前言#
由于elasticsearch依赖java环境,所以,我们首先要安装java jdk。
这里我们使es和kibana的版本保持一致,环境如下:
- centos7.3
- java1.8
- elasticsearch6.7.0
- kibana6.7.0
- ik6.7.0
另外,要检查一下防火墙是否关闭:
firewall-cmd --state # 检查防火墙是否关闭
systemctl stop firewalld.service # 停止firewall
systemctl disable firewalld.service # 禁止开机启动
一、java for linux#
在Linux平台,我们直接使用yum命令下载java jdk即可。
[root@cs home]# yum install java-1.8.0-openjdk -y

默认的,java jdk被安装到了/usr/lib/jvm/目录:
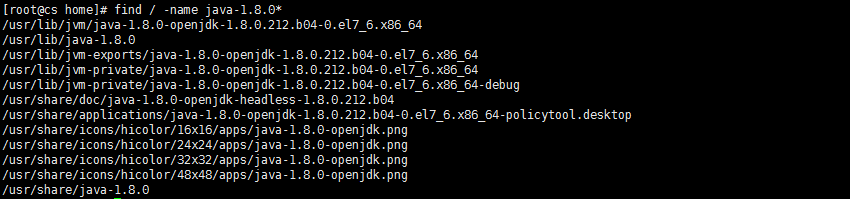
下载并安装完毕,我们使用如下命令测试java环境是否配置完毕:
[root@cs home]# java -version

OK,java环境配置完毕。至于配置javac,见鬼去吧!
二、elasticsearch for linux#
在elastic官网的elasticsearch下载页面,复制tar包链接:
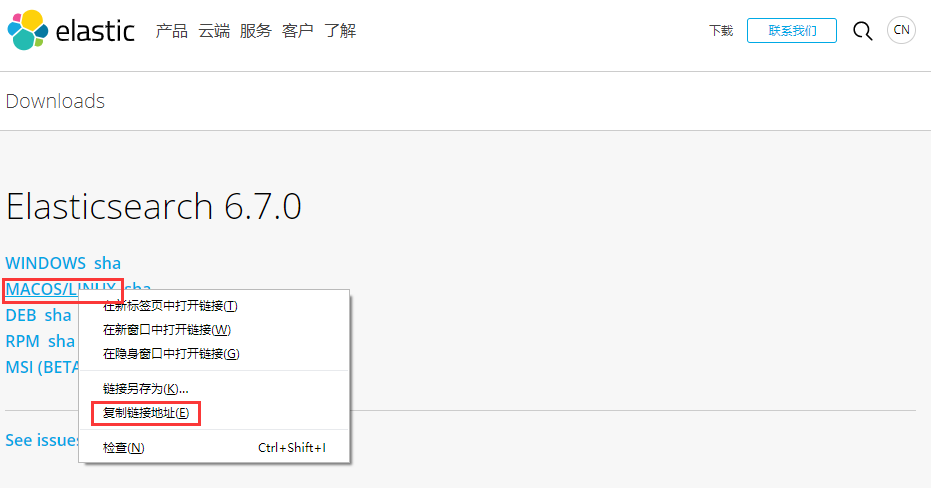
然后,使用wget命令下载即可:
[root@cs home]# wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-6.7.0.tar.gz

下载完毕后,我们解压tar包:
[root@cs home]# tar -zxvf elasticsearch-6.7.0.tar.gz
当解压完毕,我们对elasticsearch做一些配置,elasticsearch.yml 配置文件里面有很多常用的配置,我们根据业务需求可以来这里修改它们:
[root@cs home]# vim /home/elasticsearch-6.7.0/config/elasticsearch.yml
暂时我们只需要对host做一些修改,方便后面我们通过浏览器访问它:
network.host: 10.0.0.200
host对应你的主机ip地址。
由于elasticsearch的默认jvm堆大小是1G(在es的6.7.0和6.5.4版本中,该值都是默认1G),为了启动不报错Cannot allocate memory,所以还需要修改一处配置,就是调整堆值的大小,并且这个值应该根据你的系统物理内存大小而定,比如我本机的物力内存是1G,所以我将这个值调整为512M:
[root@r home]# vim /home/elasticsearch-6.7.0/config/jvm.options
-Xms512m # 原值为-Xms1g
-Xmx512m # 原值为-Xmx1g
没完!我们还需要修改两处配置(非常重要的两个步骤,配置不好就导致后面的报错):
[root@cs home]# vim /etc/sysctl.conf
编辑追加一行:
vm.max_map_count=262144
完事执行如下命令,使配置生效:
[root@cs home]# sysctl -p
vm.max_map_count = 262144
而我碰到命令执行失败的问题:
[root@cs home]# sysctl -p
sysctl: cannot stat /proc/sys/vm/max_map_conut: 没有那个文件或目录
怎么办呢?我们使用另一个办法:
[root@cs ~]# cat /proc/sys/vm/max_map_count # 之前,我们查看参数并没有修改
