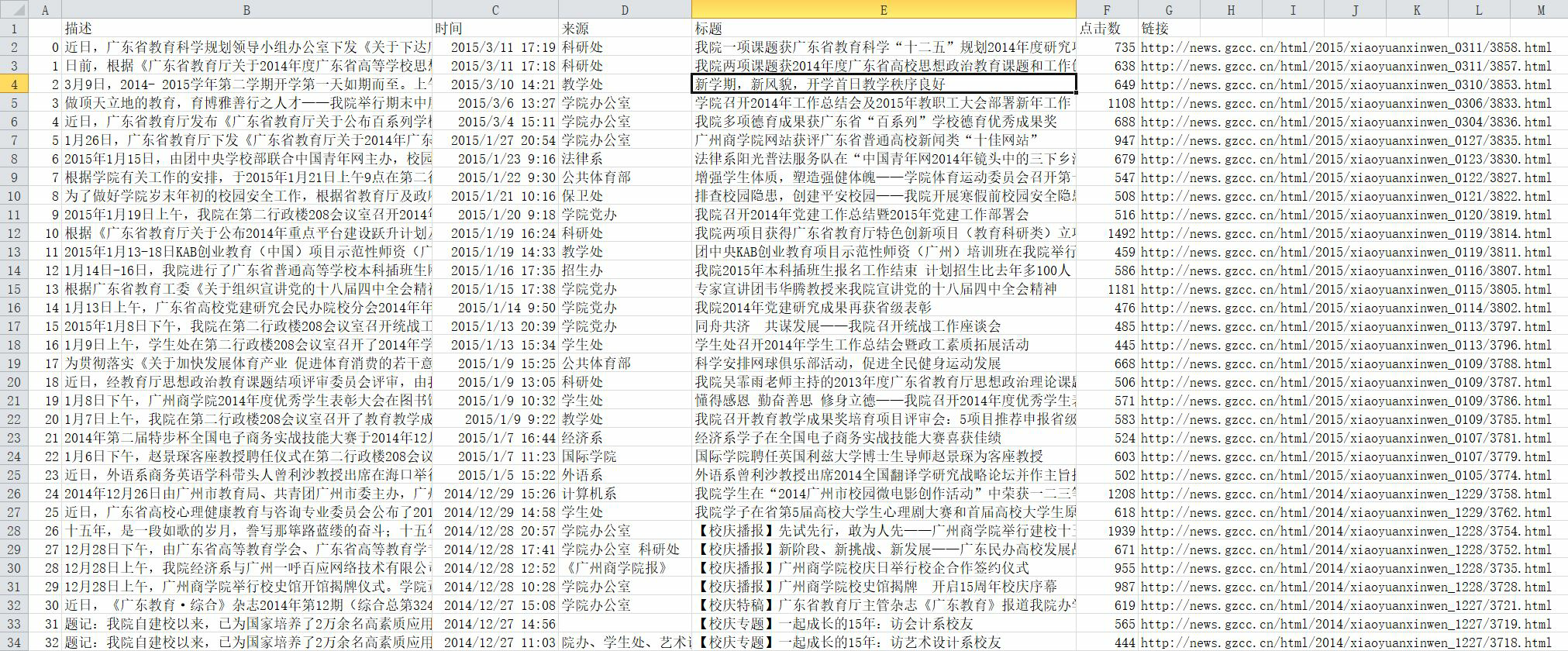
作业要求来自于:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE2/homework/2941
1.从新闻url获取新闻详情: 字典,anews
#获取新闻页面信息
def getNewsInfo(urlList):
newsDict={};
newInfo = getHtml(urlList);
soup = BeautifulSoup(newInfo, "html.parser");
newsTitle=soup.select(".show-title")[0].text;
detail=soup.select(".show-info")[0].text;
dt=changeType(detail);
newsClick=getClick(urlList);
newsDict["标题"] = newsTitle;
newsDict["时间"] = dt;
newsDict["点击数"] = newsClick;
return newsDict;
2.从列表页的url获取新闻url:列表append(字典) alist
#获取新闻列表信息
def getNewsList(mainUrl):
newlistInfo = getHtml(mainUrl);
newsList = [];
soup=BeautifulSoup(newlistInfo,"html.parser");
li=soup.select("li");
for news in li:
if len(news.select(".news-list-title"))>0:
#newsTitle=news.select(".news-list-title")[0].text;
href=news.select("a")[0]["href"];
description = news.select(".news-list-description")[0].text;
source = news.select("span")[1].text;
newsDict = getNewsInfo(href);#获取新闻页面的url。
newsDict["描述"] = description;
newsDict["链接"] = href;
newsDict["来源"] = source;
newsList.append(newsDict);
print(newsList);
return newsList;
3.生成所页列表页的url并获取全部新闻 :列表extend(列表) allnews
*每个同学爬学号尾数开始的10个列表页
#主函数
def main():
infoList=[];
newsDict = {};
for htmlNum in range(100,110):
mainUrl = "http://news.gzcc.cn/html/xiaoyuanxinwen/{}.html".format(htmlNum); #新闻列表
info=getNewsList(mainUrl);
infoList.extend(info); #将爬取的信息放置到列表中
time.sleep(random.random() * 5); #爬取网页时间间隔
setCSV(infoList);
4.设置合理的爬取间隔
import time
import random
time.sleep(random.random()*3)
5.用pandas做简单的数据处理并保存
保存到csv或excel文件
newsdf.to_csv(r'F:duym爬虫gzccnews.csv')
保存到数据库
import sqlite3
with sqlite3.connect('gzccnewsdb.sqlite') as db:
newsdf.to_sql('gzccnewsdb',db)
#用pandas做简单的数据处理并保存
def setCSV(infoList):
newsdf = pd.DataFrame(infoList); #创建二维表格型数据结构。
newsdf.to_csv("news.csv",encoding="utf-8");
print(newsdf);
with sqlite3.connect('gzccnewsdb.sqlite') as db: #保存到数据库
newsdf.to_sql('gzccnewsdb', db)
完整代码:
import requests
from bs4 import BeautifulSoup
from datetime import datetime
import re
import pandas as pd
import sqlite3
import time
