一、elasticsearch之建议器简介
首先,环境是elasticsearch版本是5.x以上。低版本的没有测试!
目前为止,浏览器都已经具备Suggest as you type功能,即在我们输入搜索的过程中,进行自动的补全或者纠错功能,协助用户输入更精确的关键词,提高搜索阶段的文档匹配程度。例如我们在百度或谷歌浏览器输入搜索关键词时,虽然我们输入的有误,但是浏览器依然能够提示出我们想要的正确结果。

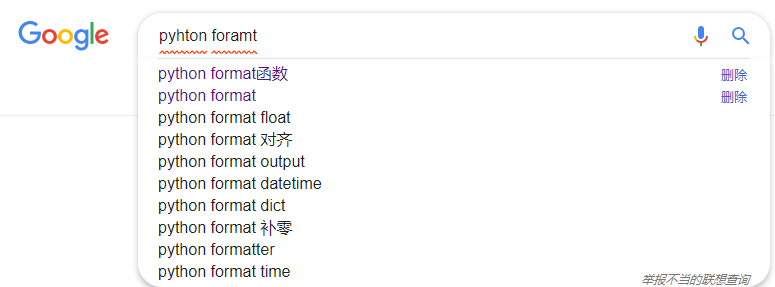
在谷歌浏览器中,再输入刚开始时,会自动补全,而当输入内容达到一定长度时,如果因为单词拼写错误而无法补全时,就开始尝试提示相似的词。
这些功能,我们能通过elasticsearch实现吗?答案就在Suggesters API中。
在elasticsearch中,建议功能通过使用建议器基于提供的文本建议类似的词(官网说部分功能仍在开发中.........)。
注意,目前_suggest已经弃用,我们可以通过_search来做建议器的查询。在5.0版本中,_search经过优化,变得非常的方便。
PUT s1
{
"mappings": {
"doc": {
"properties": {
"title": {
"type": "text",
"analyzer": "standard"
}
}
}
}
}
PUT s1/doc/1
{
"title": "Lucene is cool"
}
PUT s1/doc/2
{
"title":"Elasticsearch builds on top of lucene"
}
GET s1/doc/_search
{
"query": {
"match": {
"title": "Lucene"
}
},
"suggest": {
"my_suggest": {
"text": "Elasticsear lucen",
"term": {
"field": "title"
}
}
}
}
上例是一个包含建议的查询请求,查询query我们已经了然。
让我们注意suggest,每个建议器都有自己名称my-suggestion,es根据text字段返回建议结果。建议类型是term。从field字段生成建议。
{
"took" : 3,
"timed_out" : false,
"_shards" : {
"total" : 5,
"successful" : 5,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : 2,
"max_score" : 0.2876821,
"hits" : [
{
"_index" : "s1",
"_type" : "doc",
"_id" : "2",
"_score" : 0.2876821,
"_source" : {
"title" : "Elasticsearch builds on top of lucene"
}
},
{
"_index" : "s1",
"_type" : "doc",
"_id" : "1",
"_score" : 0.2876821,
"_source" : {
"title" : "Lucene is cool"
}
}
]
},
"suggest" : {
"my_suggest" : [
{
"text" : "elasticsear",
"offset" : 0,
"length" : 11,
"options" : [
{
"text" : "elasticsearch",
"score" : 0.8181818,
"freq" : 1
}
]
},
{
"text" : "lucen",
"offset" : 12,
"length" : 5,
"options" : [
{
"text" : "lucene",
"score" : 0.8,
"freq" : 2
}
]
}
]
}
}
正如结果所示。对于输入的每个词条的建议结果,es都会放在options中,如果没有建议结果,options将会为空。
如果我们仅需要建议而不需要查询功能,我们可以忽略query而直接使用suggest对象返回建议:
GET s1/doc/_search
{
"suggest": {
"my_sugget": {
"text": "Elasticsear lucen",
"term": {
"field": "title"
}
}
}
}
可以根据需要指定几组建议器,每组建议器都有自己的名称。如下例的my_suggest1和my_suggest2。
GET s1/doc/_search
{
"suggest": {
"my_sugget1": {
"text": "Elasticsear",
"term": {
"field": "title"
}
},
"my_suggest2": {
"text": "lucen",
"term": {
"field": "title"
}
}
}
}
在多个建议器中,如果输入的text字段值一致,可以单独写出来,以适用于my_suggest1和my_suggest2两个建议器:
GET s1/doc/_search
{
"suggest": {
"text": "Elasticsear lucen",
"my_sugget1": {
"term": {
"field": "title"
}
},
"my_suggest2": {
"term": {
"field": "title"
