一、Linux三剑客-Sed
1、Sed是什么
Sed:字符流编辑器,Stream Editor
2、Sed功能与版本
处理日志文件,日志,配置文件等
增加、删除、修改、查询
sed --version 可以通过man sed 来检验系统中有没有安装sed
[root@luffy-001 ~]# sed --version GNU sed version 4.2.1 Copyright (C) 2009 Free Software Foundation, Inc. This is free software; see the source for copying conditions. There is NO warranty; not even for MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE, to the extent permitted by law. GNU sed home page: <http://www.gnu.org/software/sed/>. General help using GNU software: <http://www.gnu.org/gethelp/>. E-mail bug reports to: <bug-gnu-utils@gnu.org>. Be sure to include the word ``sed'' somewhere in the ``Subject:'' field.
3、语法格式
sed [选项] [sed指令] [输入文件]
sed -i.bak ‘s#oldboy#oldgirl#g’ oldboy.txt
-i --sed命令的参数
s --sed命令/指令
g ------小尾巴/修饰
4、命令执行流程
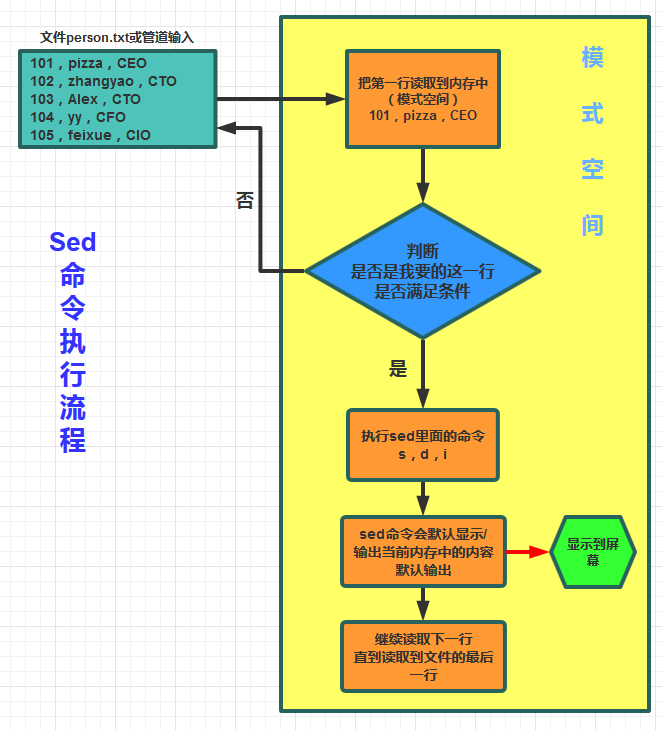
模式空间:sed从文件读取一行文本后存入缓存区(这个缓存区在内存中)
5、常用功能
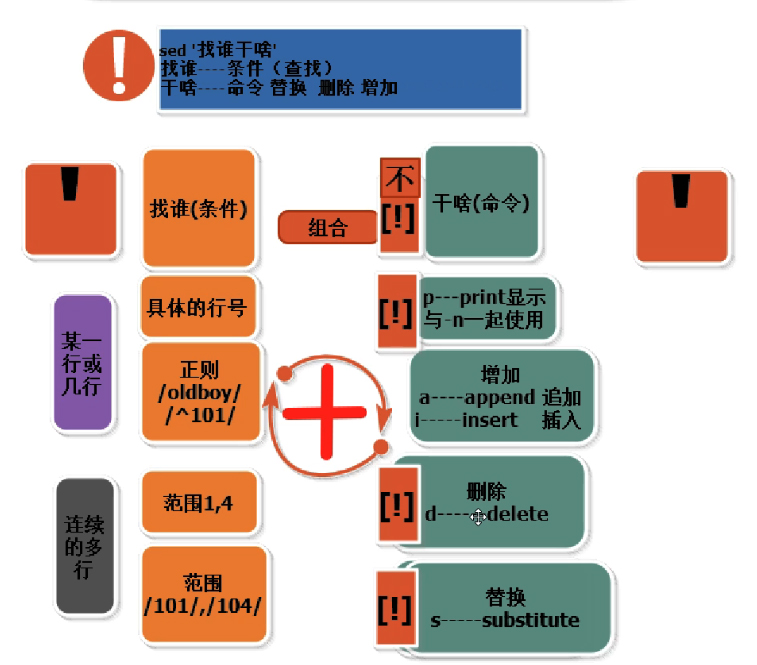
查询
创建测试文件
cat>person.txt<<EOF 101,oldboy,CEO 102,zhangyao,CTO 103,Alex,COO 104,yy,CFO 105,feixue,CIO EOF
按行查询
-n 取消默认输出
# #1、显示某一行,单行 [root@luffy-001 oldboy]# sed -n '1p' person.txt 101,oldboy,CEO # #如果没有‘1p’,默认会显示所有内容 # #2、显示连续多行 [root@luffy-001 oldboy]# sed -n '2,4p' person.txt 102,zhangyao,CTO 103,Alex,COO 104,yy,CFO # #3、显示包含oldboy的行到包含104的行 # #先看包含oldboy的行,记住要使用斜线//包起来 [root@luffy-001 oldboy]# sed -n '/oldboy/p' person.txt 101,oldboy,CEO # #显示包含oldboy的行到以104开头的行(只用了特殊符号) [root@luffy-001 oldboy]# sed -n '/oldboy/,/^104/p' person.txt 101,oldboy,CEO 102,zhangyao,CTO 103,Alex,COO 104,yy,CFO [root@luffy-001 oldboy]# # #4、 查询制定更多行,通过分号隔开 [root@luffy-001 oldboy]# sed -n '2p;4p' person.txt 102,zhangyao,CTO 104,yy,CFO
过滤多个字符
-r sed选项,支持扩展正则表达式(|、()),默认情况,sed只支持基本正则表达式
sed里面的正则字符左右必须要用“/”。
sed命令通过正则表达式进行过滤========相当于egrep
