第一章-需求分析
数据库设计的概念
数据库的设计,就是根据业务系统的具体需求,结合我们所选用的DBMS,为这个业务系统构造出最有的数据存储模型。并建立好数据库中的表结构及表与表之间的关联关系的过程。使之能有效的对应系统中的数据进行存储,并可以高效的对已经存储的数据进行访问。
数据库设计的步骤
需求分析----->逻辑设计----->物理设计----->维护优化
数据库需求分析的作用点:
- 数据是什么
- 数据有哪些属性
- 数据和属性各自的特点有哪些
使用ER图对数据库进行逻辑建模
数据管理系统的选择,根据数据库自身的特点把逻辑设计转换为物理设计
后期维护
- 新的需求进行建表,建新表之前也要做好前三步,防止后期出现的问题
- 索引优化
- 大表拆分
需求分析
为什么要进行需求分析?
为了设计最优化的数据库,便于后期的扩展和维护,数据越来越多,越来越大会浪费空间,越来越杂乱,是很难处理和维护的
- 了解系统中索要存储的数据
- 了解数据的存储特点,比如有的数据有时效性,有的没有,有时效性的可以采取定期清理
- 了解数据的生命周期,
要搞清楚的一些问题
- 实体及实体之间的关系(1对1,1对多,多对多)
- 实体所包含的属性有什么?属性有很多,哪些属性是可以标识出这个实体的
- 那些属性或属性的组合可以唯一标识一个实体
- 存储上有什么特性,增长量是什么样?
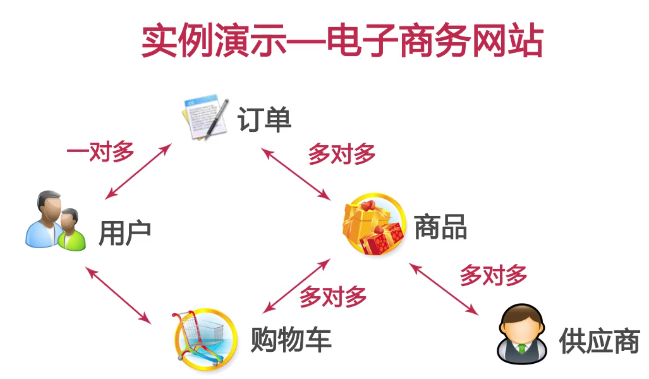
实例分析






第二章-逻辑设计
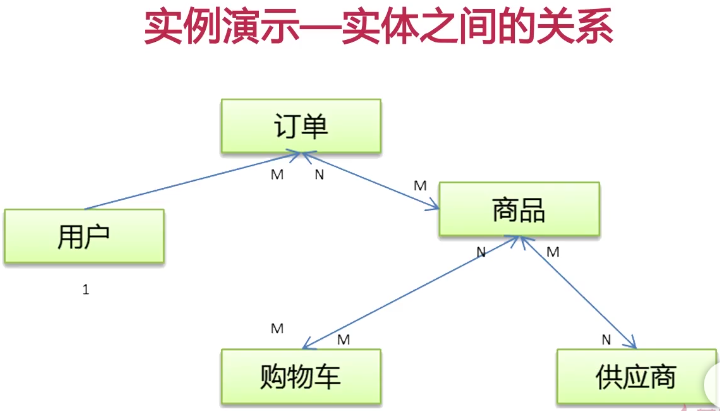
逻辑设计要做什么?ER图就是数据库模型关系的展示图
- 将需求转化为数据库的逻辑模型
- 通过ER图的形式对逻辑模型进行展示
- 同所选用的具体的DBMS无关
名词解释