}
}
}
}
根据需求不同elasticsearch设计了4种suggester,分别是:
- 词条建议器(term suggester):对于给定文本的每个词条,该键议器从索引中抽取要建议的关键词,这对于短字段(如分类标签)很有效。
- 词组建议器(phrase suggester):我们可以认为它是词条建议器的扩展,为整个文本(而不是单个词条)提供了替代方案,它考虑了各词条彼此临近出现的频率,使得该建议器更适合较长的字段,比如商品的描述。
- 完成建议器(completion suggester):该建议器根据词条的前缀,提供自动完成的功能(智能提示,有点最左前缀查询的意思),为了实现这种实时的建议功能,它得到了优化,工作在内存中。所以,速度要比之前说的
match_phrase_prefix快的多! - 上下文建议器(context suggester):它是完成建议器的扩展,允许我们根据词条或分类亦或是地理位置对结果进行过滤。
see also: [elasticsearch官网:Suggesters](https://www.elastic.co/guide/en/elasticsearch/reference/current/search-suggesters.html) 欢迎斧正,that's all
二、elasticsearch之term suggester
在建议器简介部分,我们已经对term suggest建议器有所了解。
词条建议器接收输入的文本,对其进行分析并且分为词条,然后为每个词条提供一系列的建议。
准备数据:
PUT s2
{
"mappings": {
"doc": {
"properties": {
"title": {
"type": "text",
"analyzer": "standard"
}
}
}
}
}
PUT s2/doc/1
{
"title": "Lucene is cool"
}
PUT s2/doc/2
{
"title": "Elasticsearch builds on top of lucene"
}
PUT s2/doc/3
{
"title": "Elasticsearch rocks"
}
PUT s2/doc/4
{
"title": "Elastic is the company behind ELK stack"
}
PUT s2/doc/5
{
"title": "elk rocks"
}
PUT s2/doc/6
{
"title": "elasticsearch is rock solid"
}
我们创建一个新的索引并且添加了几条文档。现在,我们来查询一下吧。
GET s2/doc/_search
{
"suggest": {
"my_suggest": {
"text": "luenc",
"term": {
"field": "title"
}
}
}
}
返回的了建议结果:
{
"took" : 3,
"timed_out" : false,
"_shards" : {
"total" : 5,
"successful" : 5,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : 0,
"max_score" : 0.0,
"hits" : [ ]
},
"suggest" : {
"my_suggest" : [
{
"text" : "luenc",
"offset" : 0,
"length" : 5,
"options" : [
{
"text" : "lucene",
"score" : 0.6,
"freq" : 2
}
]
}
]
}
}
上例中,在options字段中,建议结果是lucene。我们来看看,在建议器中,都有哪些字段。
- text:建议文本,建议文本是必需的选项,可以通过全局(多个建议器中查询相同的内容)或者按照单个建议器的格式来。
- field:从field字段中获取候选建议的字段。这是一个必需的选项,需要全局设置或根据建议设置。
- analyzer:用于分析建议文本的分析器。默认为建议字段的搜索分析器。
- size:个建议文本标记返回的最大条目。
- sort:定义如何根据建议文本术语对建议进行排序。它有两个可能的值。
- score,先按分数排序,然后按文档频率排序,再按术语本身排序。
- frequency,首先按文档频率排序,然后按相似性分数排序,然后按术语本身排序。也可以理解为按照流行度排序。
- suggest_mode:控制建议的模式,有3个模式可选择。
- missing,仅为不在索引中的建议文本术语提供建议。这是默认值。
- popular,仅建议在比原始建议文本术语更多的文档中出现的建议。也就是说提供比原有输入词频更高的词条
- always,根据建议文本中的条款建议任何匹配的建议。说白了就是无论如何都会提供建议。
- lowercase_terms:在文本分析之后降低建议文本术语的大小写。
- min_word_length:建议文本术语必须具有的最小长度才能包含在内。默认为4.(旧名称
min_word_len已弃用)。 - shard_size:设置从每个单独分片中检索的最大建议数。在减少阶段,仅根据size选项返回前N个建议。默认为该 size选项。将此值设置为高于该值的值size可能非常有用,以便以性能为代价获得更准确的拼写更正文档频率。由于术语在分片之间被划分,因此拼写校正频率的分片级文档可能不准确。增加这些将使这些文档频率更精确。
