论文题目:FlowNet: Learning Optical Flow with Convolutional Networks
论文连接:https://arxiv.org/abs/1504.06852
光流是对图像中物体运动信息的估计,在视频处理中有着十分重要的应用,传统的光流估计主要是通过一些匹配算法进行的,这篇论文利用深度学习提出一种网络结构来进行光流的估计。
一.光流
光流(optical flow)是空间运动物体在观察成像平面上的像素运动的瞬时速度。一般而言,光流是由于场景中前景目标本身的移动、相机的运动,或者两者的共同运动所产生的。光流法是利用图像序列中像素在时间域上的变化以及相邻帧之间的相关性来找到上一帧跟当前帧之间存在的对应关系,从而计算出相邻帧之间物体的运动信息的一种方法。

在空间中,运动可以用运动场描述,而在一个图像平面上,物体的运动往往是通过图像序列中不同图像灰度分布的不同体现的,从而,空间中的运动场转移到图像上就表示为光流场(optical flow field)。光流场是一个二维矢量场,它反映了图像上每一点灰度的变化趋势,可看成是带有灰度的像素点在图像平面上运动而产生的瞬时速度场。它包含的信息即是各像点的瞬时运动速度矢量信息。研究光流场的目的就是为了从序列图像中近似计算不能直接得到的运动场。
传统的光流估计方法一般基于如下假设:1.像素亮度信息不变。2.小位移。传统的光流估计方法主要有基于梯度的方法,基于匹配的方法,基于能量的方法,基于相位的方法等。该论文的主要思想就是提出一种基于CNN的光流估计方法。
二.网络结构
这篇文章之前也有基于神经网络的光流估计方法,但是那些方法是基于块的,先分块估计,然后聚合到一块,本文的方法是直接得到完整的光流场。这里由于作者是为了验证CNN是否适用于光流估计,所以,作者设计了两种结构,一种结构是单纯的CNN,另一种结构是将两张输入图像分别输入两个CNN支路,然后提取得到两张图的特征之后对特征进行匹配。第一种结构中,把两张图像叠加在一起送入网络,然后让网络自己学习两者之间的关系。第二种结中,两张图像分别被送入两个独立但是完全相同的网络支路,然后对两条支路提取到的特征在高维上进行一个卷积操作。
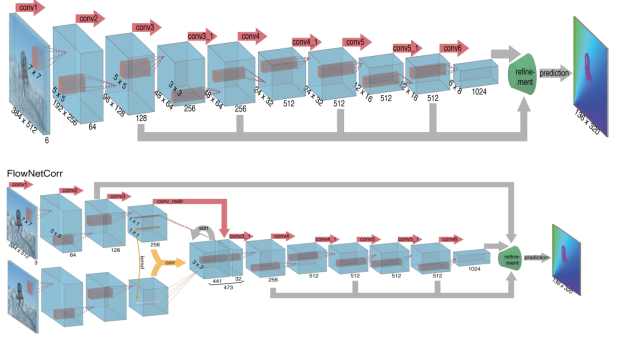
但是应该如何实现两个特征之间的匹配?作者提出加入一个correlation layer,这一层的作用就是寻找两个特征图之间的联系,这里用到的操作类似于一个卷积操作。
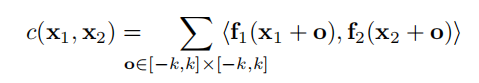
这里的x1和x2指的是两张图中的同一位置,然后这里进行的操作直观来说就是对以x1为中心的(2k+1)x(2k+1)区域与以x2为中心的相应区域进行对位相乘然后求和,然后对于第一张图中的每个x1,将第二张中所有点依次作为x2,然后按这样计算,令K=2k+1,则每一次的运算次数为c*K*K*W*W*H*H,所以为了限制复杂度,文章里选择不对第二张图中的每一个点进行匹配,而是限定一个匹配范围,也就是说对于第一张图中的x1,第二行脏土中与之匹配的x2要限定在以x1为中心的(2d+1)*(2d+1)的范围内,于是之前运算次数中的W2*H2就变成了W*H*D2,这样就降低了运算的复杂度。
这里除了对两个特征进行卷积,还用1*1的卷积对特征做了维度变换,和卷积之后的特征叠加在一起。
三.Refinement
前边提取特征的过程中,为了得到图像的高维特征,用了许多池化操作,池化操作带来的结果就是得到的特征图的分辨率会小于原图片尺寸,但是对于光流来说,我们希望得到每一个像素的光流信息,所以我们要对网络处理后的特征图进行上采样处理,得到和原始图像尺寸一样的光流图。对于上采样,可选的方式很多,文章里选用的是使用反卷积层和特征扩展:

这里的操作比较复杂,首先是对特征图进行反卷积,然后与之前对应的卷积层的结果叠加,然后再叠加一个粗略提取的光流图。这样做的好处是既从粗略的特征图上保留了高级信息,又从更低层的特征图上保留了局部信息,从而使得到的光流信息更加准确。经过四次这种操作后,得到的尺寸是输入图像的四分之一,实验证明,继续通过该操作把图像放大到全分辨率并不会比直接用计算简单的双线性上采样得到的结果好,于是最后通过双线性上采样得到完整尺寸的光流图。文中还提到了可以用变分方法把图像恢复到全分辨率。
四.数据集
现存的数据集主要有Middlebury,KITTI,Sintel。

Middlebury数据集仅包含8个用于训练的图像对,其中使用四种不同技术生成真实的光流。位移非常小,通常低于10像素。KITTI数据集较大(194个训练图像对)并且包括大位移,但仅包含非常特殊的运动类型。通过使用相机和3D激光扫描仪同时记录场景,从现实世界获得ground truth。这假定场景是刚性的,并且运动源于移动的观察者。而且,不能捕获远处物体的运动,例如天空,导致产生稀疏的光流。Sintel 数据集从渲染的人工场景中获取ground truth,特别注意真实的图像属性。提供了两个版本:最终版本包含运动模糊和天气效果,例如雾,而Clean版本不包含这些效果。Sintel是可用的最大数据集(每个版本1,041个训练图像对),并为小型和大型位移都提供密集的ground truth。
上述数据集对于训练该网络来说依旧不够大,于是作者自己设计了一个数据集,并将其命名为flying chairs,作者从Flickr中检索964个分辨率为1024×768图像,分别来自城市类别(321),风景(129)和山峰(514)。将图像切割成4个象限,并使用512×384的裁剪图像作为背景。作为前景,将多个椅子的图像添加到背景中。从原始数据集中删除了非常相似的椅子,产生了809种椅子类型,每种有62个视图。为了生成运动,作者随机抽样背景和椅子的仿射变换参数。椅子的变换与背景变换有关,可以将其解释为相机和物体都在移动。使用变换参数,得出第二个图像、光流场和遮挡区域。

在训练的时候,作者又在此基础上进行了数据增强。
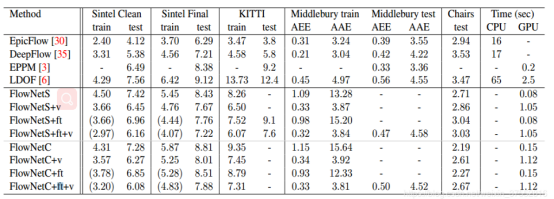
五.实验结果
从实验结果来看,模型的效果举例传统方法还有一定差距,但是确实证明了神经网络可以用来进行光流预测。对于两种不同的结构,作者本来觉得第二种结构效果应该更好,但实际上第二种结构并没有表现出明显的优势,反而更容易过拟合。原因作者在后来的flownet2.0中有提到,是训练顺序和训练策略的问题。