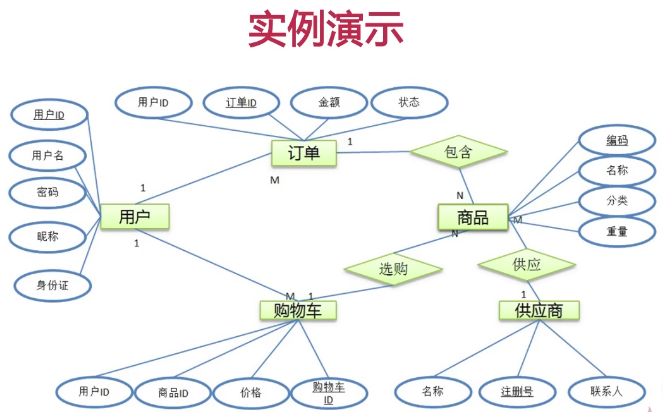
注:有的属性下面有下划线,就表示主键
设计范式概要
什么是数据库设计范式?
也就是提供了一种准则,帮助我们建立简介高效且结构清晰的数据库设计,避免数据库插入,跟新,删除,修改中的异常,并且为最大限度的避免数据库的冗余。
常见的数据库范式包括:第一范式、第二范式、第三范式及BC范式
当然还有第四及第五范式,不过这里我们会把重点放到前三个范式上,
这也是目前我们大多数数据库设计索要遵循的范式
数据库异常以及数据冗余


第一范式
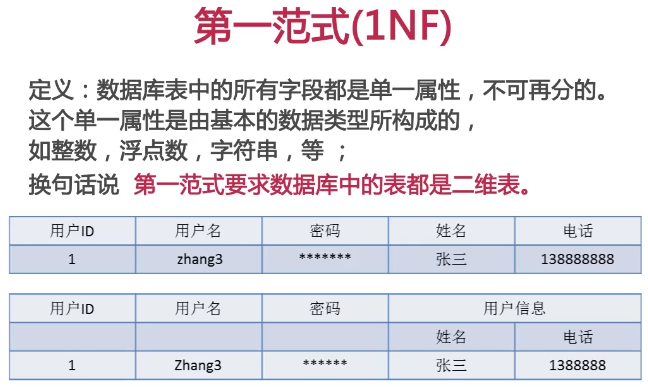
二维表就是由行和列组成的表,图中的第二种表一般是无法创建出来的也是不符合第一范式的,所以,一般情况下,我们创建的表都是符合第一范式的
