1.先添加一个线程组,添加--线程--线程组
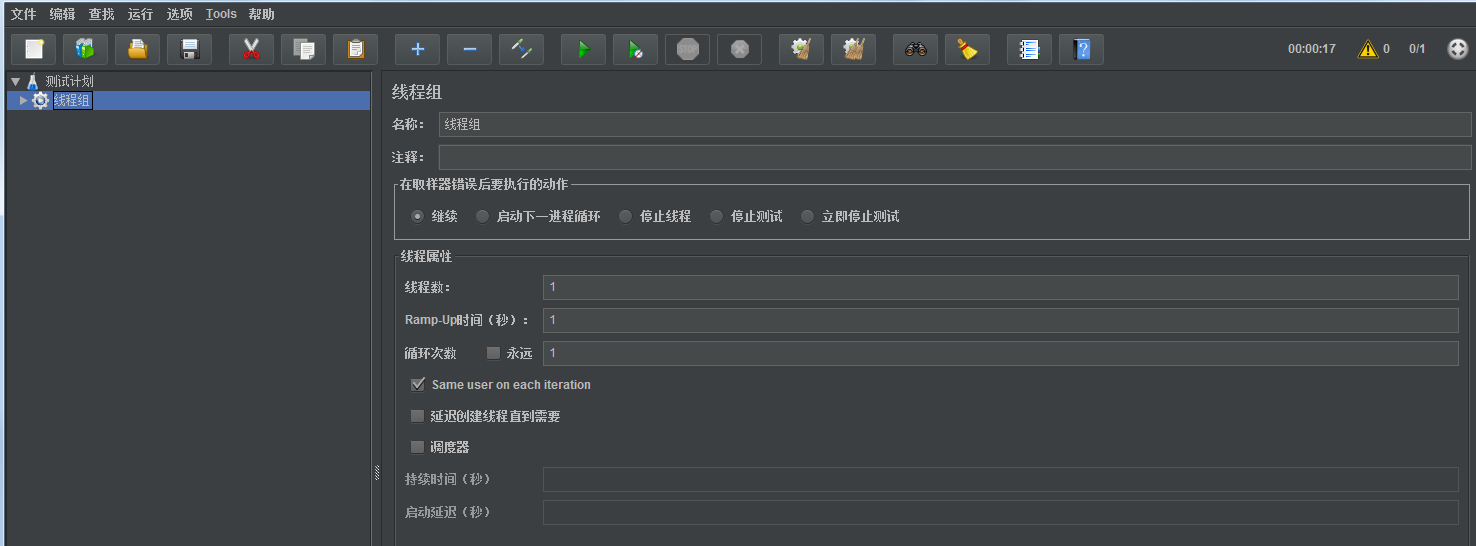
一个线程组可以看做一个虚拟用户组,线程组中的每个线程数都可以理解为一个虚拟用户。
线程数:一个虚拟用户
ramp-up时间,默认为一秒,它指定了启动所有线程所花费的时间
循环次数:表示每个线程执行多少次请求
2.添加--取样器--http请求
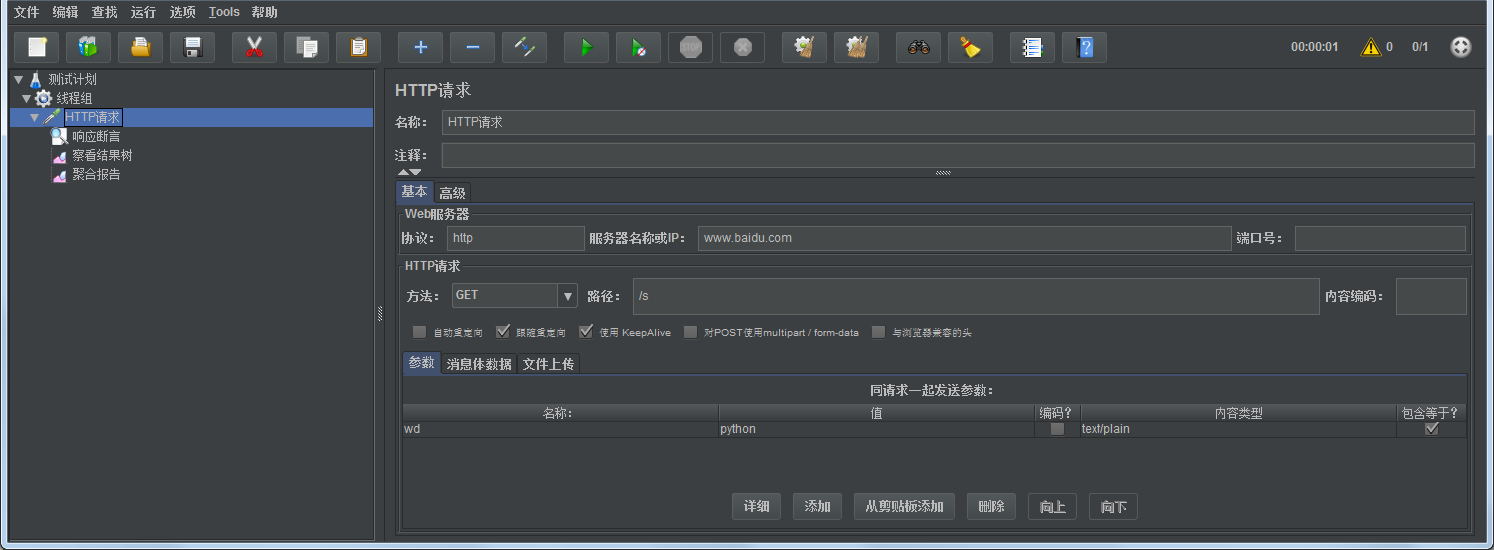
输入访问的服务器域名,路径,这里我们用get方法请求,可以添加一个参数 wd ,值为python
3.添加--断言--响应断言