65530
[root@cs ~]# echo 262144 > /proc/sys/vm/max_map_count # 通过这样手动修改参数
[root@cs ~]# cat /proc/sys/vm/max_map_count # 就好了
262144
简要说下sysctl -p命令,sysctl命令用于运行时配置内核参数,这些参数位于/proc/sys目录下。sysctl配置与显示在/proc/sys目录中的内核参数.可以用sysctl来设置或重新设置联网功能,如IP转发、IP碎片去除以及源路由检查等。用户只需要编辑/etc/sysctl.conf文件,即可手工或自动执行由sysctl控制的功能。而 参数-p的意思是从指定的文件加载系统参数,如不指定即从/etc/sysctl.conf中加载。
再来修改另一处配置:
[root@cs home]# vim /etc/security/limits.conf
追加如下内容,Python为登录服务器的用户名:
* soft nofile 65536
* soft nofile 65536
* hard nofile 65536
* soft nproc 5000
* hard nproc 5000
当修改完后,我们可以使用reboot重新启动使之生效。
现在,我们去启动es:
[root@cs home]# ./elasticsearch-6.7.0/bin/elasticsearch # 启动其bin目录中的elasticsearch即可
但发现了一个问题导致启动失败,原因是elasticsearch不能以root用户启动。

我们这里手动创建一个普通用户:
[root@cs home]# adduser zhangkai
[root@cs home]# passwd zhangkai
更改用户 zhangkai 的密码 。
新的 密码:
重新输入新的 密码:
passwd:所有的身份验证令牌已经成功更新。
注意,输入密码是不会提示的!
然后,我们(此时还是root用户)为这个普通用户给elasticsearch目录权限:
[root@cs home]# chown -R zhangkai /home/elasticsearch-6.7.0
完事后,我们以普通的用户身份去启动elasticsearch:
[root@cs home]# su zhangkai
[zhangkai@cs home]$ ./elasticsearch-6.7.0/bin/elasticsearch
当然,要停止的话,Ctrl + C比较简单粗暴!
现在,让我们打开浏览器访问吧:
http://10.0.0.200:9200/
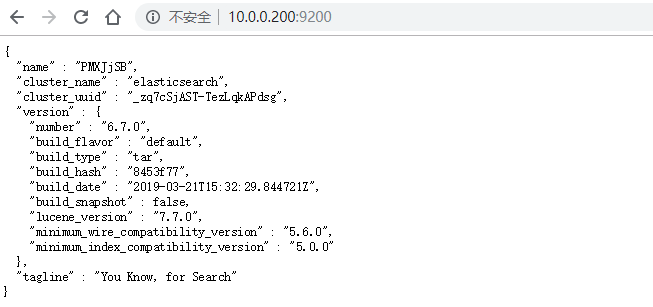
不希望你遇到的报错问题:
- 报错,
Cannot allocate memory,无法分配内存:
[root@r myelk]# ./elasticsearch-6.7.0/bin/elasticsearch
OpenJDK 64-Bit Server VM warning: If the number of processors is expected to increase from one, then you should configure the number of parallel GC threads appropriately using -XX:ParallelGCThreads=N
OpenJDK 64-Bit Server VM warning: INFO: os::commit_memory(0x00000000c5330000, 986513408, 0) failed; error='Cannot allocate memory' (errno=12)