- max_inspections:用于乘以的因子, shards_size以便在碎片级别上检查更多候选拼写更正。可以以性能为代价提高准确性。默认为5。
- string_distance:用于比较类似建议术语的字符串距离实现。
- internal,默认值基于damerau_levenshtein,但高度优化用于比较索引中术语的字符串距离。
- damerau_levenshtein,基于Damerau-Levenshtein算法的字符串距离算法。
- levenshtein,基于Levenshtein编辑距离算法的字符串距离算法。
- jaro_winkler,基于Jaro-Winkler算法的字符串距离算法。
- ngram,基于字符n-gram的字符串距离算法。
选择哪些词条被建议
了解了各字段的大致含义,我们来探讨一下,词条建议器是如何运作的。以便理解如何确定哪些建议将成为第一名。
词条建议器使用了Lucene的错拼检查器模块,该模块会根据给定词条的编辑距离(es使用了叫做Levenstein edit distance的算法,其核心思想就是一个词改动多少字符就可以和另外一个词一致),从索引中返回最大编辑距离不超过某个值的那些词条。比如说为了从mik得到mick,需要加入一个字母(也就是说需要至少要改动一次),所以这两个词的编辑距离就是1。我们可以通过配置一系列的选项,来均衡灵活和性能:
- max_edits:最大编辑距离候选建议可以具有以便被视为建议。只能是介于1和2之间的值。任何其他值都会导致抛出错误的请求错误。默认为2。
- prefix_length:必须匹配的最小前缀字符的数量才是候选建议。默认为1.增加此数字可提高拼写检查性能。通常拼写错误不会出现在术语的开头。(旧名
prefix_len已弃用)。 - min_doc_freq:建议应出现的文档数量的最小阈值。可以指定为绝对数字或文档数量的相对百分比。这可以仅通过建议高频项来提高质量。默认为0f且未启用。如果指定的值大于1,则该数字不能是小数。分片级文档频率用于此选项。
- max_term_freq:建议文本令牌可以存在的文档数量的最大阈值,以便包括在内。可以是表示文档频率的相对百分比数(例如0.4)或绝对数。如果指定的值大于1,则不能指定小数。默认为0.01f。这可用于排除高频术语的拼写检查。高频术语通常拼写正确,这也提高了拼写检查的性能。分片级文档频率用于此选项。
小结,term suggester首先将输入文本经过分析器(所以,分析结果由于采用的分析器不同而有所不同)分析,处理为单个词条,然后根据单个词条去提供建议,并不会考虑多个词条之间的关系。然后将每个词条的建议结果(有或没有)封装到options列表中。最后由建议器统一返回。
see also: [Elasticsearch Suggester详解](https://elasticsearch.cn/article/142) | [Elasticsearch官网:Suggesters](https://www.elastic.co/guide/en/elasticsearch/reference/current/search-suggesters.html) | [ElasticSearch suggester](https://blog.csdn.net/zhanglh046/article/details/78536021) | [Elasticsearch官网:suggesters-term](https://www.elastic.co/guide/en/elasticsearch/reference/current/search-suggesters-term.html)
欢迎斧正,that's all
三、elasticsearch之phrase suggester
词组建议器和词条建议器一样,不过它不再为单个词条提供建议,而是为整个文本提供建议。
准备数据:
PUT s4
{
"mappings": {
"doc": {
"properties": {
"title": {
"type": "text",
"analyzer": "standard"
}
}
}
}
}
PUT s4/doc/1
{
"title": "Lucene is cool"
}
PUT s4/doc/2
{
"title": "Elasticsearch builds on top of lucene"
}
PUT s4/doc/3
{
"title": "Elasticsearch rocks"
}
PUT s4/doc/4
{
"title": "Elastic is the company behind ELK stack"
}
PUT s4/doc/5
{
"title": "elk rocks"
}
PUT s4/doc/6
{
"title": "elasticsearch is rock solid"
}
现在我们来看看phrase是如何建议的:
GET s4/doc/_search
{
"suggest": {
"my_s4": {
"text": "lucne and elasticsear rock",
"phrase": {
"field": "title"
}
}
}
}
text是输入带有拼错的文本。而建议类型则换成了phrase。来看查询结果:
{
"took" : 6,
"timed_out" : false,
"_shards" : {
"total" : 5,