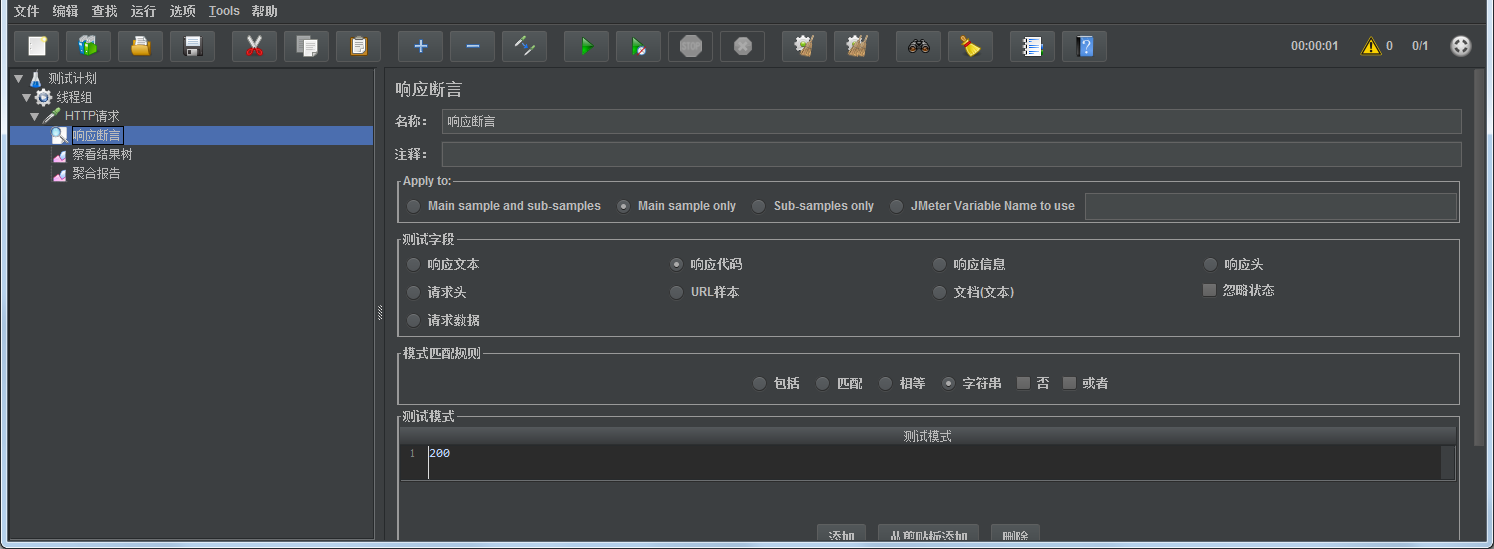
选择了响应代码,测试模式中点击添加,输入200,即响应代码中状态值包括200
4.添加察看结果树和聚合报告,添加--监听器--察看结果树、添加--监听器--聚合报告,然后运行。
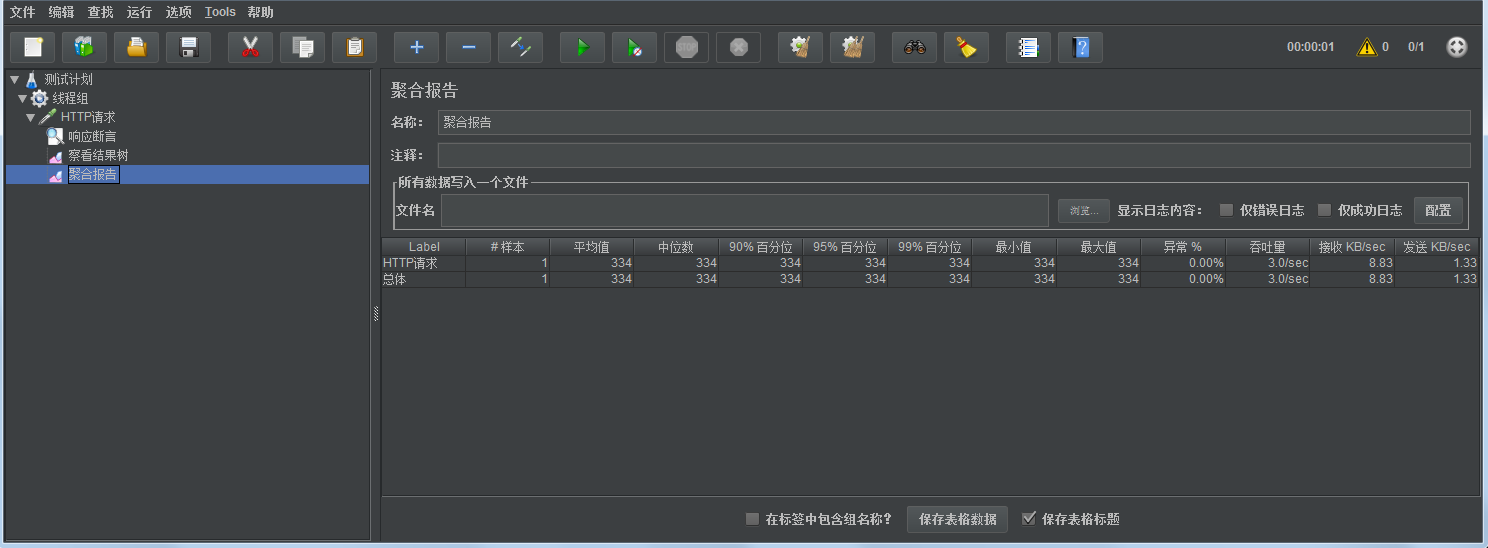
Label:请求的名称
样本: 线程数
平均值: 默认情况下是单个 Request 的平均响应时间,Transaction 为单位显示平均响应时间 ,单位是毫秒
中位数: 50%用户的请求的响应时间
90%百分位:一组数由小到大进行排列,找到他的第90%个的数值
95%百分位::一组数由小到大进行排列,找到他的第95%个的数值
99%百分位::一组数由小到大进行排列,找到他的第99%个的数值
最小值: 最小的响应时间
最大值: 最大的响应时间
异常%: 错误率=错误的请求的数量/请求的总数
吞吐量Throughput: 默认情况下表示每秒完成的请求数(Request per Second),类似 LoadRunner 的 Transaction per Second 数
接收KB/sec: 每秒从服务器端接收到的数据量
发送KB/sec: 每秒从客户端发送到服务器端的数据量