一边循环一边计算的机制,称为生成器:generator。
要创建一个generator,有很多种方法。第一种方法很简单,只要把一个列表生成式的[]改成(),就创建了一个generator:
>>> L = [x * x for x in range(10)] >>> L [0, 1, 4, 9, 16, 25, 36, 49, 64, 81] >>> g = (x * x for x in range(10)) >>> g <generator object <genexpr> at 0x1022ef630>
创建L和g的区别仅在于最外层的[]和(),L是一个list,而g是一个generator。
我们可以直接打印出list的每一个元素,但我们怎么打印出generator的每一个元素呢?
如果要一个一个打印出来,可以通过next()函数获得generator的下一个返回值:
>>> next(g) 0 >>> next(g) 1 >>> next(g) 4 >>> next(g) 9 >>> next(g) 16 >>> next(g) 25 >>> next(g) 36 >>> next(g) 49 >>> next(g) 64 >>> next(g) 81 >>> next(g) Traceback (most recent call last): File "<stdin>", line 1, in <module> StopIteration
我们讲过,generator保存的是算法,每次调用next(g),就计算出g的下一个元素的值,直到计算到最后一个元素,没有更多的元素时,抛出StopIteration的错误。
当然,上面这种不断调用next(g)实在是太变态了,正确的方法是使用for循环,因为generator也是可迭代对象:
>>> g = (x * x for x in range(10)) >>> for n in g: ... print(n) ... 0 1 4 9 16 25 36 49 64 81
所以,我们创建了一个generator后,基本上永远不会调用next(),而是通过for循环来迭代它,并且不需要关心StopIteration的错误。
""" 生成器表达式: 优点:省内存,一次只产生一个值在内存中 把列表推导式的[]换成()就是生成器表达式 """ gen_exp = (i for i in range(10)) #生成器表达式 print(gen_exp) #<generator object <genexpr> at 0x0000000000A1DEB8> # for i in gen_exp: #取出生成器表达式的值,for循环 # print(i) print(gen_exp.__next__()) #next方法 print(gen_exp.__next__()) print(gen_exp.__next__())
egg_list=['鸡蛋%s' %i for i in range(10)] #列表解析 print(egg_list) #['鸡蛋0', '鸡蛋1', '鸡蛋2', '鸡蛋3', '鸡蛋4', '鸡蛋5', '鸡蛋6', '鸡蛋7', '鸡蛋8', '鸡蛋9'] laomuji=('鸡蛋%s' %i for i in range(10))#生成器表达式 print(laomuji) #<generator object <genexpr> at 0x0000000000BA3938> print(next(laomuji)) #鸡蛋0 next本质就是调用__next__ print(laomuji.__next__()) #鸡蛋1 print(next(laomuji)) #鸡蛋2 #sum函数是Python的内置函数,该函数使用迭代器协议访问对象,而生成器实现了迭代器协议,所以,可以直接这样计算一系列值的和: print(sum([x ** 2 for x in range(4)])) #14 #而不用多此一举的先构造一个列表: print(sum(x ** 2 for x in range(4))) #14 ################################### def demo(): for i in range(4): yield i g=demo() g1=(i for i in g) g2=(i for i in g1) print(list(g1),type(g1)) #[0, 1, 2, 3] <class 'generator'> print(list(g2)) #[] ################################### def demo(): for i in range(4): yield i g=demo() g1=[i for i in g] g2=(i for i in g1) print(list(g1),type(g1)) #[0, 1, 2, 3] <class 'list'> print(list(g2)) #[0, 1, 2, 3] print(list(g2)) #[]
二、生成器函数
- 一个包含yield关键字的函数就是一个生成器函数。
- yield和return一样可以从函数中返回值,但是yield又不同于return,return的执行意味着程序的结束,只能返回一次,yield可以返回多次。
- 调用生成器函数不会得到返回的具体的值,而是得到一个生成器对象。
- 每一次从这个可迭代对象获取值,就能推动函数的执行,获取新的返回值。直到函数执行结束(yield像是拥有能够让函数暂停的魔力)。
- 生成器有什么好处呢?就是不会一下子在内存中生成太多数据
generator非常强大。如果推算的算法比较复杂,用类似列表生成式的for循环无法实现的时候,还可以用函数来实现。
比如,著名的斐波拉契数列(Fibonacci),除第一个和第二个数外,任意一个数都可由前两个数相加得到:
1, 1, 2, 3, 5, 8, 13, 21, 34, ...