#
# There is insufficient memory for the Java Runtime Environment to continue.
# Native memory allocation (mmap) failed to map 986513408 bytes for committing reserved memory.
# An error report file with more information is saved as:
# logs/hs_err_pid2834.log
这是elasticsearch默认的jvm堆大小,如果你的Linux系统的内存较小,我们可以调整这个值,我们去elasticsearch安装目录下的elasticsearchconfjvm.options文件修改这个值。
[root@r home]# vim /home/elasticsearch-6.7.0/config/jvm.options
-Xms512m # 原值为-Xms1g
-Xmx512m # 原值为-Xmx1g

在es的6.7.0和6.5.4版本中,该值都是默认1G,而我的系统才1G,所以报错了,我们把它降低一些,而最大和最小值应该是一致的,并且根据物力内存设置一个合理的值,我这里修改为512m。

- 报错,虚拟内存太小:
There is insufficient memory for the Java Runtime Environment to continue.
由于我使用的是虚拟机,所以分配的内存太小了,手动调大一些就好了。
- 报错,最大虚拟内存太少了:
max virtual memory areas vm.max_map_count [65530] is too low, increase to at least [262144]
这里需要修改etc/sysctl.conf文件设置,前文已经提到了。
- 报错,每个进程打开的文件数量太少:
max file descriptors [4096] for elasticsearch process is too low, increase to at least [65535]
4096是之前设置的太少了。这里需要修改/etc/security/limits.conf文件。前文已经提到了。
牢记,这几个报错,在修改完文件后,需要重新启动。
除此之外,我们还可以通过rpm包的方式安装,当然,具体就不多表了。
# yum install -y java-openjdk
yum install java-1.8.0-openjdk -y
wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-7.0.0-x86_64.rpm
yum install elasticsearch-7.0.0-x86_64.rpm
systemctl start elasticsearch
systemctl stop elasticsearch
至此,elasticsearch在Linux环境配置基本完事。
三、kibana for linux#
在安装kibana之前,请确保java环境和elasticsearch都已配置并启动成功。
在elastic官网的kibana下载页面,复制tar包链接:

然后,使用wget命令下载即可:
[root@cs home]# wget https://artifacts.elastic.co/downloads/kibana/kibana-6.7.0-linux-x86_64.tar.gz

下载完毕后,我们修改其中的配置文件:
[root@cs home]# vim /home/kibana-6.7.0-linux-x86_64/config/kibana.yml
这里我们暂时添加,不动原文件注释的内容:
elasticsearch.url: "http://10.0.0.200:9200"
server.host: "10.0.0.200"
完事,让我们启动(此时你的elasticsearch应该是启动状态,并且监听http://10.0.0.200:9200)吧:
[root@cs home]# ./kibana-6.7.0-linux-x86_64/bin/kibana
停止的话,Ctrl + C比较省事!
