按牛客网讨论区笔经面经的发表时间排序。
阿里内推,蚂蚁金服---java开发工程师第一次电话面试
1.TCP三次握手?
(记住1.过程;2.状态变化;3.几个常见问题)
第一次:客户端给服务器发送syn包x;SYN_SENT
第二次:服务器接收到syn包,返回一个syn包y 和 一个ack包x+1; SYN_RECV
第三次:客户端收到syn+ack包,向服务器发送ack包。ESTABLISHED
为什么三次握手?
防止已失效的连接请求报文段重传。
四次挥手?
把三次握手的第二次分解,先发ack包,再发fin包。
第一次:主动关闭方发送fin包x,关闭数据传送; FIN_WAIT1 CLOSE_WAIT
第二次:被动方发送ack包x+1; FIN_WAIT2
第三次:被动方发送fin包y,关闭数据传送; TIME_WAIT LASH_ACK
第四次:主动方发送ack包y+1;
为什么四次握手?
被动方收到FIN包时,并不会立即关闭socket,所以先回复一个ack包。等到被动方所有数据发送完,再发fin包。
为什么TIME_WAIT/等待2MSL?
MSL是报文最大生存时间;主动方发出最后一个ACK包进入TIME_WAIT状态,目的是防止最后一个ACK包对方没接收到,那么对方在超时后将重发第三次握手的FIN包。 A->ACK->B,等待ACK到达对方时间MSL,等待FIN超时重传MSL,所以如果2MSL时间没有收到FIN,说明对方安全收到FIN。
2.在浏览器访问一个网址的过程?
1.首先浏览器通过DNS解析网址的IP地址,通过IP找到服务器路径;
2.根据IP地址向服务器发送一个HTTP请求;
3.服务器收到请求,返回响应;
4.浏览器对网页解析,渲染显示。
涉及各层协议?
应用层:HTTP、DNS、(DNS解析域名为目的IP,通过IP找到服务器路径,客户端向服务器发起HTTP会话)
传输层:TCP、 (HTTP会话会被分成报文段,添加源、目的端口;TCP协议进行主要工作)
网际层:IP、(ARP)、ICMP、(为数据包选择路由,IP协议进行主要工作)
链路层:PPP、(ARP)(发送IP数据包到达服务器的地址,ARP协议将IP地址转成MAC地址)
3.Linux文件的权限;
4.排序算法有哪些?时间复杂度是?
(还需要记住最好最坏时间复杂度、稳定性)
O(n^2):
选择排序:O(n^2)、O(n^2); 不稳定
冒泡排序:O(n)、O(n^2); 稳定
插入排序:O(n)、O(n^2); 稳定
O(nlogn):
快速排序:O(nlogn)、O(n^2);空间:O(logn) 不稳定
归并排序:O(nlogn)、O(nlogn);空间:O(n) 稳定
堆排序:O(nlogn)、O(nlogn);空间:O(1) 稳定
5.在线编程?
阿里一面17分钟
1.==和equals的区别?