斐波拉契数列用列表生成式写不出来,但是,用函数把它打印出来却很容易:
def fib(max): n, a, b = 0, 0, 1 while n < max: print(b) a, b = b, a + b n = n + 1 return 'done'
注意,赋值语句:
a, b = b, a + b
相当于:
t = (b, a + b) # t是一个tuple a = t[0] b = t[1]
但不必显式写出临时变量t就可以赋值。
上面的函数可以输出斐波那契数列的前N个数:
>>> fib(6) 1 1 2 3 5 8 'done'
仔细观察,可以看出,fib函数实际上是定义了斐波拉契数列的推算规则,可以从第一个元素开始,推算出后续任意的元素,这种逻辑其实非常类似generator。
也就是说,上面的函数和generator仅一步之遥。要把fib函数变成generator,只需要把print(b)改为yield b就可以了:
def fib(max): n, a, b = 0, 0, 1 while n < max: yield b a, b = b, a + b n = n + 1 return 'done'
这就是定义generator的另一种方法。
如果一个函数定义中包含yield关键字,那么这个函数就不再是一个普通函数,而是一个generator:
>>> f = fib(6) >>> f <generator object fib at 0x104feaaa0>
这里,最难理解的就是generator和函数的执行流程不一样。函数是顺序执行,遇到return语句或者最后一行函数语句就返回。
而变成generator的函数,在每次调用next()的时候执行,遇到yield语句返回,再次执行时从上次返回的yield语句处继续执行。
举个简单的例子,定义一个generator,依次返回数字1,3,5:
def odd(): print('step 1') yield 1 print('step 2') yield(3) print('step 3') yield(5)
调用该generator时,首先要生成一个generator对象,然后用next()函数不断获得下一个返回值:
>>> o = odd() >>> next(o) step 1 1 >>> next(o) step 2 3 >>> next(o) step 3 5 >>> next(o) Traceback (most recent call last): File "<stdin>", line 1, in <module> StopIteration
可以看到,odd不是普通函数,而是generator,在执行过程中,遇到yield就中断,下次又继续执行。执行3次yield后,已经没有yield可以执行了,所以,第4次调用next(o)就报错。
回到fib的例子,我们在循环过程中不断调用yield,就会不断中断。当然要给循环设置一个条件来退出循环,不然就会产生一个无限数列出来。
同样的,把函数改成generator后,我们基本上从来不会用next()来获取下一个返回值,而是直接使用for循环来迭代:
>>> for n in fib(6): ... print(n) ... 1 1 2 3 5 8
但是用for循环调用generator时,发现拿不到generator的return语句的返回值。如果想要拿到返回值,必须捕获StopIteration错误,返回值包含在StopIteration的value中:
>>> g = fib(6) >>> while True: ... try: ... x = next(g) ... print('g:', x) ... except StopIteration as e: ... print('Generator return value:', e.value) ... break ... g: 1 g: 1 g: 2 g: 3 g: 5 g: 8 Generator return value: done
生成器就是迭代器
yield的功能:
1.与return类似,都可以返回值,但不一样的地方在于yield返回多次值,而return只能返回一次值
2.为函数封装好了__iter__和__next__方法,把函数的执行结果做成了迭代器
3.遵循迭代器的取值方式obj.__next__(),触发的函数的执行,函数暂停与再继续的状态都是由yield保存的
d={'a':1,'b':2,'c':3}
obj=d.__iter__()
while True:
try:
i=obj.__next__()
print(i)
except StopIteration:
break
def foo(): print('first') yield 1 print('second') yield 2 print('third') yield 3 print('fouth') g=foo() for i in g: print(i)
import time def countdown(n): print('start---->') while n>=0: yield n time.sleep(1) n-=1 print('stop---->') g=countdown(5) for i in g: print(i)
""" 生成器函数: 只要函数内部包含有yield关键字,那么函数名()的到的结果就是生成器,并且不会执行函数内部代码 生成器就是迭代器(执行函数得到生成器) """ def product(): for i in range(1, 3): print("开始生产包子") yield "第 %d 屉包子" % (i) print("卖包子,买完再生产") pro = product() # 生成一个做包子的生成器,相当于做包子的 print(pro) p = print(pro.__next__()) # 卖包子的 print('===') print(pro.__next__()) print('============') for i in pro: print(i) """ <generator object product at 0x00000000006DDEB8> 开始生产包子 第 1 屉包子 === 卖包子,买完再生产 开始生产包子 第 2 屉包子 ============ 卖包子,买完再生产 """ def product(): for i in range(1,3): print("开始生产包子") yield "第 %d 屉包子" %(i) print("卖包子,买完再生产") pro = product() #生成一个做包子的生成器,相当于做包子的 while 1: try: k=next(pro) print(k) except StopIteration: # 需要我们自己捕捉异常 break