当我们在茫茫log行发现某一行:
log [07:03:59.832] [info][listening] Server running at http://10.0.0.200:5601
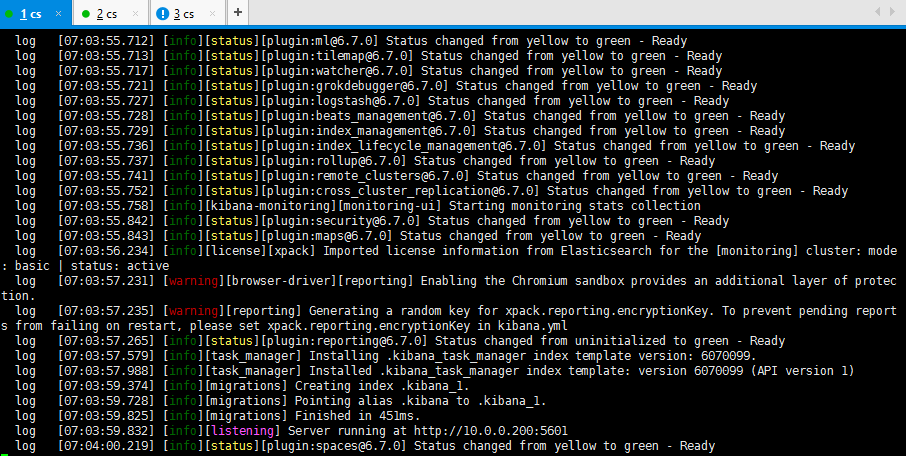
那就表示启动成功了,我们在浏览器地址栏输入http://10.0.0.200:5601。
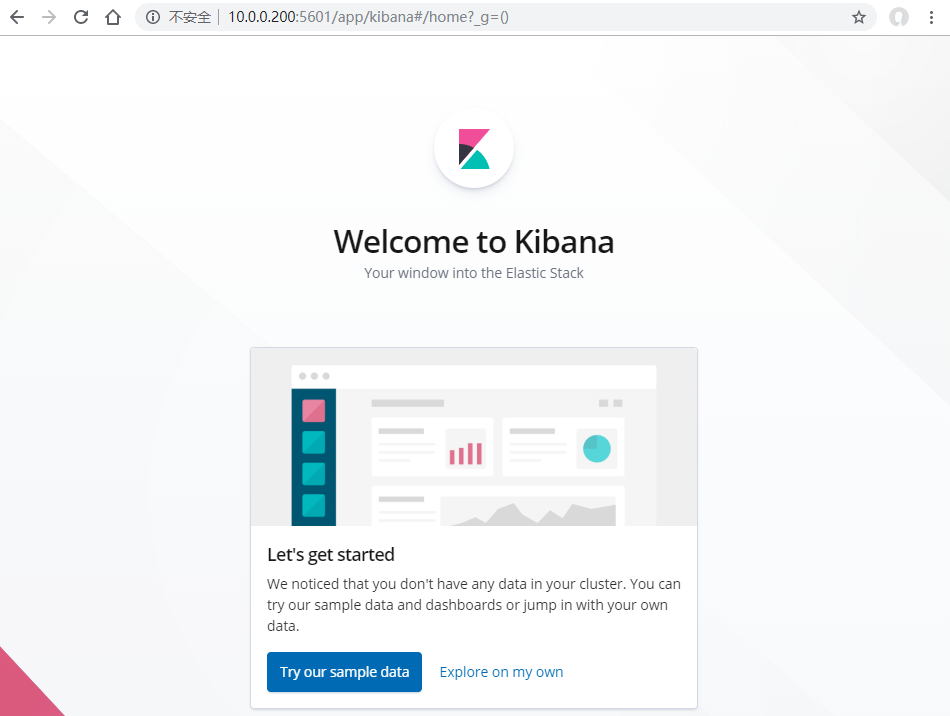
OK,kibana也配置完事。
四、ik for linux#
首先我们应该停掉elasticsearch实例,当然,此时如果你的kibana也在运行的话,就会一直报错,这不要管它,可以把它也停掉。
在Github上找到与elasticsearch对应的版本(版本必须一致),选择tar包右键获取链接:
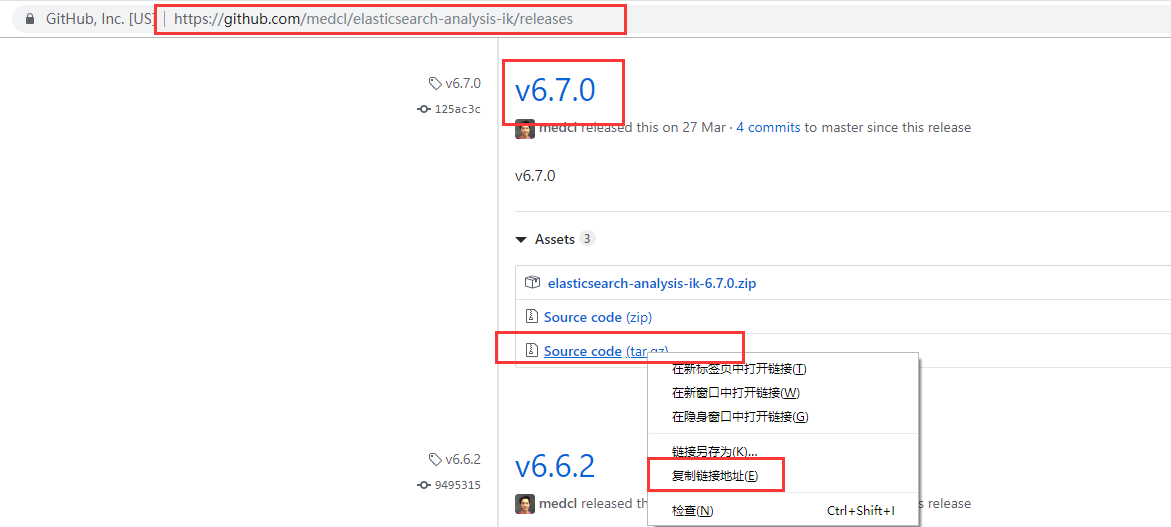
但是,此时如果继续往下走的话,最后会导致elasticsearch启动失败,因为这个源文件需要编译......所以,为了方便,我直接选择复制elasticsearch-analysis-ik-6.7.0.zip的链接了。
然后使用wget命令下载即可,为了简单我们使用cd命令将当前目录切换到/home/elasticsearch-6.7.0/plugins/。
[root@cs home]# cd /home/elasticsearch-6.7.0/plugins/
[root@cs plugins]# wget https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v6.7.0/elasticsearch-analysis-ik-6.7.0.zip
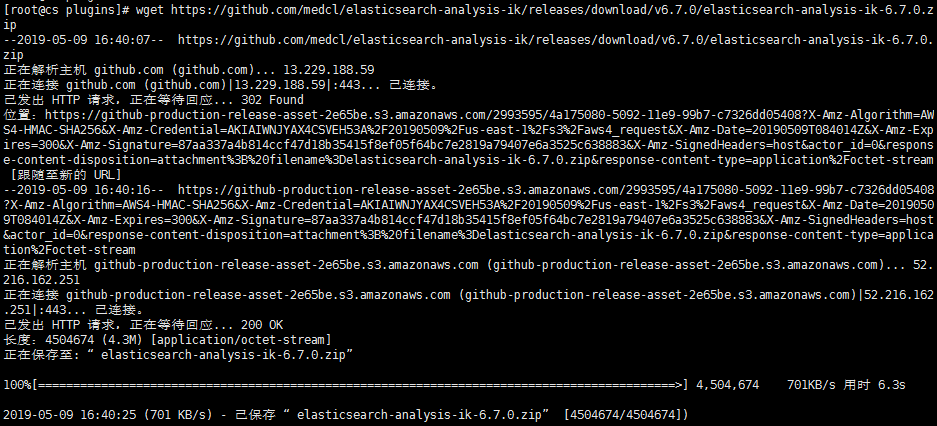
首先我们在plugins目录下创建一个新的ik目录,用来保存解压文件,然后再解压缩,最后将压缩包删除就完事了:
[root@cs plugins]# mkdir ik
[root@cs plugins]# unzip -o -d /home/elasticsearch-6.7.0/plugins/ik elasticsearch-analysis-ik-6.7.0.zip
[root@cs plugins]# rm -rf elasticsearch-analysis-ik-6.7.0.zip && ls
ik