(1.基本类型; 2.基本类型封装;3.String;4.非字符串变量)
equals()是Object类的方法;
(1) 如果是基本类型比较,那么只能用==来比较,用equals会编译错误,因为不是对象。int a = 3;
(2) 对于基本类型的包装类型,比如Boolean、Character、Byte、Shot、Integer、Long、Float、Double等的引用变量,==是比较地址的,而equals是比较内容的。Integer n1 = new Integer(30);
(2.5)对于String a = “a”; Integer b = 1;这种类型的特有对象创建方式,==的时候值是相同的。
(3)对于字符串变量来说,使用“==”和“equals()”方法比较字符串时,其比较方法不同。
“==”比较两个变量本身的值,即两个对象在内存中的首地址。
“equals()”比较字符串中所包含的内容是否相同。
String s1 = "123";
String s2 = "123";
String s4 = new String("123");
String s5 = new String("123");
s1==s2 true; s1.equals(s2) true;
s4==s5 false; s4.equals(s5) true;
s1==s4 false; s1.equals(s4) true;
s1/s2分别指向字符串常量"123"创建的对象,在常量池里只有一个对象,内容为"123";
s4/s5两个引用对象指向的对象内容相同,但是new操作符创建的,内存中分配两块空间给这两个对象,所以内存地址不同。
(4)对于非字符串变量来说,"=="和"equals"方法的作用是相同的都是用来比较其对象在堆内存的首地址,即用来比较两个引用变量是否指向同一个对象。
2.string是不是基本数据类型,
不是,String是类类型,基本类型有八种:
整型4种:byte/short/int/long 字节数:1/2/4/8
字符型1种:char 2
浮点型2种:float/double 4/8
布尔型1种:boolean 1/8
一个字节等于8位,等于256个数,就是-128到127
大写的B表示Bytes=字节;小写的b表示bit=位;1byte=8bit;
自动转换:(小可转大,大转小会失去精度)
byte -> short/char -> int -> long -> float -> double
3.char能不能存放汉字?
能,一个char字符可以存储一个中文汉字。
4.error/exception/runtime exception区别?
Error和Exception都实现了Throwable接口
Error指的是JVM层面的错误,比如内存不足OutOfMemoryError
Exception 指的是代码逻辑的异常,比如下标越界OutOfIndexException
Exception分为可查异常CheckedException和运行时异常RuntimeException:
可查异常是必须处理的异常,要么try catch住,要么往外抛,谁调用,谁处理,比如 FileNotFoundException、IOException、SQLException等。如果不处理,编译器就不让你通过。
运行时异常 又叫做非可查异常,在编译过程中,不要求必须进行显示捕捉。
常见的Runtime Excepiton?
NullPointerException 空指针异常
ArithmeticException 算术异常,比如除数为零
ClassCastException 类型转换异常
ConcurrentModificationException 同步修改异常,遍历一个集合的时候,删除集合的元素,就会抛出该异常
IndexOutOfBoundsException 数组下标越界异常
NegativeArraySizeException 为数组分配的空间是负数异常
为什么分两种异常?
Java之所以会设计运行时异常的原因之一,是因为下标越界,空指针这些运行时异常太过于普遍,如果都需要进行捕捉,代码的可读性就会变得很糟糕。
5.object类的方法?
9种;(简要介绍各方法)
1.对象的复制/获取/String/释放:clone/getClass/toString/finalize;
2.hash:equals/hashCode;
3.多线程:wait/notify/notifyAll
clone:实现对象的浅复制;
getClass:获得运行时类对象;
finalize:用于释放资源;
equals:比较对象是否相等;基本类型不可以用equals,对于String类型“equals”和“==”作用不同;
hashcode:用于hash寻找;
wait:使当前线程等待该对象的锁,当前线程必须是该对象的拥有者,也就是具有该对象的锁;wait()方法一直等待,直到获得锁或者被中断。wait(longtimeout)设定一个超时间隔,如果在规定时间内没有获得锁就返回。
调用该方法后当前线程进入睡眠状态,直到以下事件发生:
(1)其他线程调用了该对象的notify方法。
(2)其他线程调用了该对象的notifyAll方法。
(3)其他线程调用了interrupt中断该线程。
(4)时间间隔到了。
此时该线程就可以被调度了,如果是被中断的话就抛出一个InterruptedException异常。
notify:唤醒在该对象上等待的某个线程
6.jvm垃圾回收?
7.linux查看日志文件的方式?
蚂蚁金服Java面经
1.Java都学了些什么?
答:集合、IO、多线程、框架等等
2.说说多线程吧
答:说了一下多线程的实现,同步,优化
(tips:对于大范围的内容要整理出目录,不然会很乱。)
进程和线程的区别 感觉有点偏题就不写了
多线程的实现?
三种方法:1.继承Thread类;2.实现Runnable接口;3.使用Executor创建线程池;
多线程的同步?
