我现在是在阿里一台服务器。百度云一台服务器。阿里为主
编辑阿里的/etc/hosts。
阿里的内网:172.17.91.0 hadoop1
百度的公网:182.61.21.163 hadoop2
编辑百度的/etc/hosts
阿里的公网:39.106.147.52 hadoop1
百度的公网:172.16.0.4 hadoop2
解压hadoop放到一个目录。然后编辑core-sit.xml 在hadoop下的/etc/hadoop中
/usr/local/hadoop/etc/hadoop
在core-site.xml添加如下:
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://172.17.91.0:8020</value>
<!--<description>HDFS的URI,文件系统://namenode标识:端口号</description>-->
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/hadoop/tmp</value>
<description>namenode上本地的hadoop临时文件夹</description>
</property>
</configuration>
然后编辑:hdfs-site.xml
<configuration>
<!--<property>
<name>dfs.name.dir</name>
<value>/usr/local/hadoop/hdfs/name</value>
<description>namenode上存储hdfs名字空间元数据 </description>
</property>
<property>
<name>dfs.data.dir</name>
<value>/usr/local/hadoop/hdfs/data</value>
<description>datanode上数据块的物理存储位置</description>
</property>
-->
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.http-address</name>
<value>172.17.91.0:50070</value>
</property>
</configuration>
然后在/etc/profile 中添加hadoop的路径
export HADOOP_HOME=/usr/local/hadoop export JAVA_HOME=/usr/java/jdk/jdk1.8.0_181 export JRE_HOME=/usr/java/jdk/jdk1.8.0_181/jre export CLASSPATH=.:$JAVA_HOME/lib:$JRE_HOME/lib:$CLASSPATH export PATH=$JAVA_HOME/bin:$JRE_HOME/bin:$JAVA_HOME:$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
