Rocket Training: 一种提升轻量网络性能的训练方法
参考博客:
https://www.jianshu.com/p/ec28185510b7
https://blog.csdn.net/cskywit/article/details/78987500
https://mp.weixin.qq.com/s/UkqwPBYgYQuIB9_jGMt2QQ
论文及代码:
paper: https://arxiv.org/abs/1708.04106
code: https://github.com/zhougr1993/Rocket-Launching
针对问题:
工业上很多问题需要快速的响应时间,例如在线广告推荐系统需要在几毫秒内预测数以百计的广告,需要很短的响应时间。
背景:
通常有两种解决方法可以在保证运行效果的前提下提高运行速度,一种是压缩模型减小计算量,如SVD,MobilleNet,ShuffleNet;另外一种是采用teacher-student策略(本文采用此种策略),实际运行的时候使用层数较少参数量较少的light net,此网络在训练的时候会借助一种复杂的teacher network来辅助训练。可以有效减小运行时间,还可以与第一种方法相结合。
Light net 可以在训练阶段从额外的训练好的模型中获得信息,大规模的复杂的网络中的信息可以转化到一个轻量的网络中。
算法思想:
轻量的网络也可以得到和复杂的深层网络相似的效果。
本文提出一种新的网络训练方法,rocket network,同时训练两个网络:light net 和booster net,light net 是用于推断的目标网络,booster具有更深更复杂的网络。在训练过程中,light net 和booster net针对同一问题同时训练。此外,light net还通过优化hint loss不断获取booster学习到的知识,目标函数中也包含了这一点,使两网在训练过程中具有相似的行为。Booster在整个训练过程中指导light的优化。应用阶段,只使用light推理。
本文主要贡献:
1、 提出一种新的训练方法
2、 分析不同的hint loss functions在light和booster之间的信息传递效果;
3、 为了使light更像booster,使用了gradient block来消除hint loss的反向传播对booster的影响,使booster更新参数的时候更多的依赖于gt,有利于网络之后的表现。
实现细节:
网络结构:
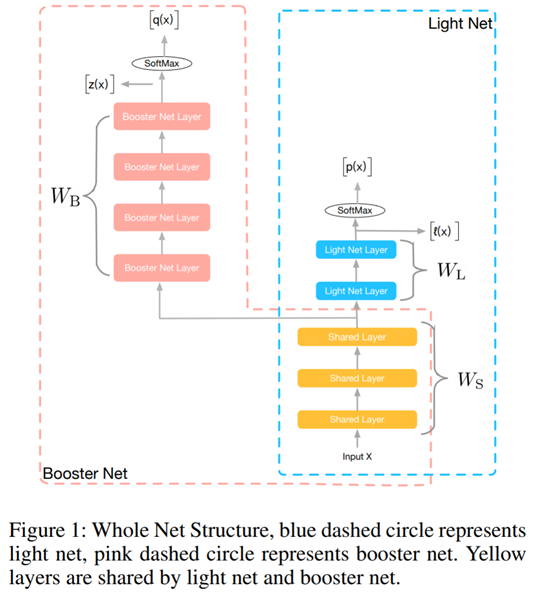
期望在训练的过程中,除了light net的学习结果接近label之外,也与booster学习到的具有更强表现能力的结果相近。使用hint loss来将booster的学习结果转化到light net。
损失函数:
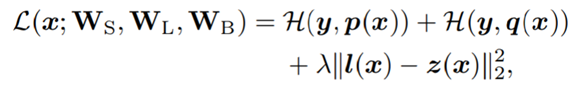
最后一项为hint loss
参数共享:
与通常的teacher-student方法不同的是,本文的light和booster共用了一些较低层,并对他们同时进行训练。有一部分参数共享可以让light更好的近似booster的学习结果。在多任务方式中共用底层参数,可以减少参数量,提高泛化能力,更快收敛。
同时训练:
在大多数teacher-student方式中,teacher网络提前训练好,在指导student网络的过程中,参数是不变的。本文认为从teacher网络中学习的内容不仅仅存在于teacher网络的输出结果上,更存在与整个训练过程中,因此让两个网路一起训练。Light不仅学习复杂网络的输出与gt的区别,同时也近似学习能力更强的复杂网络的到最终结果的过程。这样也比单独训练两个网络的用时短。
Hint loss functions:
最小化hint loss, 使light和booster更接近。考虑了3种不同的hint loss:

MSE的梯度:
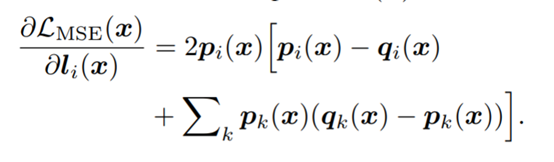
梯度与light net网络的输出成正比,如果li(x)是绝对值非常大的负数,将导致pi(x)接近于0,梯度会消失,学习不到输出的差异。
Lmimic(x)的梯度:

避免了MSE的梯度消失的缺点,实验效果最好。
KD散度的梯度:
引入了温度参数T使得类间概率分布更柔和,温度很高时,梯度如下:

也会产生梯度非常小的情况。
Gradient block:
同时训练两个网络时,light与booster共享部分参数,必不可免的会对booster的训练产生影响,使其不能直接学习任务。因为light的学习性能是比较差的,不可避免的造成booster的学习效果变差。Light学习的信息是从booster传递的,booster性能的降低又会反过来影响light的性能。
为了解决这个问题,在训练阶段,使用gradient block模块来阻止booster受最小化hint loss的影响。

在hint loss的反向传播过程中,固定booster net独有的部分的参数WB,然后使用此刻booster net的分布作为监督light net学习的目标。固定WB的这一操作使得booster不受light net 的影响,可以直接从gt学习,达到它最好的性能。
实验效果:
在CIFAR-10数据集上对wide residual net做了rocket training,WRN有三组block,每个block有两个卷积层,比原来的ResNet的卷积层更宽,有更多的参数,有更强的表达能力。
下图是对WRN应用了rocket training 的网络结构图,红色的是共享层,在较低的组中,黄色的分支是light net,蓝色的是booster部分,在预测阶段会被移除,