(1)同步方法:synchronized修饰的方法;
(2)同步代码块:同步是一种高开销的操作,因此应该尽量减少同步的内容。通常没有必要同步整个方法,使用synchronized代码块同步关键代码即可。
同步方法和同步代码块的区别是什么?
答:同步方法默认用this或者当前类class对象作为锁; 同步代码块可以选择以什么来加锁,比同步方法要更细颗粒度,我们可以选择只同步会发生同步问题的部分代码而不是整个方法。
(3)使用volatile实现同步:每次线程要访问volatile修饰的变量时都是从内存中读取,而不是从缓存当中读取,因此每个线程访问到的变量值都是一样的。这样就保证了同步。
(4)使用重入锁实现线程同步:ReentrantLock是concurrent包的类;常用方法有lock()和unlock();可以创建公平锁;支持非阻塞的tryLock(可超时);需要手动释放锁。
(5)使用ThreadLocal实现线程同步:每个线程都创建一个变量副本,修改副本不会影响其他线程的副本。ThreadLocal并不能替代同步机制,两者面向的问题领域不同。同步机制是为了同步多个线程对相同资源的并发访问,是为了多个线程之间进行通信的有效方式;而ThreadLocal是隔离多个线程的数据共享,从根本上就不在多个线程之间共享资源(变量)。
多线程的优化?
影响多线程性能的问题:死锁、过多串行化、过多锁竞争等;
预防和处理死锁的方法:
1)尽量不要在释放锁之前竞争其他锁;一般可以通过细化同步方法来实现;
2)顺序索取锁资源;
3)尝试定时锁tryLock();
降低锁竞争方法:
1)缩小锁的范围,减小锁的粒度;
2)使用读写分离锁ReadWriteLock来替换独占锁:来实现读-读并发,读-写串行,写-写串行的特性。这种方式更进一步提高了可并发性,因为有些场景大部分是读操作,因此没必要串行工作。
3.说一下线程池,线程池里面的线程的状态有哪些?
线程池:
(1.创建;2.参数;)
线程池的顶级接口是Executor,是执行线程的工具;真正的线程池接口是ExecutorService。ThreadPoolExecutor是ExecutorService的默认实现。
ThreadPoolExecutor的参数有:
corePoolSize - 池中所保存的线程数,包括空闲线程。
maximumPoolSize-池中允许的最大线程数。
keepAliveTime - 当线程数大于核心时,此为终止前多余的空闲线程等待新任务的最长时间。
unit - keepAliveTime 参数的时间单位。
workQueue - 执行前用于保持任务的队列。此队列仅保持由 execute方法提交的 Runnable任务。
threadFactory - 执行程序创建新线程时使用的工厂。
handler - 由于超出线程范围和队列容量而使执行被阻塞时所使用的处理程序。
线程的状态:(把那张图将熟悉)
包括New、Runnable、Running、Blocked、Dead状态;
1)New:Thread t = new Thread();
2)Runnable:t.start()后进入Runnable状态;位于可运行线程池中,等待被线程调度选中,获得CPU使用权;
3)Running:Runnable状态的线程获得了cpu时间片;
4)Blocked:三种情况;
1.等待阻塞:o.wait(),释放锁;进入等待队列;o.notify()/notifyAll() 进入锁池;
2.同步阻塞:同步锁被别的线程占用;进入锁池;
3.其他阻塞:1)Thread.sleep();2)t2.join();3)等待用户输入(发出I/O请求);不会释放锁;当sleep时间结束,t2线程结束,I/O处理完成后进入Runnable状态;
5)Dead:run()/main()执行结束 或者 异常退出;线程结束生命周期。
4.数据结构学了些什么?
数组、HashMap、栈、队列、链表、树;(HashMap也算?)
(把方向引向自己擅长的部分)
5.Hashmap和Hashtable的区别?