然后在hadoop-env.sh中添加 jdk的路径。因为hadoop是用Java写的。要在jdk中运行。
# The java implementation to use. export JAVA_HOME=${JAVA_HOME} #The jsvc implementation to use. Jsvc is required to run secure datanodes export JAVA_HOME=/usr/java/jdk/jdk1.8.0_181
启动:
bin/hdfs namenode -format
sbin/start-dfs.sh .停止的话:sbin/stop-dfs.sh
sbin/start-yarn.sh 停止:sbin/stop-yarn.sh
然后检验:
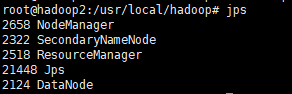
查看版本。

查看一下端口:netstat -nltp
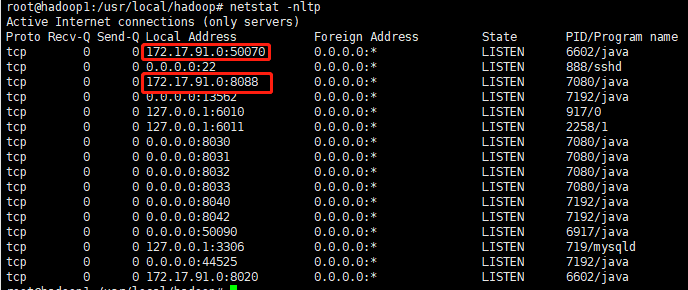
8088:是yarn的http服务端口
50070:是HDFS的http服务的端口
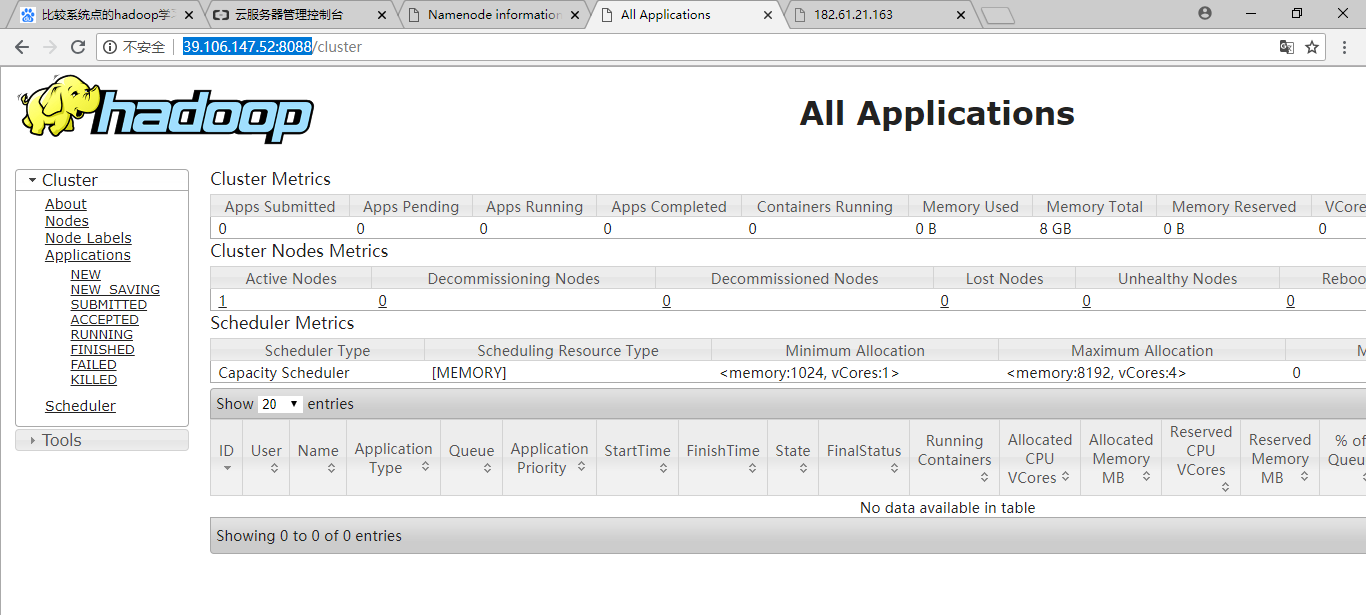
在web访问:是阿里云的公网IP
http://39.106.147.52:50070
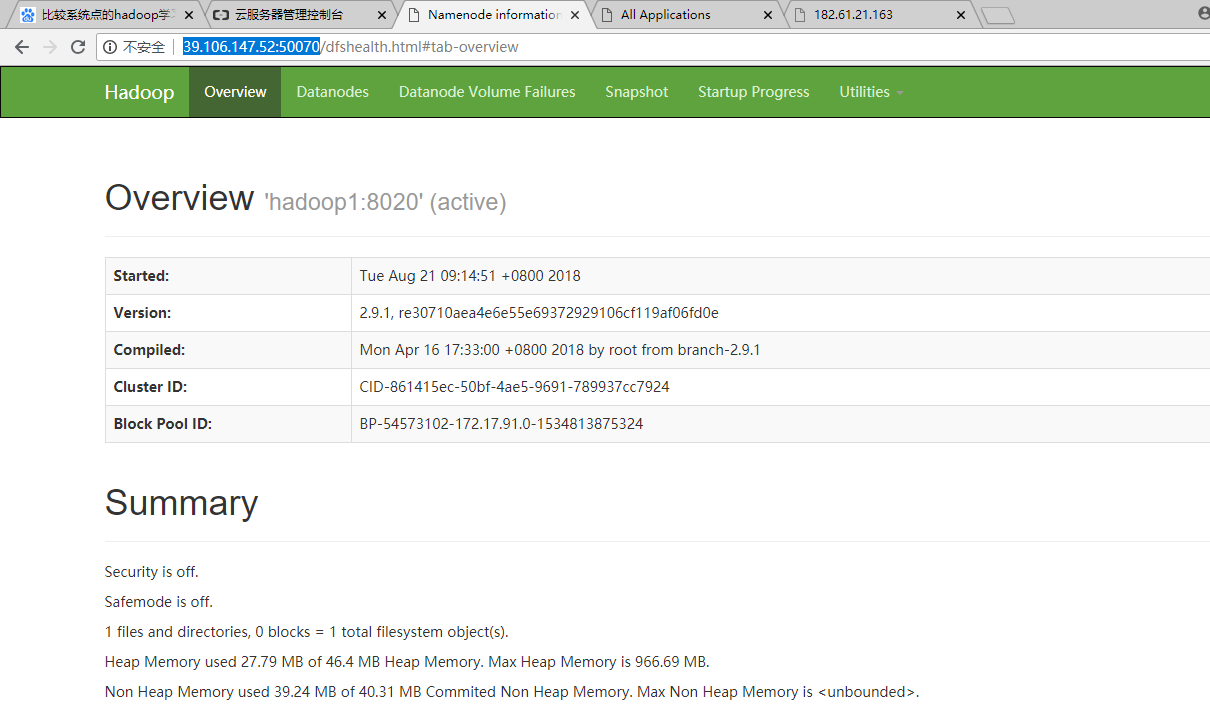
http://39.106.147.52:8088
安装hadoop启动之后总有警告:Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
原因:
Apache提供的hadoop本地库是32位的,而在64位的服务器上就会有问题,因此需要自己编译64位的版本。
1、首先找到对应自己hadoop版本的64位的lib包,可以自己手动去编译,但比较麻烦,也可以去网上找,好多都有已经编译好了的。
2、可以去网站:http://dl.bintray.com/sequenceiq/sequenceiq-bin/ 下载对应的编译版本
3、将准备好的64位的lib包解压到已经安装好的hadoop安装目录的lib/native 和 lib目录下:
tar -xvf hadoop-native-64-2.7.0.tar -C hadoop-2.7.2/lib/native tar -xvf hadoop-native-64-2.7.0.tar -C hadoop-2.7.2/lib4、然后增加环境变量:
5、增加下面的内容:
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib"
6、让环境变量生效
source /etc/profile