| 这个作业属于哪个课程 | https://edu.cnblogs.com/campus/zswxy/computer-science-class3-2018/homework/11879 |
| 这个作业有什么要求 | https://edu.cnblogs.com/campus/zswxy/computer-science-class3-2018/homework/11879 |
| 学号 | 20188476 |
-
WordCount
-
Git项目地址
-
PSP表格
-
代码规范链接
-
解题思路描述
-
设计与实现过程
-
部分异常处理说明
-
心路历程与收获
-
Git项目地址
https://gitee.com/BX881206/project-java/tree/master
PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 1450 | 3000 |
| • Estimate | • 估计这个任务需要多少时间 | 1440 | 2880 |
| Development | 开发 | 720 | 960 |
| • Analysis | • 需求分析 (包括学习新技术) | 30 | 90 |
| • Design Spec | • 生成设计文档 | 20 | 10 |
| • Design Review | • 设计复审 | 20 | 10 |
| • Coding Standard | • 代码规范 (为目前的开发制定合适的规范) | 20 | 20 |
| • Design | • 具体设计 | 120 | 250 |
| • Coding | • 具体编码 | 640 | 720 |
| • Code Review | • 代码复审 | 30 | 30 |
| • Test | • 测试(自我测试,修改代码,提交修改) | 40 | 60 |
| Reporting | 报告 | 30 | 15 |
| • Test Report | • 测试报告 | 10 | 15 |
| • Size Measurement | • 计算工作量 | 15 | 10 |
| • Postmortem & Process Improvement Plan | • 事后总结, 并提出过程改进计划 | 30 | 25 |
代码规范链接
https://gitee.com/BX881206/project-java/blob/master/20188476/codestyle.md
解题思路描述
- 读取字符是一个一个读取输入的文件流,对其进行判断是否符合要求之后再进行计数(不符合要求的计数是无效的,必须对其进行判断)
- 读取单词,可以使用正则表达式来匹配单词,并过滤掉无效字符,以单词-频率作为键值对保存在TreeMap中
- 行数统计直接按行读取后使用trim()去掉空白字符后,再进行判断计数就可以了
设计与实现过程
-
类和函数关系图
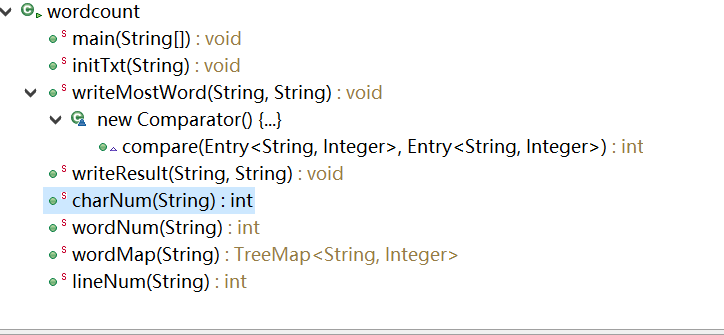
主要流程图
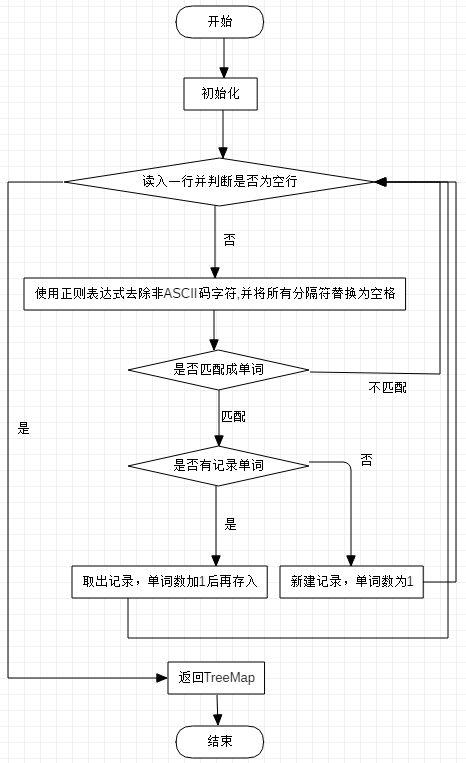
部分异常处理说明
1.通过CMD运行提示“编码GBK的不可映射字符”
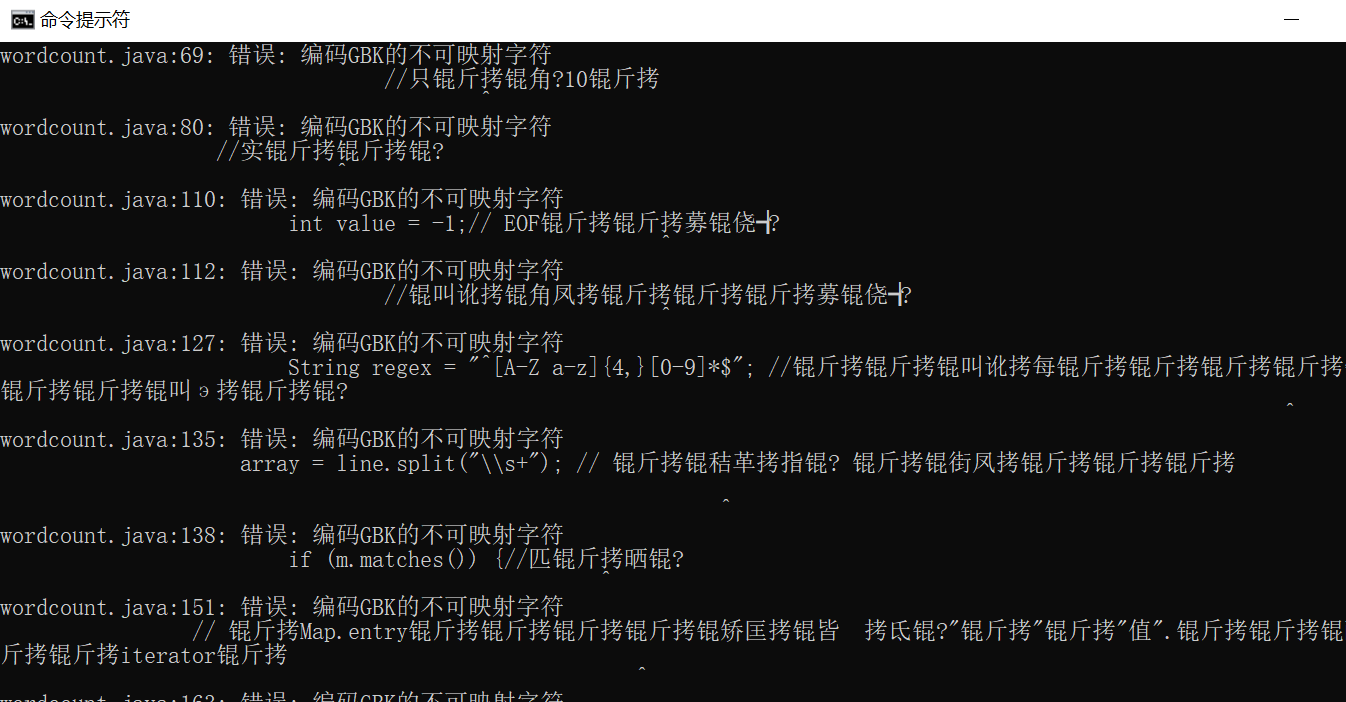
- 解决办法:查找了很多资料,收获了好几种方法,感觉最好用的是直接对.Java文件改编码方式