[root@luffy-001 oldboy]# egrep 'oldboy|yy' person.txt 101,oldboy,CEO 104,yy,CFO [root@luffy-001 oldboy]# sed -rn '/oldboy|yy/p' person.txt 101,oldboy,CEO 104,yy,CFO
增加
单行增加
a 追加append,在指定行后面添加一行或者多行文本
i 插入insert,在指定行前面添加一行或者多行文本
# 在第三行后面增加 [root@luffy-001 oldboy]# sed '3a 103.5,Lee,UFO' person.txt 101,oldboy,CEO 102,zhangyao,CTO 103,Alex,COO 103.5,Lee,UFO 104,yy,CFO 105,feixue,CIO # 在第三行前面增加 [root@luffy-001 oldboy]# sed '3i 103.5,Lee,UFO' person.txt 101,oldboy,CEO 102,zhangyao,CTO 103.5,Lee,UFO 103,Alex,COO 104,yy,CFO 105,feixue,CIO # 查看文件并没有被修改 [root@luffy-001 oldboy]# cat person.txt 101,oldboy,CEO 102,zhangyao,CTO 103,Alex,COO 104,yy,CFO 105,feixue,CIO # $表示最后一行 [root@luffy-001 oldboy]# sed -n '$p' person.txt 105,feixue,CIO # 在最后一行加入一行内容new、new、new [root@luffy-001 oldboy]# sed '$a new,new,new' person.txt 101,oldboy,CEO 102,zhangyao,CTO 103,Alex,COO 104,yy,CFO 105,feixue,CIO new,new,new
# echo >> 也可以在文件最后追加单行
多行增加
# 在最后加上多行(不常用,有其他方法) [root@luffy-001 oldboy]# sed '$a new,new,new old,old,old,old www' person.txt 101,oldboy,CEO 102,zhangyao,CTO 103,Alex,COO 104,yy,CFO 105,feixue,CIO new,new,new old,old,old,old www # 使用cat命令向文件追加多行 cat >>person.txt<<EOF new,new,new old,old,old,old www EOF
删除
单行删除
[root@luffy-001 oldboy]# sed '$d' person.txt 101,oldboy,CEO 102,zhangyao,CTO 103,Alex,COO 104,yy,CFO
多行删除
[root@luffy-001 oldboy]# sed '2,3d' person.txt 101,oldboy,CEO 104,yy,CFO 105,feixue,CIO [root@luffy-001 oldboy]# sed '1,4d' person.txt 105,feixue,CIO
不显示文件中的空行
[root@luffy-001 oldboy]# cat -n person.txt 1 101,oldboy,CEO 2 3 102,zhangyao,CTO 4 103,Alex,COO 5 6 104,yy,CFO 7 8 105,feixue,CIO [root@luffy-001 oldboy]# cat -nA person.txt 1 101,oldboy,CEO$ 2 $ 3 102,zhangyao,CTO$ 4 103,Alex,COO$ 5 $ 6 104,yy,CFO$ 7 $ 8 105,feixue,CIO$ [root@luffy-001 oldboy]# grep -v '^$' person.txt 使用grep,去反 101,oldboy,CEO 102,zhangyao,CTO 103,Alex,COO 104,yy,CFO 105,feixue,CIO [root@luffy-001 oldboy]# sed '/^$/d' person.txt 使用sed(正则)删除空行 101,oldboy,CEO 102,zhangyao,CTO 103,Alex,COO 104,yy,CFO 105,feixue,CIO [root@luffy-001 oldboy]# sed -n '/^$/!p' person.txt ! 