相同点:都实现了Map接口;
不同点-两个方面:null值,同步;
HashMap允许键和值是null,HashTable不允许;
HashTable是同步的,HashMap不是;
6.Hashmap的数据结构,Hash的具体实现(这块答得不好)
(讲HashMap:1.结构+原理;2.其他参数-容量、负荷系数、阈值;)
1)HashMap是有数组+链表组成,Entry数组是HashMap的主体,链表是为了解决Hash冲突;
2)HashMap的Entry数组的元素可以看作是一个个散列桶,每个桶是一个单链表;每个Entry内部类有四个字段:key/value/hash/next;
3)执行put时,根据key的hashcode定位到桶;遍历单链表,利用key.equals()检查key是否存在;如果存在则覆盖;否则新建Entry放在头部;
4)执行get时,根据key的hashcode定位到桶;遍历单链表,利用key.equals()获取对应的Entry,返回它的value;
5)参数:容量capacity(默认16)、负载系数loadFactor(默认0.75)、阈值threshold=容量*负载系数。数组容量capacity必须是2的n次方,当键值对个数>threshold(12)时,扩容:将数组扩容为原来容量的二倍。
几点补充:
1)根据hashcode定位桶步骤:
int hash = hash(key.hashCode()); //计算key.hashcode()的hash值,hash函数由hashmap自己实现 int i = indexFor(hash, table.length);//获取将要存放的数组下标
也就是首先计算key的hashcode(),再对该值map的自定义hash()(将hash值打散,使插入的Entry落在不同的桶上,提高查询效率),再根据得到的hash值调用indexFor()方法;indexFor(h,length)方法:将hash值与entry数组的长度-1按位与;
/** * "按位与"来获取数组下标 */ static int indexFor(int h, int length) { return h & (length - 1); }
2)为什么保持Entry数组大小2的n次方?
当length总是2的n次方时,h& (length-1)运算等价于对length取余,也就是h%length,但是&比%具有更高的效率。
参考:HashMap源码
7.设计模式有了解吗?
答:谈了一下单例模式、工厂模式、代理模式,顺便说了一下Spring的AOP是基于代理模式的,可以实现日志记录等功能。
代理模式
8.数据库事务你了解吗?脏读是什么,幻读是什么?
(说一下事务的四个特性+四个冲突+四个隔离级别)
阿里内推一面,已跪
[阿里] [c++]
1.讲一下Linux下如何将源文件逐步编译成目标文件的过程
2.你简历上写熟悉TCP/IP协议,那你说一下TCP的报头吧。
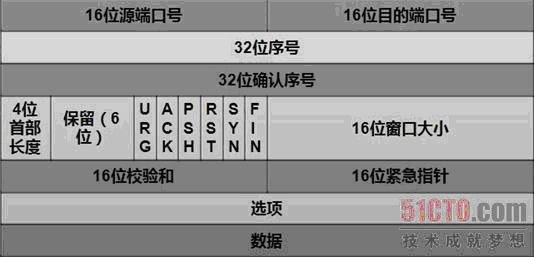
/*TCP头定义,共20个字节*/
typedef struct _TCP_HEADER
{
short m_sSourPort; // 源端口号16bit
short m_sDestPort; // 目的端口号16bit
unsigned int m_uiSequNum; // 序列号32bit
unsigned int m_uiAcknowledgeNum; // 确认号32bit
short m_sHeaderLenAndFlag; // 前4位:TCP头长度;中6位:保留;后6位:标志位
short m_sWindowSize; // 窗口大小16bit
short m_sCheckSum; // 检验和16bit
short m_surgentPointer; // 紧急数据偏移量16bit
}__attribute__((packed))TCP_HEADER, *PTCP_HEADER;
3. 你简历上写的掌握常用的数据结构和排序算法,那你说一个你熟悉的排序算法吧,冒泡就不用说了 。(注:原理+复杂度+手写代码)
排序主要用这六种:
O(n^2)的有:冒泡排序、插入排序、选择排序;