"successful" : 5,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : 0,
"max_score" : 0.0,
"hits" : [ ]
},
"suggest" : {
"my_s4" : [
{
"text" : "lucne and elasticsear rock",
"offset" : 0,
"length" : 26,
"options" : [
{
"text" : "lucne and elasticsearch rocks",
"score" : 0.12709484
},
{
"text" : "lucne and elasticsearch rock",
"score" : 0.10422645
},
{
"text" : "lucne and elasticsear rocks",
"score" : 0.10036137
}
]
}
]
}
}
可以看到options直接返回了相关短语列表。虽然lucene建议的并不好。但elasticserch和rock很不错。除此之外,我们还可以使用高亮来向用户展示哪些原有的词条被纠正了。
GET s4/doc/_search
{
"suggest": {
"my_s4": {
"text": "lucne and elasticsear rock",
"phrase": {
"field": "title",
"highlight":{
"pre_tag":"<em>",
"post_tag":"</em>"
}
}
}
}
}
除了默认的,还可以自定义高亮显示:
GET s4/doc/_search
{
"suggest": {
"my_s4": {
"text": "lucne and elasticsear rock",
"phrase": {
"field": "title",
"highlight":{
"pre_tag":"<b id='d1' class='t1' style='color:red;font-size:18px;'>",
"post_tag":"</b>"
}
}
}
}
}
需要注意的是,建议器结果的高亮显示和查询结果高亮显示有些许区别,比如说,这里的自定义标签是pre_tag和post_tag而不是之前如这样的:
GET s4/doc/_search
{
"query": {
"match": {
"title": "rock"
}
},
"highlight": {
"pre_tags": "<b style='color:red'>",
"post_tags": "</b>",
"fields": {
"title": {}
}
}
}
phrase suggester在term suggester的基础上,会考虑多个term之间的关系,比如是否同时出现索引的原文中,临近程度,词频等。
see also:[phrase suggester](https://www.elastic.co/guide/en/elasticsearch/reference/current/search-suggesters-phrase.html) 欢迎斧正,that's all
四、elasticsearch之completion suggester
前言
我们来看一下自动完成的建议器——是一个导航功能,提供自动完成、搜索功能,可以在用户输入时引导用户查看相关结果,从而提高搜索精度。但并不适用于拼接检查或者像term和phrase建议那样的功能。
如果说在2000年左右,自动完成还是很炫酷的功能,那么现在它是必备的了——任何没有自动完成功能的搜索引擎都是很古老的。用户期望一个良好的自动完成来帮助用户实现更快的(特别是移动端)以及更好的(比如输入e,搜索引擎就应该知道用户想要查找的是elasticsearch)搜索。
一个优秀的自动完成将降低搜索引擎的负载,特别是在用户有一些快速搜索可用时,也就是直接跳转到主流的搜索结果而无须执行完整的搜索。
除此之外,一个优秀的自动完成必须是和快速的、相关的:
- 快速是因为它必须在用户不断输入的时候产生建议。
- 相关则是用户并不希望建议一个没有搜索结果或者没有用处的结果。
那我们依靠之前学过的match_phrase_prefix最左前缀查询来完成该功能,但是这样的查询可能不够快,因为理想的情况下,搜索引擎需要在用户输入下一个字符前返回建议结果。
完成建议器和后面的上下文建议器可以帮助用户构建更快的自动完成,它们是基于Lucene的suggest建议模块而构建的,将数据保存在内存中的有限状态转移机中(FST)。FST实际上是一种图。它可以将词条以压缩和易于检索的方式来存储。

上图展示了词条index、search、suggest是如何存储的。当然实际中的实现更加复杂,比如它允许我们添加权重。
FST(Finite StateTransducers),通常中文译作有限状态传感器,FST目前在语音识别和自然语言搜索、处理等方向被广泛应用。
FST的功能更类似于字典,Lucene4.0在查找Term时使用了FST算法,用来快速定位Term的位置。FST的数据结构可以理解成(key:value)的形式。
在同义词过滤器(SynonymFilter)的实现中甚至可以用HashMap代替,不过相比较于HashMap,它的优点是:
-
以O(1)的时间复杂度找到key对应的value。
-