import random
#爬取页面
def getHtml(url):
r=requests.get(url);
r.raise_for_status();
r.encoding = r.status_code;
return r.text;
#获取新闻页面信息
def getNewsInfo(urlList):
newsDict={};
newInfo = getHtml(urlList);
soup = BeautifulSoup(newInfo, "html.parser");
newsTitle=soup.select(".show-title")[0].text;
detail=soup.select(".show-info")[0].text;
dt=changeType(detail);
newsClick=getClick(urlList);
newsDict["标题"] = newsTitle;
newsDict["时间"] = dt;
newsDict["点击数"] = newsClick;
return newsDict;
#获取新闻列表信息
def getNewsList(mainUrl):
newlistInfo = getHtml(mainUrl);
newsList = [];
soup=BeautifulSoup(newlistInfo,"html.parser");
li=soup.select("li");
for news in li:
if len(news.select(".news-list-title"))>0:
#newsTitle=news.select(".news-list-title")[0].text;
href=news.select("a")[0]["href"];
description = news.select(".news-list-description")[0].text;
source = news.select("span")[1].text;
newsDict = getNewsInfo(href);#获取新闻页面的url。
newsDict["描述"] = description;
newsDict["链接"] = href;
newsDict["来源"] = source;
newsList.append(newsDict);
print(newsList);
return newsList;
#获取点击数
def getClick(urlList):
id = re.findall('(d{1,5})', urlList)[-1];
clickUrl = 'http://oa.gzcc.cn/api.php?op=count&id={}&modelid=80'.format(id);
resClick = requests.get(clickUrl);
newsClick = int(resClick.text.split('.html')[-1].lstrip("('").rstrip("');"));
return newsClick;
#获取datetime类型
def changeType(detail):
newsDate = detail.split()[0].split(':')[1];
newsTime = detail.split()[1];
dt = newsDate + ' ' + newsTime;
#dt = datetime.strptime(newsDT, '%Y-%m-%d %H:%M:%S');
return dt;
#用pandas做简单的数据处理并保存
def setCSV(infoList):
newsdf = pd.DataFrame(infoList); #创建二维表格型数据结构。
newsdf.to_csv("news.csv",encoding="utf-8");
print(newsdf);
with sqlite3.connect('gzccnewsdb.sqlite') as db: #保存到数据库
newsdf.to_sql('gzccnewsdb', db)
#主函数
def main():
infoList=[];
newsDict = {};
for htmlNum in range(100,110):
mainUrl = "http://news.gzcc.cn/html/xiaoyuanxinwen/{}.html".format(htmlNum); #新闻列表
info=getNewsList(mainUrl);
infoList.extend(info); #将爬取的信息放置到列表中
time.sleep(random.random() * 5); #爬取网页时间间隔
setCSV(infoList);
main();