第二范式
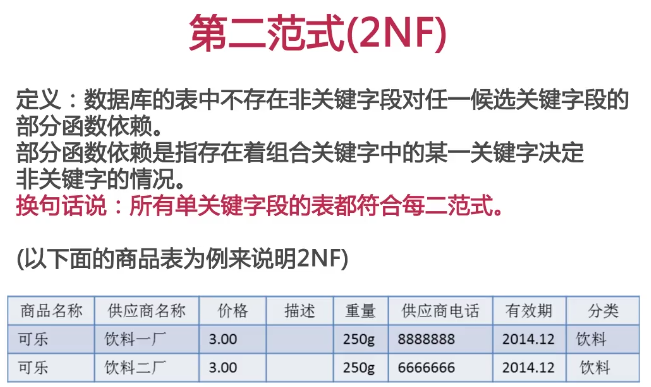
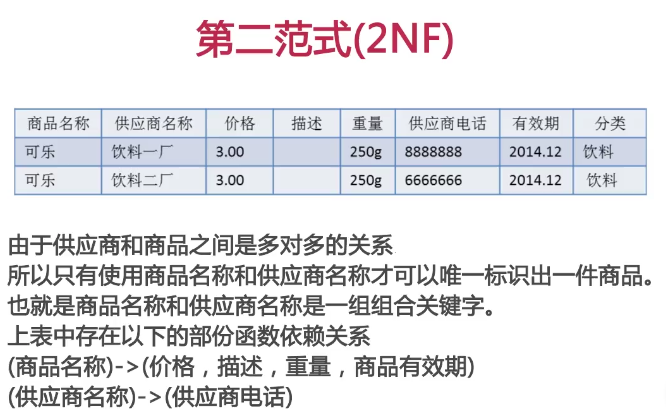
供应商电话和组合关键字存在着部分函数依赖,所以上边的表时不符合第二范式
存在的问题:
- 插入异常---如果饮料一厂不提供任何信息,我们是找不到饮料一厂的其他信息的,
- 删除异常---如果把可乐删除掉,同时,电话和饮料一厂也消失了
- 更新异常---如果有多种商品,那么,跟新一个信息,同时要跟新很多条数据
- 数据冗余---和上面一样,数据冗余了
如何解决
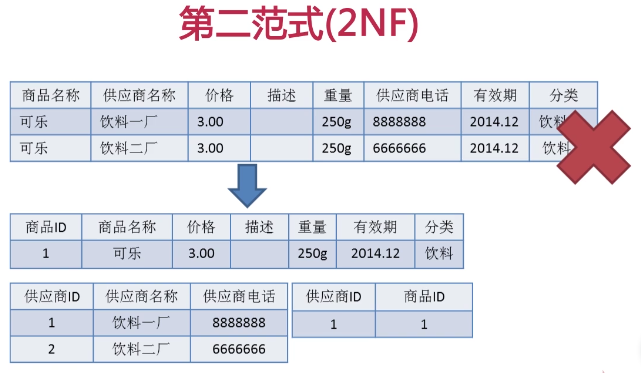
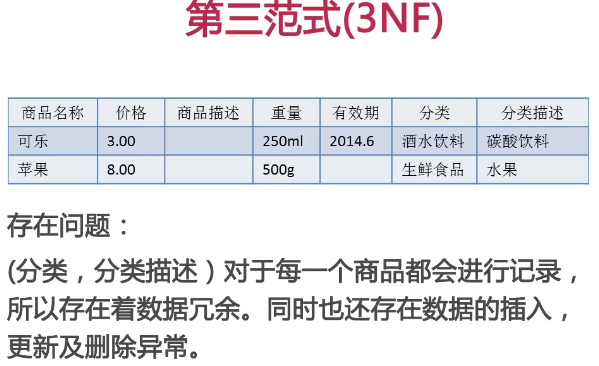
第三范式


