InnoDB两大类索引
-
聚集索引(clustered index)
-
普通索引(secondary index)
InnoDB聚集索引的叶子节点存储行记录,因此, InnoDB必须要有,且只有一个聚集索引
(1)如果表定义了PK,则PK就是聚集索引;
(2)如果表没有定义PK,则第一个not NULL unique列是聚集索引;
(3)否则,InnoDB会创建一个隐藏的row-id作为聚集索引;
画外音:所以PK查询非常快,直接定位行记录。
InnoDB普通索引的叶子节点存储主键值。
画外音:注意,不是存储行记录头指针,MyISAM的索引叶子节点存储记录指针。

两个B+树索引分别如上图:
(1)id为PK,聚集索引,叶子节点存储行记录;
(2)name为KEY,普通索引,叶子节点存储PK值,即id;
既然从普通索引无法直接定位行记录,那普通索引的查询过程是怎么样的呢?
通常情况下,需要扫码两遍索引树。
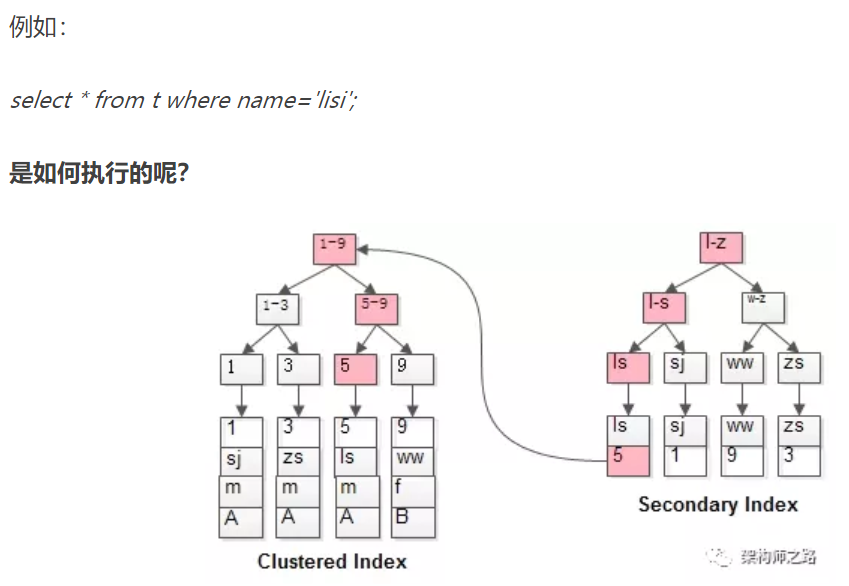
这就是所谓的回表查询,先定位主键值,再定位行记录,它的性能较扫一遍索引树更低。
实战引用:


组合索引结构图:
create table t1 (a int primary key, b int, c int, d int, e varchar(20));
create index idx_t1_bcd on t1(b, c, d);
insert into t1 values (4,3,1,1,’d’);
insert into t1 values (1,1,1,1,’a’);
insert into t1 values (8,8,8,8,’h’):
insert into t1 values (2,2,2,2,’b’);
insert into t1 values (5,2,3,5,’e’);
insert into t1 values (3,3,2,2,’c’);
insert into t1 values (7,4,5,5,’g’);
insert into t1 values (6,6,4,4,’f’);