#生成器函数 def my_range(): print('我是一个生成器函数') n = 0 while 1: yield n n += 1 #实现开始和结束 def my_range2(start, stop): n = start while n < stop: yield n n += 1 #再进一步,实现步长: def my_range3(start, stop, step): n = start while n < stop: yield n n += step #生成器本质上就是个迭代器,我们根据自己的想法创造的迭代器,它当然也支持for循环: for i in my_range3(1, 10, 2): print(i)
import time def tail(filename): f = open(filename) f.seek(0, 2) #从文件末尾算起 while True: line = f.readline() # 读取文件中新的文本行 if not line: time.sleep(0.1) continue yield line tail_g = tail('tmp') for line in tail_g: print(line)
def gen1(): for c in 'AB': yield c for i in range(3): yield i print(gen1()) #['A', 'B', 0, 1, 2] def gen2(): yield from 'AB' yield from range(3) print(list(gen2())) #['A', 'B', 0, 1, 2]
import pickle class Course: def __init__(self,name,price,period,teacher): self.name = name self.price = price self.period = period self.teacher = teacher def get_course(): with open('course_info', 'rb') as f: while True: try: course_obj = pickle.load(f) yield course_obj except EOFError: break cour=get_course() print(cour) print(cour.__iter__()) print(cour.__next__()) print(cour.__next__()) for obj in cour: print(obj.name) ############################ def get_line(): with open('a.txt', encoding='utf-8', mode='r') as f: while True: try: line = f.readline() yield line except StopIteration: break g=get_line() print(g) print(g.__next__()) print(g.__next__()) print(g.__next__())
三、协程函数(yield的表达形式)
- yield可以返回值,也可以接收值。
- 通过生成器的send方法可以给yield传值。
- send两个作用:1.给yield传值 2.继续执行函数
def foo(): print('starting') while True: x=yield None#return 2 print('value :',x) g=foo() print(next(g)) print(g.send(2)) 运行结果: starting #运行函数,打印starting后碰到yield停住 None #next()触发后 yield将None赋值给x,打印None后循环碰到yield停住 value : 2 #g.send(2)将2赋值给yield,yield将2赋值给x,继续循环打印出2碰到yield停住 None #碰到yield停住并返回None,print的结果就是None
以上将yield接受到的值赋值给了x,这样形式就叫做yield的表达式形式。
函数foo中有yield,那它就是迭代器。可以使用next()。yield可以返回结果,默认为None。
g.send()前生成器必须先next一次才能发送值。所以写一个装饰器,让foo自动next一次。
def init(func): def wrapper(*args,**kwargs): g=func(*args,**kwargs) next(g) return g return wrapper @init #foo=init(foo) def foo(): print('starting') while True: x=yield print('value :',x) g=foo() #wrapper() g.send(2) 运行结果: starting value :2
send的效果:
1:先从为暂停位置的那个yield传一个值,然后yield会把值赋值x
2:与next的功能一样