2.使用命令行编译时,由于一开始的项目在SRC目录下有包,.java文件在包里,所以javac 命令要进入到.java文件目录也就是最里层才可以,生成的.class文件和.java文件在同一目录。而使用java命令时,则要进到SRC目录下,包名作为前缀名来使用,并且名称不带后缀,格式如:java 包名.java文件名 才可以运行,然后我就直接重新新建了一个文件,运行成功了. -
关键代码
1.统计文件的字符数(对应输出第一行)
- 思路:用了BufferedReader去读取文本,用while循环去判断读入字符是否合法,最后return读取的字符数(具体可见注释部分)
- 独到之处:使用BufferedReader从字符输入流中读取文本,缓冲各个字符,从而实现字符,数组和行的高效读取,而且可以指定缓冲区的大小
public static int charNum(String filename) throws IOException {
//统计文件的字符数
int num = 0;
BufferedReader br = new BufferedReader(new FileReader(filename));
int value = -1;// EOF标记文件末尾
while ((value = br.read()) != -1) {
//判断是否读到了文件末尾
if (value > 0 && value < 128 && value != 13) {
//不统计回车符,ASCII正常十进制范围0~127
num ++;
}
}
br.close();
return num;
}
2.统计文件的单词总数(对应输出第二行),单词:至少以4个英文字母开头,跟上字母数字符号,单词以分隔符分割,不区分大小写。
- 思路:用了BufferedReader去读取文本,用正则表达式去判断匹配是否是有效单词,匹配成功则计数(具体可见注释部分)
- 独到之处:用正则表达式,Pattern类,Matcher类方法去匹配是否是有效单词
public static int wordNum(String filename) throws IOException {
//统计单词总数
int num = 0;
BufferedReader br = new BufferedReader(new FileReader(filename));
String separator = "[^A-Za-z0-9]";//分隔符
String regex = "^[A-Z a-z]{4,}[0-9]*$"; //正则判断每个数组中是否存在有效单词
Pattern p = Pattern.compile(regex);//使用Pattern.compile方法编译一个正则表达式,创建一个匹配模式
Matcher m = null;
String line = null;
String[] array = null;
while ((line = br.readLine()) != null) {
line = line.replaceAll("[(\u4e00-\u9fa5)]", "");// 用空格替换汉字
line = line.replaceAll(separator, " "); // 用空格替换分隔符
array = line.split("\s+"); // 按空格分割 →字符串数组
for (int i = 0;i<array.length;i++) {
m = p.matcher(array[i]);//进行匹配,看是否是有效单词
if (m.matches()) {//匹配成功
num++;
}
}