大致说一下unzip -o -p /解压目标路径 解压文件命令,这个命令就是说将elasticsearch-analysis-ik-6.7.0.zip 文件解压到/home/elasticsearch-6.7.0/plugins/ik目录。-o的意思是不提示的情况下覆盖文件,-d指明将文件解压缩到指定目录下。
注意,如果unzip命令不好使,就手动下载或升级一下:
yum install -y unzip zip
然后启动elasticsearch实例。你会在启动日志中找到一行:

就说明该插件已经生效,但是,除非指定使用该插件,否则默认还是使用自带的分析器,如何要使该插件应用于全局,就在elasticsearch.yml文件中修改:
index.analysis.analyzer.default.tokenizer : "ik_max_word"
index.analysis.analyzer.default.type : "ik"
当然,这个是可选项。
最后的配置(可选)#
还有一点可以优化的地方,现在,无论是elasticsearch还是kibana,都是找到绝对路径去启动的,我觉得比较麻烦,所以,我们可以将启动目录添加到PATH中,来个一键启动。
首先,找到PAHT:
[root@cs home]# echo $PATH
/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/root/bin:
现在的返回结果是原有的,我们需要将elasticsearch和kibana的启动目录路径(绝对路径)添加到这个路径中去。
[root@cs home]# vim /etc/profile
在最后添加上拼接的路径,注意各路径间的分隔符是英文冒号:
PATH="/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/root/bin:/home/elasticsearch-6.7.0/bin:/root/bin:/home/kibana-6.7.0-linux-x86_64/bin:"
注意目录结尾不能有/,然后source一下该文件,使之生效:
[root@cs home]# source /etc/profile
此时,我们输入el然后按Tab键就可以提示出来所有el开头的文件,找到那个启动文件,就可以启动它了:
[root@cs home]# elasticsearch