O(nlogn)的有:快排、归并排序、堆排序;
冒泡排序:原理是无序区两两比较,每趟得到一个最大的放在无序区最后;
算法:外循环是趟数[0,n-1), 内循环是无序区个数[0, n-i-1);循环体是比较[j]和[j+1];
插入排序:是把数组分成有序区和无序区两部分,每次从无序区取出一位作为tar值,从后向前遍历有序区,大于tar则后移,最后放到目标位置;
算法:外循环是无序区长度[1,n);定义a[i]为tar值;内循环j指向i,比较a[j-1]与tar,大于则往后顺移a[j-1];最后a[j]赋值;
选择排序:也是分为有序区和无序区,每次从无序区选择一位最小的放到有序区末尾;
算法:外循环是趟数[0,n-1), 内循环是无序区个数[i+1,n);循环体是比较[i]和[j];
快排:每次排序确定一个数的位置,比该数小的移到左边,大的移到右边。一趟快排的算法是:
- 设置两个首尾指针lo、hi;
- 以第一个元素作为key值;
- 从hi向前搜索,如果大于key则hi--,小于key则[lo]=[hi]把[hi]移到前面;
- 从lo向后搜搜,如果小于key则lo++,大于key则[hi]=[lo]把[lo]移到后面;
- 重复3、4步骤,直到lo=hi;返回lo位置。
上述过程就是partition函数;以partition函数返回的位置,对左右两边递归。
算法:(如上)partition(a,lo,hi)函数:定义key,while循环(lo<hi),内部(lo<hi && a[hi]>=key);最后a[lo]赋值,返回lo; sort(a,lo,hi)函数:判断(lo<hi),index,递归;
归并排序:将数组分成若干个小数组,将已有序的数组两两归并得到完全有序数组。每趟归并的算法是:
- 申请空间tmp[],大小是两个已排数组的和,[hi-lo+1];
- 设定两个指针,分别指向两个已排数组的起始位置;
- 比较两个指针元素的值,选择小的元素放到tmp[]里,并移动指针;
- 重复步骤3,直到某一指针到数组尾;
- 将另一序列剩下的所有元素复制到tmp[]里;
- 将tmp[]数组覆盖原num[]数组;
算法:merge(a,lo,mid,hi)方法:tmp[]数组,左右指针+临时指针,比较两数组小的保存,保存剩余数组,赋值数组;mergeSort(a,lo,hi) mid, if()判断:左右递归,merge();注意左右递归一定是左边(lo,mid),右边(mid+1, hi);因为mid偏左,不然会死循环。
堆排序:堆排序包括两个过程,首先是根据元素建堆,时间复杂度O(n),然后将堆的根节点取出(与最后一个节点交换),将前面N-1个节点进行堆调整。直至所有节点都取出。堆调整时间复杂是O(lgn),调用了n-1次,所以堆排序时间复杂度是O(nlgn);
- 建堆:建堆是不断调整堆的过程;从len/2出开始调整(最后一个父节点)。最后一层父节点最多下调1次,倒数第二层最多下调2次,顶点最多下调H=logN次。而最后一层父节点共有2^(H-1)个,倒数第二层公有2^(H-2),顶点只有1(2^0)个,所以总共的时间复杂度为s = 1 * 2^(H-1) + 2 * 2^(H-2) + ... + (H-1) * 2^1 + H * 2^0。将H代入后s= 2N - 2 - log2(N),近似的时间复杂度就是O(N)。
- 调整堆:思想是比较节点i和它的孩子节点left(i),right(i),若i不是最大则调换。
* JDK动态代理只能对实现了接口的类生成代理,而不能针对类
* CGLIB是针对类实现代理,主要是对指定的类生成一个子类,覆盖其中的方法。
数据链路层:将比特组装成帧和点到点的传递(帧Frame) PPP点对点协议、ARP地址解析协议;
传输层:提供端到端的可靠报文传递和错误恢复(段Segment) TCP、UDP
会话层:建立、管理和终止会话(会话协议数据单元SPDU)
表示层:对数据进行翻译、加密和压缩(表示协议数据单元PPDU)
应用层:允许访问OSI环境的手段(应用协议数据单元APDU)FTP、DNS、HTTP
1.ArrayList和LinkedList的区别
三个方面:1.实现;2.查询、增删;3.内存;
2.知道乐观锁,悲观锁么?什么情况下用乐观什么情况下用悲观么?