以字节的方式来存储所有的Term,重复利用Term Index的前缀和后缀,使Term - Index小到可以放进内存,减少存储空间,不过相对的也会占用更多的cpu资源。
-
FST还可以用来快速确定term是否在系统中。
完成建议器:completion suggester
为了告诉elasticsearch我们准备将建议存储在自动完成的FST中,需要在映射中定义一个字段并将其type类型设置为completion:
PUT s5
{
"mappings":{
"doc":{
"properties": {
"title": {
"type": "completion",
"analyzer": "standard"
}
}
}
}
}
PUT s5/doc/1
{
"title":"Lucene is cool"
}
PUT s5/doc/2
{
"title":"Elasticsearch builds on top of lucene"
}
PUT s5/doc/3
{
"title":"Elasticsearch rocks"
}
PUT s5/doc/4
{
"title":"Elastic is the company behind ELK stack"
}
PUT s5/doc/5
{
"title":"the elk stack rocks"
}
PUT s5/doc/6
{
"title":"elasticsearch is rock solid"
}
GET s5/doc/_search
{
"suggest": {
"my_s5": {
"text": "elas",
"completion": {
"field": "title"
}
}
}
}
建议结果不展示了!
上例的特殊映射中,支持以下参数:
- analyzer,要使用的索引分析器,默认为simple。
- search_analyzer,要使用的搜索分析器,默认值为analyzer。
- preserve_separators,保留分隔符,默认为true。 如果您禁用,您可以找到以Foo Fighters开头的字段,如果您建议使用foof。
- preserve_position_increments,启用位置增量,默认为true。如果禁用并使用停用词分析器The Beatles,如果您建议,可以从一个字段开始b。注意:您还可以通过索引两个输入来实现此目的,Beatles并且 The Beatles,如果您能够丰富数据,则无需更改简单的分析器。
- max_input_length,限制单个输入的长度,默认为50UTF-16代码点。此限制仅在索引时使用,以减少每个输入字符串的字符总数,以防止大量输入膨胀基础数据结构。大多数用例不受默认值的影响,因为前缀完成很少超过前缀长于少数几个字符。
除此之外,该建议映射还可以定义在已存在索引字段的多字段:
PUT s6
{
"mappings": {
"doc": {
"properties": {
"name": {
"type": "text",
"fields": {
"suggest": {
"type": "completion"
}
}
}
}
}
}
}
PUT s6/doc/1
{
"name":"KFC"
}
PUT s6/doc/2
{
"name":"kfc"
}
GET s6/doc/_search
{
"suggest": {
"my_s6": {
"text": "K",
"completion": {
"field": "name.suggest"
}
}
}
}
如上示例中,我们需要索引餐厅这样的地点,而且每个地点的name名称字段添加suggest子字段。
上例的查询将肯德基(KFC)和开封菜(kfc)都返回。
在索引阶段提升相关性
在进行普通的索引时,输入的文本在索引和搜索阶段都会被分析,这就是为什么上面的示例会将KFC和kfc都返回了。我们也可以通过analyzer和search_analyzer选项来进一步控制分析过程。如上例我们可以只匹配KFC而不匹配kfc:
PUT s7
{
"mappings": {
"doc": {
"properties": {
"name": {
"type": "text",
"fields": {
"suggest": {
"type": "completion",
"analyzer":"keyword",
"search_analyzer":"keyword"
}
}
}
}
}
}
}
PUT s7/doc/1
{
"name":"KFC"
}
PUT s7/doc/2
{
"name":"kfc"
}
GET s7/doc/_search
{
"suggest": {
"my_s7": {
"text": "K",
"completion": {
"field": "name.suggest"
}
}
}
}
建议结果如下:
{
"took" : 0,
"timed_out" : false,
"_shards" : {
"total" : 5,
"successful" : 5,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : 0,
"max_score" : 0.0,
"hits" : [ ]
},
"suggest" : {
"my_s7" : [
{
"text" : "K",
"offset" : 0,
"length" : 1,
"options" : [
{
"text" : "KFC",
"_index" : "s7",