OpenJDK 64-Bit Server VM warning: If the number of processors is expected to increase from one, then you should configure the number of parallel GC threads appropriately using -XX:ParallelGCThreads=N
如果要想后台执行,就加个&符号即可:
[root@cs home]# elasticsearch &
这样程序就会在后台运行,并且返回了当前程序的进程号,方便我们(kill -9)杀死它!虽然依然会将日志输出到当前终端,但至少不影响我们使用该终端。并且不用担心它什么时候结束,其实当前终端被关闭,进程同样结束。
需要说明的是,我用xshell连接的centos,开了3个终端,所以,有些路径可能不太连贯,但有一点需要注意的是,所有涉及的启动elasticsearch的都在普通用户权限,别的操作可以在root权限下搞。
see also:[linux中如何安装elasticsearch](https://blog.csdn.net/zhangxing52077/article/details/80618159) | [[elasticsearch启动常见错误](https://www.cnblogs.com/zhi-leaf/p/8484337.html)]() | [java – 无法更改elasticsearch的vm.max_map_count]() | [ElasticSearch启动报错,bootstrap checks failed](https://blog.csdn.net/feng12345zi/article/details/80367907) | [elasticsearch安装之各种坑](https://www.cnblogs.com/gudulijia/p/6761231.html) | [Linux下的压缩zip,解压缩unzip命令详解及实例](https://www.cnblogs.com/zdz8207/p/3765604.html) | [github的ik主页](https://github.com/medcl/elasticsearch-analysis-ik) | [medcl/elasticsearch-analysis-ik/releases](https://github.com/medcl/elasticsearch-analysis-ik/releases) | [Linux 安装Elasticsearch和配置ik分词器步骤](https://blog.csdn.net/liboyang71/article/details/78553634)