}
br.close();//关闭缓冲区
return num;//返回单词数
}
3.统计文件的有效行数(对应输出第三行):任何包含非空白字符的行,都需要统计
- 思路:行数统计直接按行读取后使用trim()函数去掉空白字符后,再对行数进行判断
- 独到之处:使用了trim()函数去掉了字符串首尾的空格
public static int lineNum(String filename) throws IOException {
//统计行数
int num = 0;
BufferedReader br = new BufferedReader(new FileReader(filename));
String line = null;
while ((line = br.readLine()) != null) {
if (line.trim().length() != 0) {//使用trim()函数去掉字符串首尾的空格
num ++;
}
}
br.close();
return num;
}
4.统计文件中各单词的出现次数(对应输出接下来10行),最终只输出频率最高的10个
- 思路:正则表达式判断匹配单词,匹配成功则计数(具体可见注释部分)
- 独到之处:单词-次数作为键值对保存在TreeMap中,运用toLowerCase()方法将字符串数组中的元素转换成小写
public static TreeMap<String, Integer> wordMap(String filename) throws IOException {
TreeMap<String, Integer> tm = new TreeMap<String, Integer>();
BufferedReader br = new BufferedReader(new FileReader(filename));
String separator = "[^A-Za-z0-9]";//分隔符
String regex = "^[A-Za-z]{4,}[0-9]*$"; // 正则判断每个数组中是否存在有效单词
Pattern p = Pattern.compile(regex);//使用Pattern.compile方法编译一个正则表达式,创建一个匹配模式
String str = null;
Matcher m = null;
String line = null;
String[] array = null;
while ((line = br.readLine()) != null) {
line = line.replaceAll("[(\u4e00-\u9fa5)]", "");// 过滤汉字
line = line.replaceAll(separator, " "); // 用空格替换分隔符
array = line.split("\s+"); // 按空格分割
for (int i = 0;i<array.length;i++) {
m = p.matcher(array[i]);//
if (m.matches()) {//如果正确匹配
str = array[i].toLowerCase();//运用toLowerCase()方法将字符串数组中的元素转换成小写
if (!tm.containsKey(str)) {//用containsKey()方法看对应单词是否大小写重复
tm.put(str, 1);//输出对应单词小写
} else {
int count = tm.get(str) + 1;//单词没有重复则单词出现次数+1