表示去反 101,oldboy,CEO 102,zhangyao,CTO 103,Alex,COO 104,yy,CFO 105,feixue,CIO [root@luffy-001 oldboy]# sed '$d' person.txt 删除最后一行 101,oldboy,CEO 102,zhangyao,CTO 103,Alex,COO 104,yy,CFO [root@luffy-001 oldboy]# sed '$!d' person.txt 删除不是最后一行的所有行 105,feixue,CIO [root@luffy-001 oldboy]#
替换
sed -i ‘s###g’ person.txt
-i 修改文件 -i.ori 表示自动备份(先备份在修改)
s 单独使用----> 将每一行匹配的字符进行替换
g 每一行全部替换----> sed指令s的替换标志之一(全局替换)
如何用sed进行变量替换
###将变量中的内容进行替换(只要考察单双引号的区别) #设置变量 [root@luffy-001 oldboy]# x=oldboy [root@luffy-001 oldboy]# y=oldgirl [root@luffy-001 oldboy]# #替换 使用 符号$ [root@luffy-001 oldboy]# sed 's#$x#$y#g' person.txt 101,oldboy,CEO 102,zhangyao,CTO 103,Alex,COO 104,yy,CFO 105,feixue,CIO #必须要使用双引号 [root@luffy-001 oldboy]# sed "s#$x#$y#g" person.txt 101,oldgirl,CEO 102,zhangyao,CTO 103,Alex,COO 104,yy,CFO 105,feixue,CIO
单引号:所见即所得
双引号:与单引号类似,特殊符号会被解析 $ $() `` !
反向引用
()的功能可以记住正则表达式的一部分
扩展正则,使用 -r
1 应用第一个小括号中的匹配内容,2引用第二个小括号中的内容,sed最多可以记住9个
题目:ehco "i am oldboy teacher" 如果想保留这一行的单词oldboy
扩展
特殊符号 = 获取行号
[root@luffy-001 oldboy]# sed = person.txt 1 101,oldboy,CEO 2 3 102,zhangyao,CTO 4 103,Alex,COO 5 6 104,yy,CFO 7 8 105,feixue,CIO
一条sed 语句至此那个多条命令
每个 -e 选项后可以接一个sed指令
分号的使用
案例:一个文件100行,把5,35,70行单独拿出来
二、Linux三剑客-awk
1、什么是awk
AWK是一种处理文本文件的语言,是一个强大的文本分析工具。有统计和计算功能。
之所以叫AWK是因为其取了三位创始人 Alfred Aho,Peter Weinberger, 和 Brian Kernighan 的 Family Name 的首字符。
参数说明