"_type" : "doc",
"_id" : "1",
"_score" : 1.0,
"_source" : {
"name" : "KFC"
}
}
]
}
]
}
}
上述的建议结果中,只有KFC被返回。更多的细节控制可以搭配不同的分析器来完成。
多数的情况下,我们将在单独的字段中、单独的索引中甚至是单独的集群中保存建议。这对于主搜索引擎的性能提升和扩展建议器都是非常有利的。
除此之外,还可以使用input和可选的weight属性,input是建议查询匹配的预期文本,weight是建议评分方式(也就是权重)。例如:
PUT s8
{
"mappings": {
"doc":{
"properties":{
"title":{
"type": "completion"
}
}
}
}
}
添加数据的几种形式:
PUT s8/doc/1
{
"title":{
"input":"blow",
"weight": 2
}
}
PUT s8/doc/2
{
"title":{
"input":"block",
"weight": 3
}
}
上例分别添加两个建议并设置各自的权重值。
PUT s8/doc/3
{
"title": [
{
"input":"appel",
"weight": 2
},
{
"input":"apple",
"weight": 3
}
]
}
上例以列表的形式添加建议,设置不同的权重。
PUT s8/doc/4
{
"title": ["apple", "appel", "block", "blow"],
"weght": 32
}
上例是为多个建议设置相同的权重。
查询的结果由权重决定:
GET s8/doc/_search
{
"suggest": {
"my_s8": {
"text": "app",
"completion": {
"field": "title"
}
}
}
}
比如,我们在设置建议的时候,将apple建议的权重weight设置的更高,那么在如上例的查询中,apple将会排在建议的首位。
在搜索阶段提升相关性
当在运行建议的请求时,可以决定出现哪些建议,就像其他建议器一样,size参数控制返回多少项建议(默认为5项);还可以通过fuzzy参数设置模糊建议,以对拼写进行容错。当开启模糊建议之后,可以设置下列参数来完成建议:
- fuzziness,可以指定所允许的最大编辑距离。
- min_length,指定什么长度的输入文本可以开启模糊查询。
- prefix_length,假设若干开始的字符是正确的(比如block,如果输入blaw,该字段也认为之前输入的是对的),这样可以通过牺牲灵活性提升性能。
这些参数都是在建议的completion对象的下面:
GET s8/doc/_search
{
"suggest": {
"my_s9": {
"text": "blaw",
"completion": {
"field": "title",
"size": 2,
"fuzzy": {
"fuzziness": 2,
"min_length": 3,
"prefix_length": 2
}
}
}
}
}
结果如下:
{
"took" : 0,
"timed_out" : false,
"_shards" : {
"total" : 5,
"successful" : 5,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : 0,
"max_score" : 0.0,
"hits" : [ ]
},
"suggest" : {
"my_s9" : [
{
"text" : "blow",
"offset" : 0,
"length" : 4,
"options" : [
{
"text" : "block",
"_index" : "s8",
"_type" : "doc",
"_id" : "3",
"_score" : 6.0,
"_source" : {
"title" : {
"input" : "block",
"weight" : 3
}
}
},
{
"text" : "blow",
"_index" : "s8",
"_type" : "doc",
"_id" : "2",
"_score" : 4.0,
"_source" : {
"title" : {
"input" : "blow",
"weight" : 2
}
}
}
]
}
]
}
}
其他
_source
为了减少不必要的响应,我们可以对建议结果做一些过滤,比如加上_source:
GET s8/doc/_search
{
"suggest": {
"completion_suggest": {
"text": "appl",
"completion": {
"field": "title"
}
}
},
"_source": "title"
}
好吧,虽然我们只有一个字段!
size
除了_source,我们还可以指定size参数:
GET s8/doc/_search
{
"suggest": {
"completion_suggest": {
"prefix": "app",
"completion": {
"field": "title",
"size": 1
}
}
},
"_source": "title"
}
size参数指定返回建议数(默认为5),需要注意的是,size must be positive,也就是说size参数必须是积极的——非0非负数!