乐观锁:默认读数据的时候不会修改,所以不会上锁;
悲观锁:默认读数据的时候会修改,所以会上锁;
乐观锁适用于多读写比较少的情况,省去锁的开销,加大系统的吞吐量。
3.volatile关键字的作用?i++是原子性的么?
在当前的Java内存模型下,线程可以把变量保存在本地内存(比如机器的寄存器)中,而不是直接在主存中进行读写。这就可能造成一个线程在主存中修改了一个变量的值,而另外一个线程还继续使用它在寄存器中的变量值的拷贝,造成数据的不一致。
要解决这个问题,只需要像在本程序中的这样,把该变量声明为volatile(不稳定的)即可,这就指示JVM,这个变量是不稳定的,每次使用它都到主存中进行读取。一般说来,多任务环境下各任务间共享的标志都应该加volatile修饰。
Volatile修饰的成员变量在每次被线程访问时,都强迫从共享内存中重读该成员变量的值。而且,当成员变量发生变化时,强迫线程将变化值回写到共享内存。这样在任何时刻,两个不同的线程总是看到某个成员变量的同一个值。
使用volatile关键字修饰变量,线程要访问变量时都是从内存中读取,而不是从缓存当中读取,因此每个线程访问到的变量值都是一样的。
i++不是原子操作,分为三个阶段:内存到寄存器、寄存器自增、写会内存;这三个阶段中间都可以被中断分离开.
4.Java内存模型?为什么设置工作内存和主内存?
PS:JVM内存模型和JMM(Java内存模型)没有关系。JMM的目的是为了解决Java多线程对共享数据的读写一致性问题。
1.Lambda表达式的形式化表示如下所示
Parameters -> an expression
2.如果Lambda表达式中要执行多个语句块,需要将多个语句块以{}进行包装,如果有返回值,需要显示指定return语句,如下所示:
Parameters -> {expressions;};
3.如果Lambda表达式不需要参数,可以使用一个空括号表示,如下示例所示
() -> {for (int i = 0; i < 1000; i++) doSomething();};
5.如果Lambda表达式只有一个参数,并且参数的类型是可以由编译器推断出来的,则可以如下所示使用Lambda表达式,即可以省略参数的类型及括号
Stream.of(datas).forEach(param -> {System.out.println(param.length());});
参考:lambda表达式
9.设计模式知道么?
单例模式、工厂模式、观察者模式;
单例模式:
1.特点:
- 只能有一个实例;
- 必须自己创建自己的唯一实例;
- 必须给其他对象提供这一实例;
2.单例模式有两种写法:饿汉式和懒汉式;饿汉式是一旦类加载了,就把单例初始化完成;而懒汉式只有在调用getInstance的时候,才初始化这个单例。
3.懒汉式单例:
a.写代码(构造方法,创建实例,get);
b.非线程安全;
c.三种线程安全的代码+优缺点
syn:每次获取都需要同步,影响性能;
双重检查:判空后锁住类;为什么要第二次检查?创建实例的操作非原子化;在getInstance中做了两次null检查,确保了只有第一次调用单例的时候才会做同步,这样也是线程安全的,同时避免了每次都同步的性能损耗;
静态内部类:LazyHolder;利用了classloader的机制来保证初始化instance时只有一个线程,所以也是线程安全的,同时没有性能损耗;
4.饿汉式单例:线程安全;在类创建的同事就实例化一个静态对象出来。
工厂模式:
见印象笔记/设计模式;工厂方法模式和抽象工厂模式区别;
观察者模式:
角色:抽象观察者-update、具体观察者、抽象被观察者-attach/detach/notify、具体被观察者;
使用场景:一个对象状态更新,其他对象同步更新,只需要将自己更新通知给其他对象而不需要知道其他对象细节。解耦,各自变换互不影响。
10.项目难点?