# _*_ coding:utf-8 _*_ def init(func): def wrapper(*args,**kwargs): g=func(*args,**kwargs) next(g) return g return wrapper @init def eater(name): print('%s ready to eat'%name) food_list=[] while True: food=yield food_list food_list.append(food) print('%s start to eat %s'%(name,food)) e=eater('alex') print(e.send('food1')) print(e.send('food2')) print(e.send('food3')) 运行结果: alex ready to eat alex start to eat food1 ['food1'] alex start to eat food2 ['food1', 'food2'] alex start to eat food3 ['food1', 'food2', 'food3']
""" 协程函数: yield关键字的另外一种使用形式:表达式形式的yield 对于表达式形式的yield,在使用时,第一次必须传None,g.send(None)等同于next(g) yield总结 1、把函数做成迭代器 2、对比return,可以返回多次值,可以挂起/保存函数的运行状态 """ def eater(name): print('%s 准备开始吃饭啦' % name) food_list = [] for i in range(4): food = yield food_list print('%s 吃了 %s' % (name, food)) food_list.append(food) print('while', food_list) # print('eater',food_list) ####这的代码不会执行,还没有走到这程序就退出了 g = eater('tom') print(g) g.send(None) # 对于表达式形式的yield,在使用时,第一次必须传None,g.send(None)等同于next(g) print('====') g.send('包子') g.send('米饭') g.send('面条') try: g.send('稀饭') except StopIteration: g.close() #依旧执行后面的print(g) # quit() #后面的print(g)就不执行了 try: g.send('肉夹馍') except StopIteration: g.close() print(g) """ <generator object eater at 0x0000000000BA1BF8> tom 准备开始吃饭啦 ==== tom 吃了 包子 while ['包子'] tom 吃了 米饭 while ['包子', '米饭'] tom 吃了 面条 while ['包子', '米饭', '面条'] tom 吃了 稀饭 while ['包子', '米饭', '面条', '稀饭'] <generator object eater at 0x0000000000BA1BF8> """ # 单线程一边发送,一边执行 import time def consumer(name): print("%s 准备吃包子啦!" % name) while True: food = yield print("包子[%s]来了,被[%s]吃了!" % (food, name)) def producer(name): c = consumer('顾客A') c2 = consumer('顾客B') c.__next__() c2.__next__() print("老板%s==开始准备做包子啦!" % name) for i in range(3): time.sleep(1) print("做了2个包子!") c.send(i) # 发送的值,就是yield的返回值 c2.send(i) producer("tom") print('===========') producer("jack") """ 顾客A 准备吃包子啦! 顾客B 准备吃包子啦! 老板tom==开始准备做包子啦! 做了2个包子! 包子[0]来了,被[顾客A]吃了! 包子[0]来了,被[顾客B]吃了! 做了2个包子! 包子[1]来了,被[顾客A]吃了! 包子[1]来了,被[顾客B]吃了! 做了2个包子! 包子[2]来了,被[顾客A]吃了! 包子[2]来了,被[顾客B]吃了! =========== 顾客A 准备吃包子啦! 顾客B 准备吃包子啦! 老板jack==开始准备做包子啦! 做了2个包子! 包子[0]来了,被[顾客A]吃了! 包子[0]来了,被[顾客B]吃了! 做了2个包子! 包子[1]来了,被[顾客A]吃了! 包子[1]来了,被[顾客B]吃了! 做了2个包子! 包子[2]来了,被[顾客A]吃了! 包子[2]来了,被[顾客B]吃了! """
# def eat(name): # print('%s要开始吃了!' % name) # while 1: # food = yield # print('{}在吃{}'.format(name, food)) # # # a = eat('alex') # a.__next__() # 初始化,让函数暂停在yield处 # a.send('包子') # send两个作用:1.给yield传值 2.继续执行函数 # a.send('饺子') def init(func): #在调用被装饰生成器函数的时候首先用next激活生成器 def inner(*args,**kwargs): g = func(*args,**kwargs) next(g) return g return inner @init def averager(): total = 0.0 count = 0 average = None while True: term = yield average total += term count += 1 average = total/count g_avg = averager() # next(g_avg) 在装饰器中执行了next方法 print(g_avg.send(10)) #10.0 print(g_avg.send(30)) #20.0 print(g_avg.send(5)) #15.0