skip_duplicates
我们的建议可能是来自不同的文档,这其中就会有一些重复建议项,我们可以通过设置skip_duplicates:true来修改此行为,如果为true则会过滤掉结果中的重复建议文档:
GET s8/doc/_search
{
"suggest": {
"completion_suggest": {
"prefix": "app",
"completion": {
"field": "title",
"size": 5,
"skip_duplicates":true
}
}
},
"_source": "title"
}
但需要注意的是,该参数设置为true的话,可能会降低搜索速度,因为需要访问更多的建议结果项,才能过滤出来前N个。
最后,完成建议器还支持正则表达式查询,这意味着我们可以将前缀表示为正则表达式:
GET s5/doc/_search
{
"suggest": {
"completion_suggest": {
"regex": "e[l|e]a",
"completion": {
"field": "title"
}
}
}
}
see also:completion suggester | Weighted Finite-State Transducer Algorithms
An Overview | FST(Finite-State Transducer) 原理
欢迎斧正,that's all
五、elasticsearch之context suggester
前言
虽然完成建议器已经能返回所有和输入文本相匹配的结果,但有些使用案例需要过滤。这就要用到了上下文过滤器,它在完成建议器的基础上加入了过滤功能。
上下文建议器允许用户使用context上下文来进行过滤,上下文可以是分类(词条)或者地理位置,为了开启上下文,同样在映射中指定,然后在文档和建议中提供上下文。
完成建议器考虑索引中的所有文档,但通常我们希望提供某些标准过滤或者提升的建议。例如,我们想要推荐某些歌手过滤的歌曲标题,或者我们希望根据其类型推广歌曲标题。
要实现建议过滤或者提升,我们可以在配置完成字段时添加上下文映射,我们也可以为完成字段定义多个上下文映射,每个上下文映射都有唯一的名称和类型,有两种类型category和geo。上下文映射contexts在字段映射中的参数下配置。
注意:在索引查询启用上下文的完成字段时,必须提供上下文。
如下示例定义了类型,每个类型都有一个完成字段的两个上下文映射:
PUT place
{
"mappings": {
"doc":{
"properties":{
"title":{
"type":"completion",
"contexts":[
{①
"name":"place_type",
"type": "category"
},
{②
"name":"location",
"type":"geo",
"precision": 4
}
]
}
}
}
}
}
PUT place_path_category
{
"mappings": {
"doc":{
"properties":{
"title":{
"type":"completion",
"contexts":[
{③
"name":"place_type",
"type":"category",
"path":"cat"
},
{④
"name":"location",
"type":"geo",
"precision": 4,
"path":"loc"
}
]
},
"loc":{
"type":"geo_point"
}
}
}
}
}
- ①,定义category名为place_type的上下文,其中必须与建议一起发送类别。
- ②,定义一个geo名为location的上下文,其中必须使用建议发送类别。
- ③,定义category名为place_type的上下文,其中必须从cat字段字段中读取类别。
- ④,定义geo名为location的上下文,其中从loc字段中读取类别。
注意:添加上下文映射会增加完成字段的索引大小,完成索引完全是堆驻留的,我们可以使用Indices Stats监视完成字段索引的大小。
类别上下文
在category上下文允许我们将一个或多个类别与索引时间的建议关联,在查询时,建议可以通过其关联的类别进行过滤和提升。
映射的设置与place_type上面的字段类似,如果path已定义,则从文档中的该路径读取类别,否则必须在建议字段中发送它们,如下示例所示:
PUT place/doc/1
{
"title":{
"input":["timmy's", "starbucks", "dunkin donuts"],
"contexts":{
"place_type":["cafe", "food"] ①
}
}
}
- ①,这些建议将与咖啡馆和食品类别相关联。
如果映射有path, 那么以下索引请求就可以添加类别:
PUT place_path_category/doc/1
{
"title":["timmy's", "sstarbucks", "dunkin donuts"],
"cat":["cafe", "food"] ①
}
- ①,这些建议将与咖啡馆和食品类别相关联。
注意:如果上下文映射引用另一个字段并且类别被明确索引,则使用两组类别对建议进行索引。
类别查询
建议可以按一个或多个类别进行过滤,以下按多个类别过滤建议:
POST place/_search
{
"suggest":{
"place_suggestion":{
"prefix":"tim",
"completion":{
"field":"title",
"size": 10,
"contexts":{