选项参数说明: -F fs or --field-separator fs 指定输入文件折分隔符,fs是一个字符串或者是一个正则表达式,如-F:。 -v var=value or --asign var=value 赋值一个用户定义变量。 -f scripfile or --file scriptfile 从脚本文件中读取awk命令。 -mf nnn and -mr nnn 对nnn值设置内在限制,-mf选项限制分配给nnn的最大块数目;-mr选项限制记录的最大数目。这两个功能是Bell实验室版awk的扩展功能,在标准awk中不适用。 -W compact or --compat, -W traditional or --traditional 在兼容模式下运行awk。所以gawk的行为和标准的awk完全一样,所有的awk扩展都被忽略。 -W copyleft or --copyleft, -W copyright or --copyright 打印简短的版权信息。 -W help or --help, -W usage or --usage 打印全部awk选项和每个选项的简短说明。 -W lint or --lint 打印不能向传统unix平台移植的结构的警告。 -W lint-old or --lint-old 打印关于不能向传统unix平台移植的结构的警告。 -W posix 打开兼容模式。但有以下限制,不识别:/x、函数关键字、func、换码序列以及当fs是一个空格时,将新行作为一个域分隔符;操作符**和**=不能代替^和^=;fflush无效。 -W re-interval or --re-inerval 允许间隔正则表达式的使用,参考(grep中的Posix字符类),如括号表达式[[:alpha:]]。 -W source program-text or --source program-text 使用program-text作为源代码,可与-f命令混用。 -W version or --version 打印bug报告信息的版本。
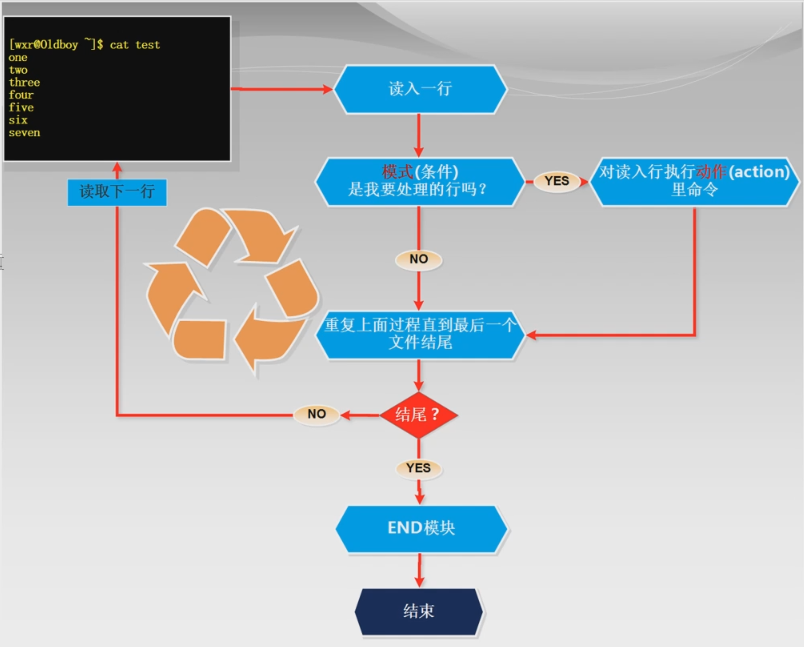
2、awk的执行流程
其执行过程和sed相似,在我们遇到复杂的语句时,可以离利用执行过程来理解
题目:passwd文件的第二行的第一列和第二列
[root@luffy-001 oldboy]# awk -F ':' 'NR==2{print $1,$2}' /etc/passwd bin x
awk 参数 ‘模式{动作}’ 文件
awk 参数 ‘条件(找谁){干啥}’ 文件
awk执行过程简图
3、模式匹配:模式与动作
怎么找到这一行,然后做点什么
通过正则表达式作为模式
创建测试环境
mkdir -p /server/files/ cat >>/server/files/reg.txt<<EOF Zhang Dandan 41117397 :250:100:175 Zhang Xiaoyu 390320151 :155:90:201 Meng Feixue 80042789 :250:60:50 Wu Waiwai 70271111 :250:80:75 Liu Bingbing 41117483 :250:100:175 Wang Xiaoai 3515064655 :50:95:135 Zi Gege 1986787350 :250:168:200 Li Youjiu 918391635 :175:75:300 Lao Nanhai 918391635 :250:100:175 EOF
找出包含数字1的行
[root@luffy-001 files]# sed -n '/1/p' reg.txt Zhang Dandan 41117397 :250:100:175 Zhang Xiaoyu 390320151 :155:90:201 Wu Waiwai 70271111 :250:80:75 Liu Bingbing 41117483 :250:100:175 Wang Xiaoai 3515064655 :50:95:135 Zi Gege 1986787350 :250:168:200 Li Youjiu 918391635 :175:75:300 Lao Nanhai 918391635 :250:100:175 [root@luffy-001 files]# awk '/1/' reg.txt Zhang Dandan 41117397 :250:100:175 Zhang Xiaoyu 390320151 :155:90:201 Wu Waiwai 70271111 :250:80:75 Liu Bingbing 41117483 :250:100:175 Wang Xiaoai 3515064655 :50:95:135 Zi Gege 1986787350 :250:168:200 Li Youjiu 918391635 :175:75:300 Lao Nanhai 918391635 :250:100:175
