◆版权声明:本文出自胖喵~的博客,转载必须注明出处。
转载请注明出处:http://www.cnblogs.com/by-dream/p/7683126.html
前言
机器翻译的评测,很大程度上会依赖评测集。制作一份好的评测集,远远没有我们想象的那么简单。
今天我就将自己制作评测集的经验分享给大家。以一个制作“几十句口语关于天气的英中评测集”为例。
收集原句
首先收集指定数量的讨论天气的口语句子。这些句子都是都是通过花钱,找国外的朋友帮忙收集来的,因此这些英文句子非常的native。
人工评价
将收集来的原句用目前当下比较流行的翻译引擎翻译了一遍。这里选取了百度、有道、搜狗、google、腾讯翻译君nmt2.0,然后将机器翻译结果生成一个评测问卷,针对译文的质量进行一个1—5分的打分:
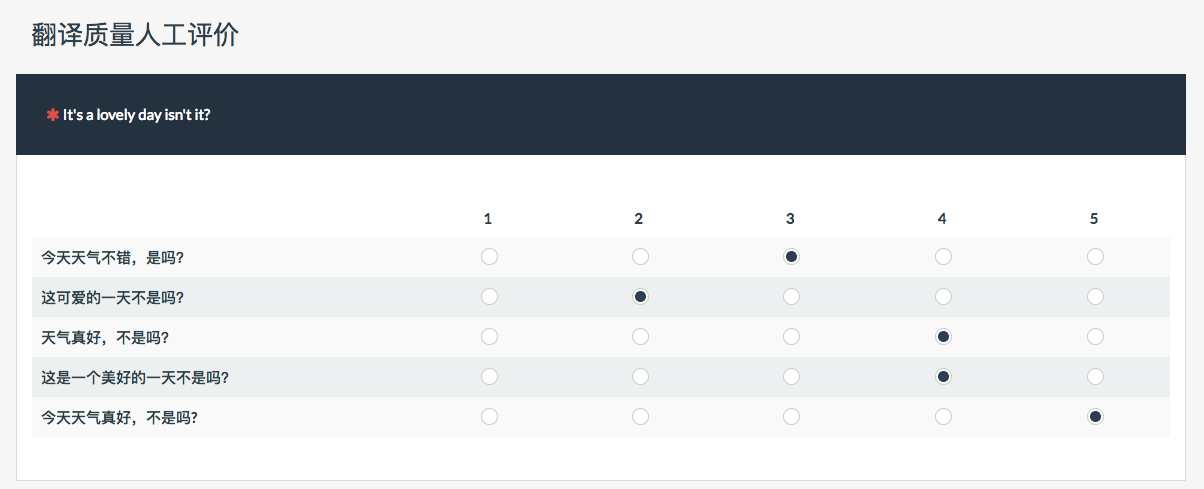
一般打分需要专业的人士来打,并且对他们的结果进行一个相关度的计算,剔除非法的数据,这个过程我就不细说了。这是打分后的一个统计结果如下所示:

可以看到腾讯翻译君的翻译质量是最高的,人工可接受度达到了91%,其次分别是百度、有道、搜狗和google。因此我们的评测集在BLEU上的相关性也需要和这个结果保持一致。
译文制作
接下来了解了各个翻译引擎的好坏后,我们就可以开始制作评测集了,首先找专业的译员对原句进行翻译制作评测集,这里我找了英语专业的学生对原文进行了翻译。然后我们用她翻译的结果做为译文,进行制作参考答案,这里需要注意的是,由于BLEU算法的特性,因此中文的译文需要按单字切词:
例如:“这个月的18号,我要去一趟Atlanta。” 转化后为 “这 个 月 的 18 号 ,我 要 去 一 趟 Atlanta 。 ”
然后针对翻译结果进行BLEU值的计算。
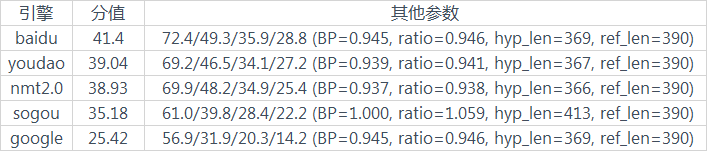
很明显这个结果和人工评价的结果相差过大,那么究竟问题出在哪里了呢?