所以这是不符合第三范式要求的
修改如下
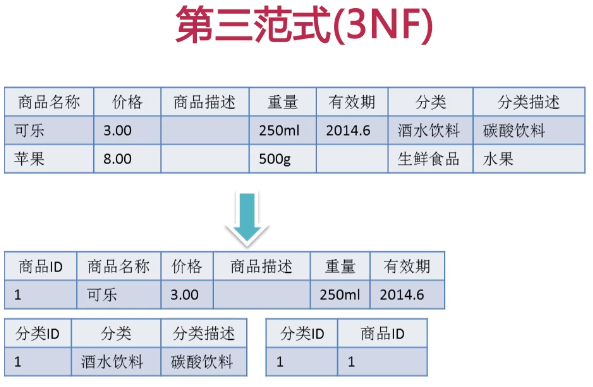
这样,就不会有传递性的依赖关系了
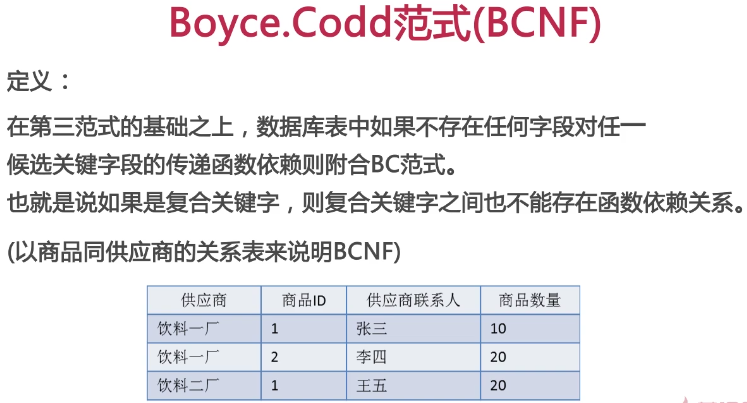
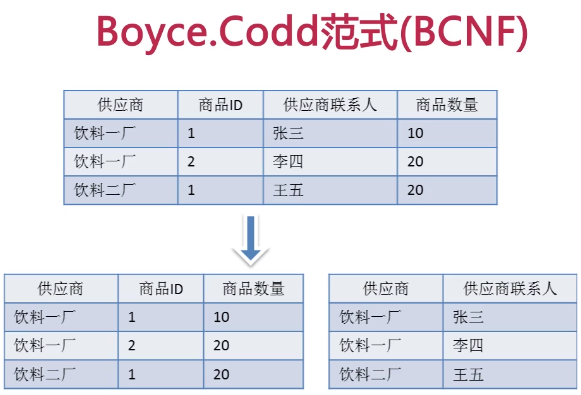
BC范式
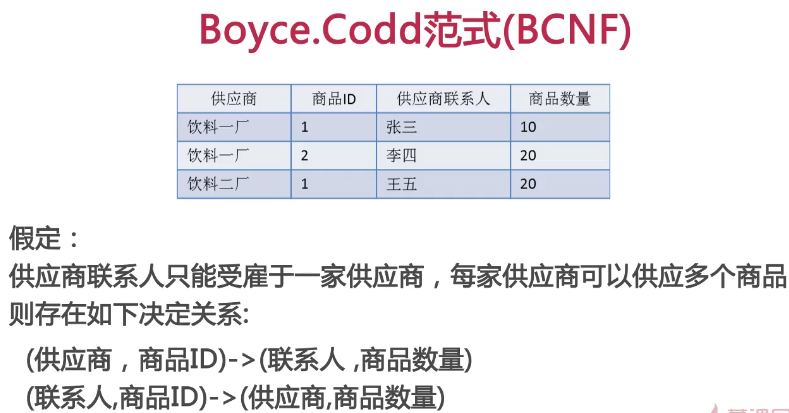
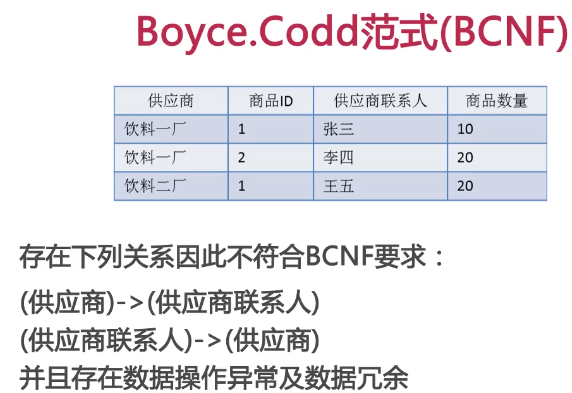
拆分如下
第三章-物理设计
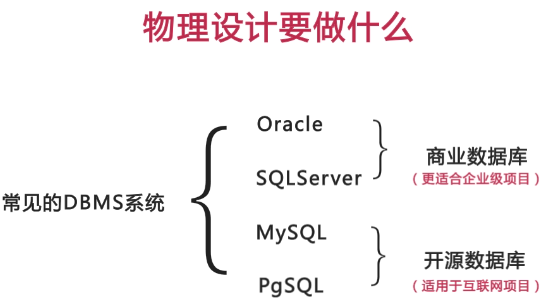
物理设计要做什么?
- 选择合适的数据库管理系统(应用特点和成本)
- 定义数据库、表以及字段的命名规范(不同数据库对命名的规范是有差异的)
- 根据所选的DBMS系统选择合适的字段类型
- 反范式化设计(为了效率的提升而做的,可能是数据冗余)
如何选择数据库系统
考虑功能上的因素
操作系统上的因素
编程语言
应用场景
MySQL常用的存储引擎