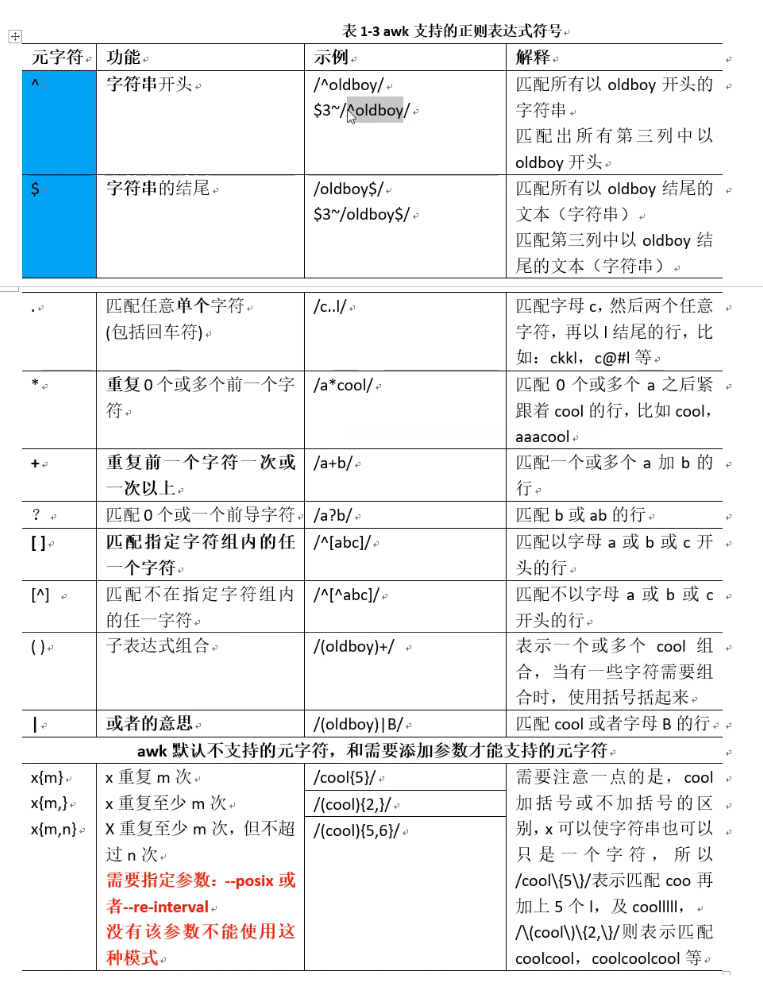
awk支持的正则表达式
|
题目:显示xiaoyu的姓氏和ID号码
[root@luffy-001 files]# awk '/Xiaoyu/' reg.txt Zhang Xiaoyu 390320151 :155:90:201 [root@luffy-001 files]# awk '/Xiaoyu/{print $1,$2,$3}' reg.txt 相当于$0~,$0 在awk中表示这一行,整行记录 Zhang Xiaoyu 390320151 [root@luffy-001 files]# awk '$2~/Xiaoyu/{print $1,$2,$3}' reg.txt 波浪线表示包含,第二列包含xiaoyu的行 的第一列,第二列,第三列 Zhang Xiaoyu 390320151
题目:显示所有以41开头的ID号码的人的全名和ID号码
[root@luffy-001 files]# awk '$3~/^41/{print $1,$2,$3}' reg.txt Zhang Dandan 41117397 Liu Bingbing 41117483
题目:显示所有ID号码最后一位数字是1或5的人的全名
[root@luffy-001 files]# awk '$3~/[15]$/{print $1,$2}' reg.txt Zhang Xiaoyu Wu Waiwai Wang Xiaoai Li Youjiu Lao Nanhai [root@luffy-001 files]# awk '$3~/(1|5)$/{print $1,$2}' reg.txt Zhang Xiaoyu Wu Waiwai Wang Xiaoai Li Youjiu Lao Nanhai
题目:显示Xiaoyu的捐款.每个值时都有以$开头.如$520$200$135
gsub的用法:
gsub(/目标/,"替换为什么",第几列)
gsub(/目标/,"替换为什么") == gsub(/目标/,"替换为什么",$0)
[root@luffy-001 files]# sed 's#:#$#g' reg.txt Zhang Dandan 41117397 $250$100$175 Zhang Xiaoyu 390320151 $155$90$201 Meng Feixue 80042789 $250$60$50 Wu Waiwai 70271111 $250$80$75 Liu Bingbing 41117483 $250$100$175 Wang Xiaoai 3515064655 $50$95$135 Zi Gege 1986787350 $250$168$200 Li Youjiu 918391635 $175$75$300 Lao Nanhai 918391635 $250$100$175 [root@luffy-001 files]# awk '{gsub(/:/,'$',$4);print}' reg.txt awk: {gsub(/:/,,$4);print} awk: ^ syntax error awk: fatal: 0 is invalid as number of arguments for gsub [root@luffy-001 files]# awk '{gsub(/:/,"$",$4);print}' reg.txt Zhang Dandan 41117397 $250$100$175 Zhang Xiaoyu 390320151 $155$90$201 Meng Feixue 80042789 $250$60$50 Wu Waiwai 70271111 $250$80$75 Liu Bingbing 41117483 $250$100$175 Wang Xiaoai 3515064655 $50$95$135 Zi Gege 1986787350 $250$168$200 Li Youjiu 918391635 $175$75$300 Lao Nanhai 918391635 $250$100$175