"place_type":["cafe", "restaurants"]
}
}
}
}
}
注意,如果在查询上设置了多个类别或者类别上下文,则将它们合并为分离。这意味着如果建议包含至少一个提供的上下文值,则建议匹配。
某些类别的建议可能会比其他类别高,以下按类别过滤建议,并额外提升与某些类别相关的建议:
POST place/_search
{
"suggest": {
"place_suggestion": {
"prefix": "tim",
"completion": {
"field": "title",
"size": 10,
"contexts":{
"place_type":[ ①
{
"context":"cafe"
},
{
"context":"restaurants", "boost":2
}
]
}
}
}
}
}
- ①,上下文查询过滤建议与类别咖啡馆和餐馆相关联,并且通过因子增强与餐馆相关联的建议
除了接受类别值之外,上下文查询还可以由多个类别上下文子句组成,category上下文支持以下参数:
- context,要过滤/提升的类别的值,这是强制性的。
- boost,应该提高建议分数的因素,通过将boost乘以建议权重来计算分数,默认为1。
- prefix,是否应该将类别实为前缀,例如,如果设置为true,则可以通过指定类型的类别前缀来过滤type1,type2等类别,默认为false。
注意:如果建议条目与多个上下文匹配,则最终分数被计算为由任何匹配上下文产生的最大分数。
地理位置上下文
一个geo上下文允许我们将一个或多个地理位置或geohash与在索引时间的建议关联,在查询时,如果建议位于地理位置特定的距离内,则可以过滤和提升建议。
在内部,地位置被编码为具有指定精度的地理位置。
地理映射
除了path设置,geo上下文映射还接受以下设置:
- precision,它定义了地理散列的精度要被索引并且可以指定为一个距离值(5km,10km等),或作为原料地理散列精度(1 … 12)。默认为原始geohash精度值6。
注意:索引时间precision设置可以在查询时使用的最大geohash精度。
索引地理上下文
geo上下文可以通过参数显式设置或通过path参数从文档中的地理点地段建立索引,类似于category上下文,将多个地理位置上下文与建立相关联,将为每个地理位置索引建议,以下索引具有两个地理位置上下文的建议:
PUT place/doc/2
{
"title":{
"input":"timmy's",
"contexts":{
"location":[
{
"lat":43.6624803,
"lon":-79.3863353
},
{
"lat":43.6624718,
"lon":-79.3873327
}
]
}
}
}
地理位置查询
建议可以根据它们与一个或多个地理点的接近程度进行过滤和提升,以下过滤建议属于地理位置点的编码geohash所代表的区域内的建议:
POST place/_search
{
"suggest": {
"place_suggestion": {
"prefix": "tim",
"completion": {
"field": "title",
"size": 4,
"contexts":{
"location":{
"lat": 43.662,
"lon": -79.380
}
}
}
}
}
}
注意:当指定查询精度较低的位置时,将考虑属于该区域内的所有建议。如果在查询上设置了多个类别或类别上下文,则将它们合并为分离,这意味着如果建议包含至少一个提供的上下文值,则建议才匹配。
在geohash所代表的区域内的建议也可以比其他建议更高,如下所示:
POST place/_search
{
"suggest": {
"place_suggestion": {
"prefix": "tim",
"completion": {
"field": "title",
"size":10,
"contexts":{
"location":[ ①
{
"lat": 43.6624803,
"lon": -79.3863353,
"precision": 2
},
{
"context":{
"lat": 43.6624803,
"lon":-79.3863353
},
"boost": 2
}
]
}
}
}
}
}
- ①,上下文查询过滤属于geohash(43.662,-79.380)表示的地理位置的建议,精度为2,并提升属于(43.6624803,-79.3863353)geohash表示的建议,默认精度为6,因数为2。
注意:如果建议条目与多个上下文匹配,则最终分数被计算为由任何匹配上下文产生的最大分数。
除了接受上下文值之外,上下文查询还可以由多个上下文子句组成,category上下文子句支持一下参数:
- context,地理点对象或地理哈希字符串,用于过滤提升建议,这是强制性的。
- boost,应该提高建议分数的因素,通过将boost乘以建议权重来计算分数,默认为1。
- precision,geohash对查询地理点进行编码的精度,这可以被指定为一个距离值(5m,10km等),或作为原料地理散列精度(1 … 12)。默认为索引时间精度级别。
- neighbours,接受应该考虑相邻地理位置的精度值数组,精度值可以是距离值(5m, 10km等)或一个原始地理散列精度(1 … 12)。默认为索引时间精度级别生成的临近值。
see also: [Context Suggester](https://www.elastic.co/guide/en/elasticsearch/reference/7.0/suggester-context.html) 欢迎斧正,that's all