tm.put(str, count);//输出对应单词小写和单词出现的次数
}
}
}
}
br.close();
return tm;
}
5.对单词进行排序并输出
- 思路:以单词-频率作为键值对保存在TreeMap中,TreeMap会根据键的字典序自动升序排列,按照频率优先的顺序输出频率最高的10个单词(具体可见注释部分)
- 独到之处:以单词-频率作为键值对保存在TreeMap中,TreeMap会根据键的字典序自动升序排列
public static void writeMostWord(String infilename,String outfilename) throws IOException {//按照格式输出结果
String outpath = new File(outfilename).getAbsolutePath();
FileWriter fw = new FileWriter(outpath, true);
TreeMap<String, Integer> tm = wordMap(infilename);
if(tm != null && tm.size()>=1)
{
List<Map.Entry<String, Integer>> list = new ArrayList<Map.Entry<String, Integer>>(tm.entrySet());
// 通过比较器来实现排序
Collections.sort(list, new Comparator<Map.Entry<String, Integer>>() {
public int compare(Entry<String, Integer> o1, Entry<String, Integer> o2) {
//treemap默认按照键的字典序升序排列的,所以list也是排过序的,在值相同的情况下不用再给键升序排列
// 按照值降序排序
return o2.getValue().compareTo(o1.getValue());
}
});
int i = 1;
String key = null;
Integer value = null;
for (Map.Entry<String, Integer> mapping : list) {
key = mapping.getKey();
value = mapping.getValue();
System.out.print("<" + key + ">: " + value + '
');
fw.write("<" + key + ">: " + value + '
');
//只输出前10个
if (i == 10) {
break;
}
i++;
}
}
fw.close();
}
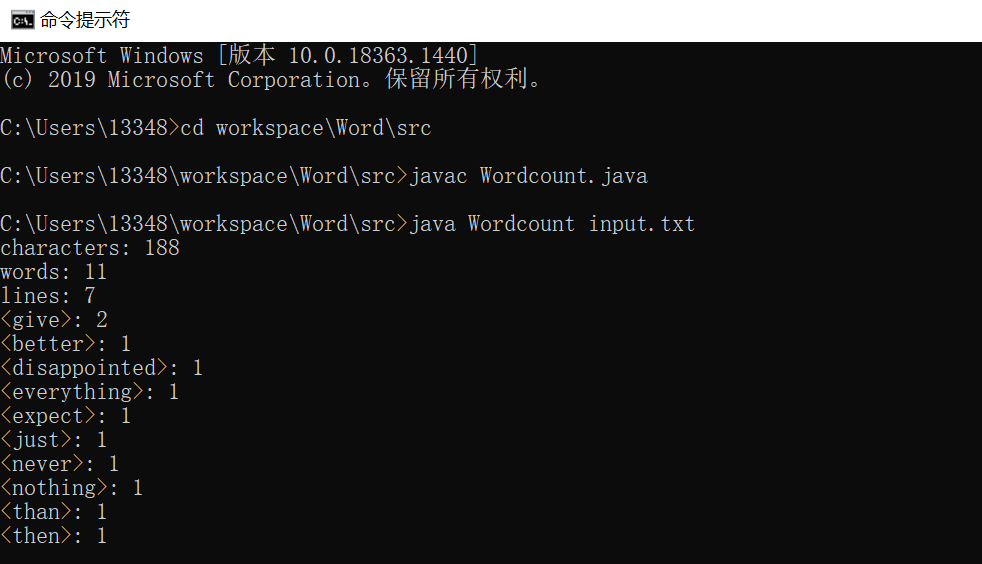
6.测试程序
- input文件
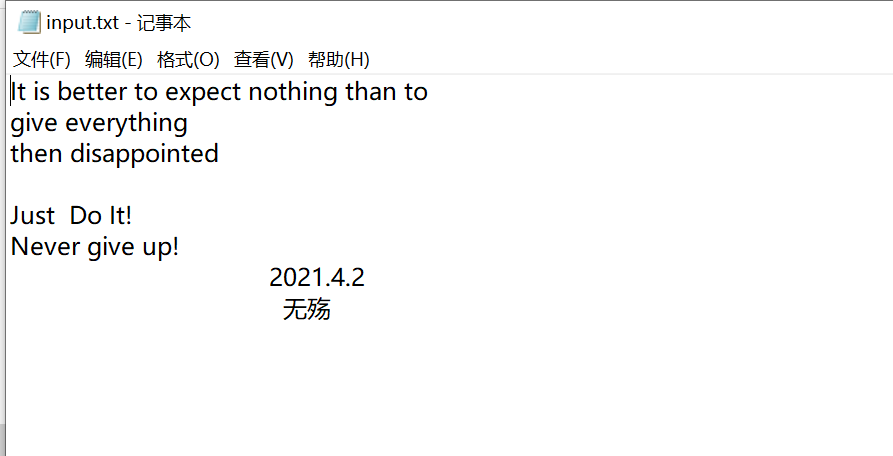
- output文件

- 运行结果
心路历程与收获
第一眼看到这个作业就蒙了,因为作业描述实在太多了,本能排斥这次作业,就一直拖着,看着离ddl越来越近,在接近只有八天的时候,我坐不住了,就开始着手完成这次作业,查了大量资料,虽然这次作业真的很困难,但感觉自己真的学到了很多,复习了Java语言,学到了很多新的方法,正则表达式的作用太大了,pattern类和matcher类方法很有妙用,经过这次作业,也让我感觉到自身实力的不足,还得多加努力才行.