题目答案:
[root@luffy-001 files]# awk '$2~/Xiaoyu/{gsub(/:/,"$",$4);print}' reg.txt Zhang Xiaoyu 390320151 $155$90$201
特殊模式:BEGIN 和END
BEGIN{} BEGIN里面的内容,会在awk读取文件内容之前运行。
测试,计算。
END{}*** END{}里面的内容,会在awk读取完文件的最后一行之后运行。
用来显示最终结果。
先计算,END显示结果。
[root@luffy-001 files]# awk 'BEGIN{print "this is kt"} {print NR,$0}' reg.txt this is kt 1 Zhang Dandan 41117397 :250:100:175 2 Zhang Xiaoyu 390320151 :155:90:201 3 Meng Feixue 80042789 :250:60:50 4 Wu Waiwai 70271111 :250:80:75 5 Liu Bingbing 41117483 :250:100:175 6 Wang Xiaoai 3515064655 :50:95:135 7 Zi Gege 1986787350 :250:168:200 8 Li Youjiu 918391635 :175:75:300 9 Lao Nanhai 918391635 :250:100:175 [root@luffy-001 files]# awk 'BEGIN{print "this is kt"} END{print "this is kb"} {print NR,$0}' reg.txt this is kt 1 Zhang Dandan 41117397 :250:100:175 2 Zhang Xiaoyu 390320151 :155:90:201 3 Meng Feixue 80042789 :250:60:50 4 Wu Waiwai 70271111 :250:80:75 5 Liu Bingbing 41117483 :250:100:175 6 Wang Xiaoai 3515064655 :50:95:135 7 Zi Gege 1986787350 :250:168:200 8 Li Youjiu 918391635 :175:75:300 9 Lao Nanhai 918391635 :250:100:175 this is kb
题目:统计/etc/services文件里面的空行数量
[root@luffy-001 files]# awk '/^$/{print NR}' /etc/services 22 266 299 320 326 393 461 474 479 486 494 506 512 518 583 584 [root@luffy-001 files]# awk '/^$/{i=i+1;print i}' /etc/services 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 [root@luffy-001 files]# awk '/^$/{i=i+1} END{print i}' /etc/services 16
统计出现多少次 计数
i=i+1 ===> i++
常见用法
##用法一: awk '{[pattern] action}' {filenames} # 行匹配语句 awk '' 只能用单引号 ##用法二: awk -F #-F相当于内置变量FS, 指定分割字符 ##用法三: awk -v # 设置变量 ##用法四: awk -f {awk脚本} {文件名}
4、awk数组:统计与计算
数组怎么使用?
