问题:
1:通常说Oracle数据库是什么?
2:如何理解Oracle实例?
3:Oracle实例由哪些部分组成,它们之间的作用是什么?
4:如何理解Oracle的物理结构?
5:Oracle的物理结构由哪些部分组成,它们之间的作用是什么?
6:如何理解Oracle的逻辑结构?
7:Oracle的逻辑结构由哪些部分组成,它们之间的作用是什么?
一:Oracle数据库服务器
我们说的Oracle数据库是指Oracle数据库服务器(Oracle sever)是由Oracle实例(Oracle Instance) 和Oracle数据库(Oracle database)组成的。
Oracle实例:用于与数据库进行交互的一片内存区域和后台进程的集合,实例启动的时候,系统先在服务器内存中分配系统全局区(System Global Area SGA),构成Oracle内存结构,然后启动必须的常驻内存的操作系统进程,组成Oracle的进程结构,内存结构和进程结构构成Oracle实例。
oracle数据库:物理文件的集合,包括数据文件,重做日志文件,控制文件,参数文件,密码文件,归档日志文件,备份文件,告警文件,跟踪文件等。其中数据文件,控制文件,重做日志文件和参数文件是必须的。其它文件可选。
一个实例只能对应/操作一个数据库,一个数据库可以由一个或多个实例操作。(比如RAC集群架构)
二:Oracle实例
下图为Oracle实例结构图
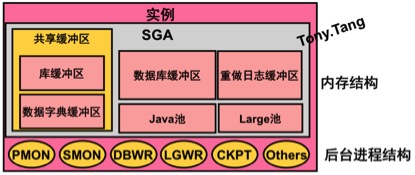
Oracle实例就是用于数据库进行交互的一片内存区域和后台进程的集合,一个单独的数据库可以被多个实例访问,Oracle早期的并行服务器OPS演变到 现在普遍使用的RAC集群架构。
实例启动的时候,先在服务器内存中分配系统全局区(SGA),构成Oracle内存结构,然后启动必须的常驻内存的操作系统进程,组成Oracle的进程结构,内存结构和进程结构一起组成Oracle实例。实例在操作系统中用ORACLE_SID来标识,在Oracle中用参数实例名(Instance Name)来标识,这两个值是相同的,区别就是一个在操作系统中,一个在Oracle中。
1:系统全局区(System Global Area SGA)
系统全局区是系统分配的共享的内存结构,当数据库实例启动时,SGA的内存被自动分配;当数据库实例关闭时,SGA内存被回收;SGA可以包含一个数据库实例的数据和控制信息。当多个用户连接到同一个数据库实例时,在实例的SGA中,数据可以被多个用户共享。SGA是占用内存最大的一个区域,同时也是影响数据库性能的重要因素。
SGA主要包括:
1)、共享缓冲区(Shared Pool)
共享池(Shared Pool)就是我们常说的SQL共享池,它还包括库缓冲区(Library Cache)和数据字典缓冲区(Data Dictionary Cache);共享缓冲区大小由参数SHARED_POOL_SIZE设定。
a)、库缓冲区:存储对数据库进行操作的语句信息,包括执行计划及运行数据库的SQL语句的语法分析树,所有用户在第二次运行相同的SQL语句时,可以利用SQL共享池中可用的语法分析信息来加快执行速度;库缓冲区通过最近最少使用(LRU,LeastRecentlyUsed)算法来管理可用空间,当SQL共享池填满时,将从库缓存区中删掉最近最少使用的执行路径和语法分析树,以便为新的条目腾出空间;如果SQL共享池太小,语句将被连续不断地再装入到库缓存区,从而影响操作性能。
b)、数据字典缓冲区(Database Buffer Cache):数据库对象的信息存储在数据字典表中,这些信息包括用户帐号数据、权限、数据文件名、段名、表结构及表说明等,当数据库需要这些信息(如用户对表是否有读写权限)时,将读取数据字典表且将返回的数据存储在字典缓存区中。数据字典缓冲区使用最近最少使用(LRU,LeastRecentlyUsed)算法来管理,数据字典缓存区的大小由数据库内部管理,如果字典缓存区太小,数据库需要反复查询数据字典表以获取访问数据库所需的信息,这些查询由循环调用(recuesivecall)事件完成。
2)、数据库缓冲区(Database Buffer Cache)
数据库缓冲区由DB_CACHE_SIZE参数设定,Oracle使用最近最少使用(LRU,LeastRecentlyUsed)算法来管理数据库缓冲区可用空间;当存储区需要空闲空间时,最近最少使用块将被移出,新数据块将在存储区代替它的位置,通过这种方法,将最频繁使用的数据保存在存储区中;如果SGA的大小不足以容纳所有最常使用的数据,那么,不同的对象将争用数据库缓存区中的空间;当多个应用程序共享同一个SGA时,很有可能发生这种情况。此时,每个应用的最近使用段都将与其他应用的最近使用段争夺SGA中的空间,这样,数据库缓冲区的数据请求将出现较低的命中率,导致系统性能下降。
3)、重做日志缓冲区(Redo Log Buffer Cache)
Redo log包含所有的数据库变化历史,数据库的所有操作变化,均按照写入重做日志缓冲区先于数据块缓冲区、写入重做日志文件先于写入数据文件;当发生提交动作时,将重做日志缓冲区变化刷到重做日志文件。在被写入联机重做日志文件之前,事务首先被记录在称作重做日志缓冲区(Redo Log Buffer)的SGA中,数据库可以周期地分批向联机重做日志文件中写重做项的内容,从而优化这个操作。重做日志缓冲区的大小(以字节为单位)由LOG_BUFFER参数决定。
4)、大池(Large Pool)
大池属于一个可选内存区,如果数据库使用线程服务器选项或频繁执行备份、恢复操作,只要创建一个大池,就可以更有效地管理这些操作。大池将致力于支持大型SQL命令,利用大池,就可以防止这些大型SQL命令争用SQL共享池,从而减少再装入到库缓存区中的语句数量。大池的大小(以字节为单位)由LARGE_POOL_SIZE参数设置,可以使用LARGE_POOL_MIN_ALLOC参数设置大池的最小分配,可以使用SHARED_POOL_RESERVED_SIZE参数为SQL大型语句保留一部分SQL共享池。
5)、Java池(Java Pool)
Java池为Java命令提供语法分析,Java池的大小(以字节为单位)由JAVA_POOL_SIZE参数设置,缺省值为10MB。
6)、多缓冲池
可以在SGA中创建多个缓冲池,能够用多个缓冲池把大数据集与其他的应用程序分开,以减少数据库缓存区内相同资源争用;对于创建的每一个缓冲池,都要设定LRU锁存器的大小和数量,缓冲区的数量必须至少比LRU锁存器的数量多50倍。创建缓冲池时,需要设定保存区(KeepArea)的大小和再循环区(RecycleArea)的大小,与SQL共享池的保留区一样,保存区保持条目,而再循环区则被频繁地再循环使用。使用BUFFER_POOL_KEEP参数规定来保存区的大小。
2: 后台进程(Background Process)
数据库实例由内存结构和后台进程,应用与数据库的所有操作和交互都由数据库实例中完成,SGA可以理解为交互平台,后台进程可以理解为SGA与数据库交互的桥梁。PMON.SMON.DBWRn.LGWRn.CKPT进程为必须的后台进程,ARCHn.LCKn等为可选的后台进程。