该作业要求来自于:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE2/homework/2696
1.列表,元组,字典,集合分别如何增删改查及遍历。
①列表的增删改查及遍历:
#列表list list=["你好世界","C语言","JAVA","Python"]; print("列表:",list); #增加 list.append("JavaScript"); print("添加JavaScript:",list); list.insert(2,"PHP"); print("添加PHP,索引值为2(插入到第三个位置):",list) #删除 list.pop(); print("删除最后一个值:",list); list.pop(3); print("删除第四个值:",list) #修改 list[0]="HTML"; print("修改第一个值:",list); #查找 print("查找第二个值:",list[1]); #遍历 print("遍历list:"); for l in list: print(" ",l);

②元组的增删改查及遍历:
#元组tuple tuple = ("你好世界", "C语言", "JAVA", "Python"); print("元组:",tuple); #查找 print("查找第一个值:",tuple[0]); #遍历 print("遍历tuple:"); for t in tuple: print(" ",t);

③字典的增删改查及遍历:
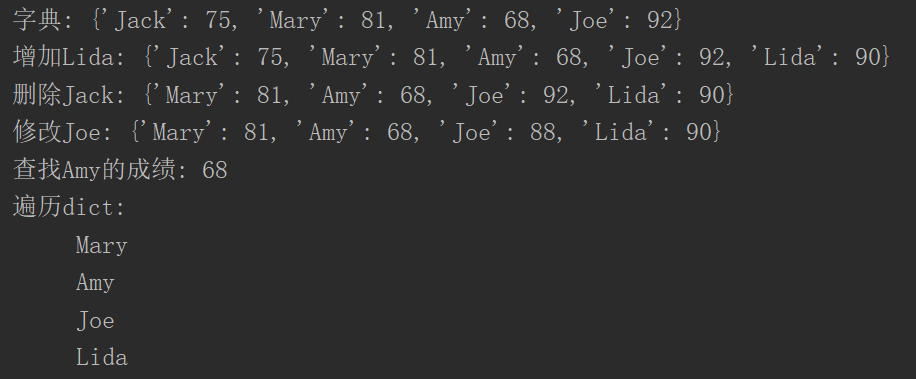
#字典dict dict={"Jack":75,"Mary":81,"Amy":68,"Joe":92}; print("字典:",dict); #增加 dict["Lida"]=90; print("增加Lida:",dict); #删除
if "Jack" in dict:
dict.pop("Jack");
print("删除Jack:",dict); #修改 dict["Joe"]=88; print("修改Joe:",dict); #查找 print("查找Amy的成绩:",dict["Amy"]); #遍历 print("遍历dict:") for d in dict: print(" ",d);
④集合的增删改查及遍历:
#集合set set=set(["你好世界","C语言","JAVA","Python"]); print("集合:",set); #增加 set.add("你好世界"); print("增加‘你好世界’(无法增加,set中午重复值):",set); set.add("C++"); print("增加‘C++’:",set); #删除
if "JAVA" in set:
set.remove("JAVA");
print("删除‘JAVA’:",set); set.pop(); print("删除一个值:",set); #遍历 print("遍历set:") for s in set: print(" ",s);

2.总结列表,元组,字典,集合的联系与区别。参考以下几个方面:
- 括号
- 有序无序
- 可变不可变
- 重复不可重复
- 存储与查找方式

3.词频统计
1.下载一长篇小说,存成utf-8编码的文本文件 file
2.通过文件读取字符串 str
3.对文本进行预处理
4.分解提取单词 list
5.单词计数字典 set , dict
6.按词频排序 list.sort(key=lambda),turple
7.排除语法型词汇,代词、冠词、连词等无语义词
自定义停用词表
或用stops.txt
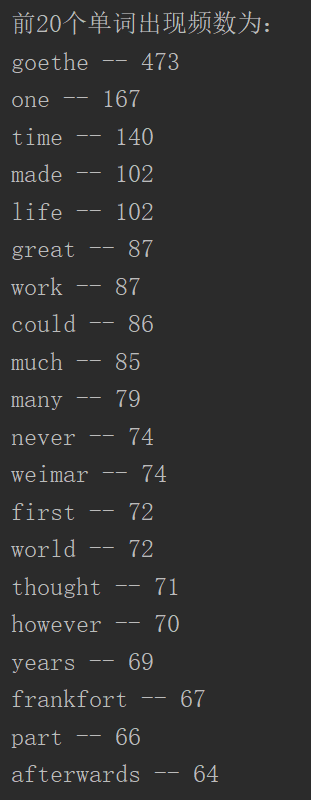
8.输出TOP(20)
9.可视化:词云
排序好的单词列表word保存成csv文件
import pandas as pd
pd.DataFrame(data=word).to_csv('big.csv',encoding='utf-8')
线上工具生成词云:
https://wordart.com/create
import pandas as pd from nltk.corpus import stopwords #获取停用词 stopwords=stopwords.words('english'); #读取文件 f=open("Life of Johann Wolfgang Goethe.txt","r",encoding="utf-8"); str=f.read(); #文件处理 dict={}; str=str.lower();#小写转化 remove=".,?:…—“”"; for i in remove: str = str.replace(i, " ");#以空格替换符号 list=str.split();#空格分割单词单词 for l in list: dict[l]=list.count(l);#获取单词数目 for s in stopwords: if s in dict.keys(): dict.pop(s);#删除停用词 d=sorted(dict.items(),reverse=True,key=lambda d:d[1]); #排序 print("前20个单词出现频数为:") for i in range(20): print(d[i][0],"--",d[i][1]); pd.DataFrame(data=d).to_csv('big.csv',encoding='utf-8');#保存为.csv格式