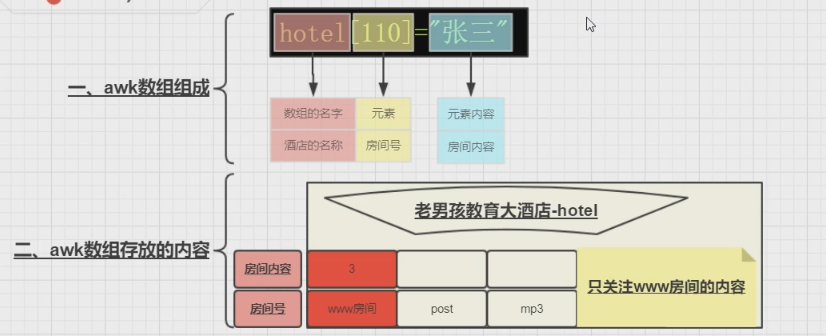
举个例子:
[root@luffy-001 files]# awk 'BEGIN{h[110]="张三";h[114]="XXOO";print h[110],h[114]}' 张三 XXOO
运算符
运算符 描述 = += -= *= /= %= ^= **= 赋值 ?: C条件表达式 || 逻辑或 && 逻辑与 ~ ~! 匹配正则表达式和不匹配正则表达式 < <= > >= != == 关系运算符 空格 连接 + - 加,减 * / % 乘,除与求余 + - ! 一元加,减和逻辑非 ^ *** 求幂 ++ -- 增加或减少,作为前缀或后缀 $ 字段引用 in 数组成员
题目:处理以下文件内容,将域名取出并根据域名进行计数排序处理:(百度和sohu面试题)
http://www.etiantian.org/index.html
http://www.etiantian.org/1.html
http://post.etiantian.org/index.html
http://mp3.etiantian.org/index.html
http://www.etiantian.org/3.html
http://post.etiantian.org/2.html
## 分割后查看,独有的前缀为标记 [root@luffy-001 files]# awk -F '[/.]+' '{print $2}' url.txt www www post mp3 www post ## 使用h[$2]建立数组,并自加,打印出其中一个 [root@luffy-001 files]# awk -F '[/.]+' '{h[$2]++;print h["www"]}' url.txt 1 2 2 2 3 3 ## 答应所有的结果,只是当种类多了之后,没法操作 [root@luffy-001 files]# awk -F '[/.]+' '{h[$2]++} END{print h["www"],h["post"],h["mp3"]}' url.txt 3 2 1 ## awk独有的循环的功能 [root@luffy-001 files]# awk -F '[/.]+' '{h[$2]++} END{for(pol in h) print pol,h[pol]}' url.txt www 3 mp3 1 post 2
题目:统计access.log文件中每个ip地址出现的次数
题目:secure系统日志分析练习
谁在破解你的密码(Failed password 每个ip地址出现的次数)
分析系统的每个用户被破解的次数
## 统计IP登录次数 [root@luffy-001 log]# awk '$0~/Accepted/{h[$11]++}END{for(por in h) print por,h[por]}' secure 10.0.0.1 3
## 统计每个用户被破解的次数
[root@luffy-001 log]# awk '$0~/FAILED LOGIN/{h[$12]++}END{for(por in h) print por,h[por]}' secure
rot, 1
## 统计谁在破解你的密码(Failed password 每个ip地址出现的次数)
[root@luffy-001 log]# awk -F "[()]" '/FAILED/{h[$2]++}END{for(pol in h) print pol, h[pol]}' secure
null 1