- MyISAM :5.5之前的版本,不支持事务,但是存储的效率相对来说比较高,高并发的写可能会导致锁堵塞,所以,读写操作频繁不要使用
- MRG_MYISAM:基于MyISAM将多个结构相同的MyISAM表合并成一个表,
- Innodb:5.5之后,主要的存储引擎。
- Archive:需要的容量相对小,
- Ndb cluster:MySQL集群下使用
表及字段的命令规则
为了方便,打眼一看就知道是什么,而不用去查询文档字典手册。浪费时间和精力

错误的

正确的

数据库字段类型选择原则




具体字段类型的选取

只是存储,很少用来查询,就使用int类型吧,因为不用转换了(比如生日很少使用,订单的时间类型经常使用,就可以使用datetime)
粒度可以根据需要来选择,比如可能只需要年,只需要年月

使用触发器后,如果业务变更会变的复杂和麻烦,影响业务逻辑
反范式化设计

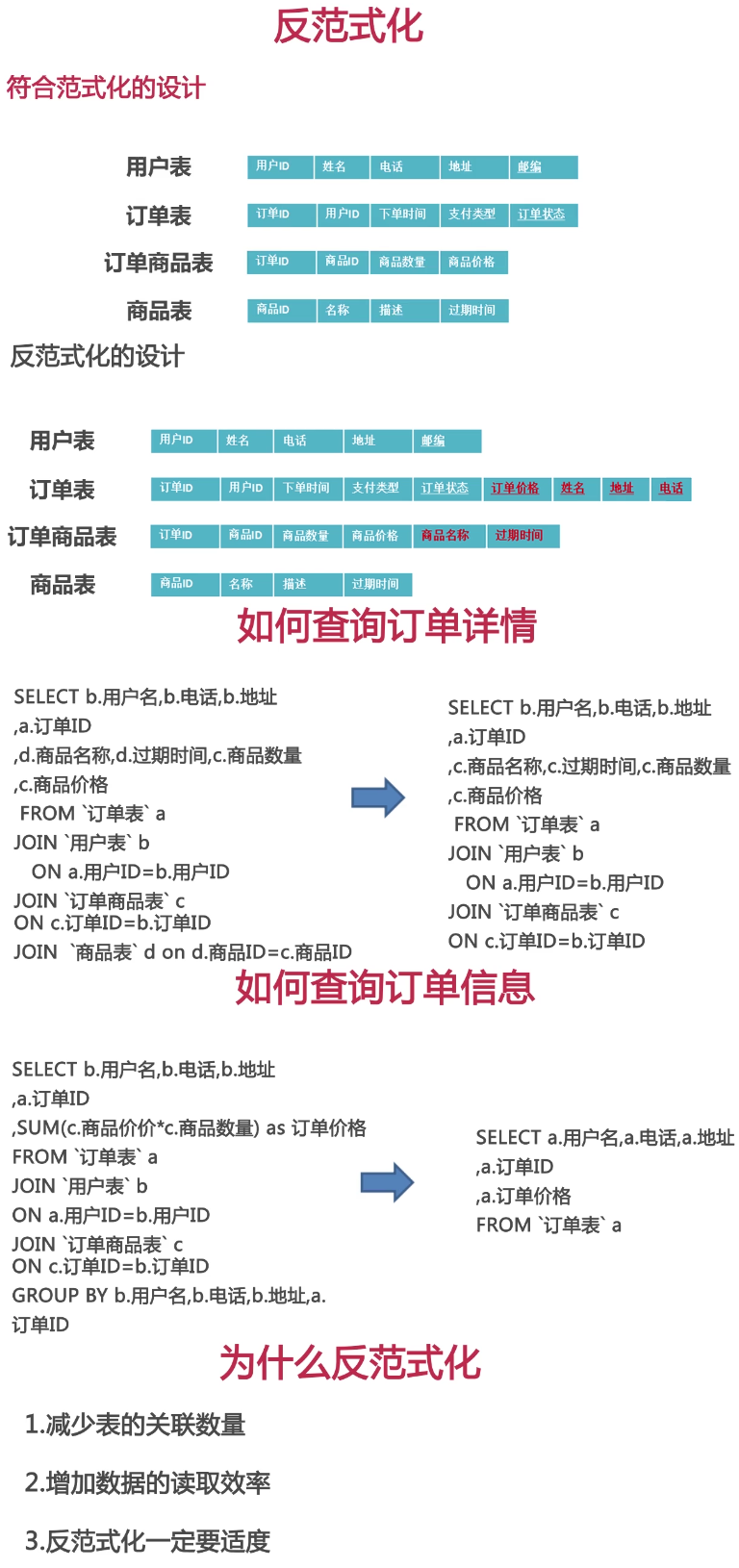
我们的数据库在使用中读写比例大概在3:1。读是远远高于写的。虽然在写的时候增加了冗余,但是在读的时候我们大大的提高了效率
第四章-维护优化

1、要记录清楚数据库的每一个列是什么意思
2、索引可能会应为数据量的增大和业务的改变而变得不适用
3、导致查询缓慢等问题
如何维护数据字典

如何维护索引

表结构的维护

使用自定义函数导致列中的索引失效
数据库中适合的操作

不要使用全文索引,可以使用搜素引擎工具
数据库表的垂直拆分和水平拆分