译文分析、修改、迭代
根据BLEU算法的特性,我们知道BLEU的分值高低取决于翻译译文和参考译文之间的相似度。于是我简单看了一下,发现可能是句子过于短,ref的答案过于单一,不够丰富导致的分值上有所差异,因此又增加了几个ref的制作,具体是在各个翻译引擎翻译的基础上,又进行修改,得到高质量的译文。总共下来一共制作了9分ref。
此时得到的结果:

可以看到,和之前相比较分值虽然高了,但是和人工评价的一致性还是比较差,因此我们就需要对单句进行分析,看看具体是哪些句子造成了影响。
这里我用python的nltk实现了一个BLEU单句分析的脚本:
#-*- coding:utf-8 -*- import nltk import sys import codecs # 功能:传入计算译文单句BLEU的功能 # 调用方式:python 脚本.py 参考答案1+参考答案2 要分析的译文 # 参数一:可以是多份译文例如 t_tmq_ref0+t_tmq_ref1 用+连接即可 # 参数二:要计算的译文 ''' nltk 简单用法 print nltk.translate.bleu_score.corpus_bleu(['把 卷 子 往 后 传'], ['把 这 些 纸 往 后 传 。'],['把 这 些 床 单 递 回 去 。'] ) print nltk.translate.bleu_score.corpus_bleu(['天 气 很 好'], ['天 气 很 不 错']) print nltk.translate.bleu_score.sentence_bleu('天 气 非 常 不 错', '天 气 很 不 错' ) ''' reffiles = sys.argv[1] file2 = sys.argv[2] list_all_ref = [] list2 = [] # 读取译文 i = 0 for sen in open(file2): sen = sen.strip() if sen: list2.append(sen) i = i+1 else: print i, "is null" # 读取ref for reffile in reffiles.split('+'): list_ref = [] for line in open(reffile): line = line.strip() if line: list_ref.append(line) list_all_ref.append(list_ref) setnum = len(list_all_ref) sentencenum = len(list_all_ref[0]) log = codecs.open("res_"+file2 , 'w', 'utf-8') # 单句计算 for j in range(0, sentencenum): refs = [] for i in range(0, setnum): refs.append(list_all_ref[i][j]) try: #print refs #print list2[j] BLEUscore = nltk.translate.bleu_score.corpus_bleu([refs], [list2[j]]) print j, BLEUscore log.write(str(BLEUscore)+' ') except Exception as e: print 'except!',e break
利用脚本计算结果,如下所示
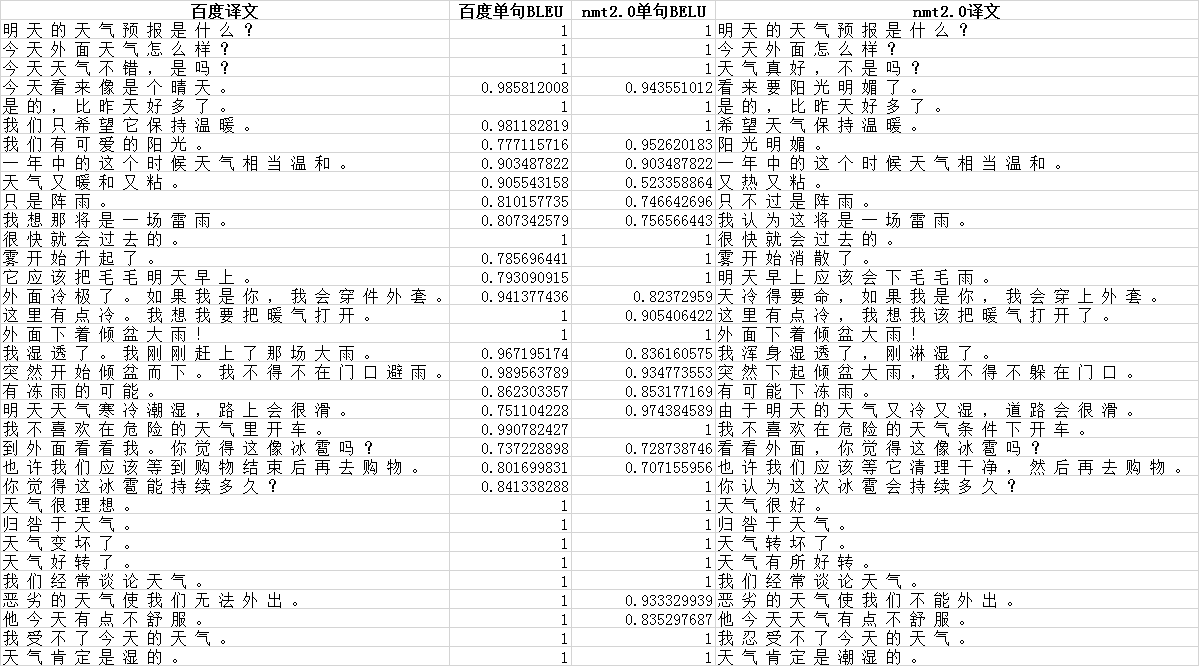
第一列是百度的译文,第二列是百度单句的一个BLEU得分,第三列是腾讯翻译君nmt2.0的BLEU得分,第四列是翻译君的译文。我们可以通过看句子找到一些分值不合理的句子,用红色标注。
例如下面这句,很明显百度的翻译没有翻译君的好,但是BLEU分值却高。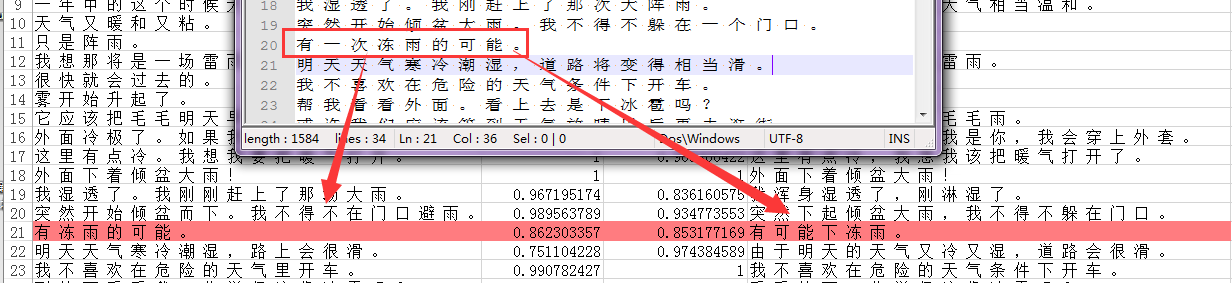
经过检查参考译文,发现有一份参考译文中有低质量的翻译句子。于是我们需要对这些句子再进行修改。当然如果人力不足和时间不足的情况下,这种现象无法避免。虽然可以通过要求第一遍制作就不出这些问题,但是真的很难。这里之所以列出这个方法,也是想说明,如果遇到这样的问题,可以通过这样一种方法来分析并且可以知道译文是否的可靠。
好,我们根据刚才所说的方法,修正完所有的译文后,再次重新计算bleu。
修正后的 百度和nmt2.0的分值对比为:
nmt2.0
BLEU = 77.71, 93.4/84.5/76.0/64.9 (BP=0.984, ratio=0.984, hyp_len=364, ref_len=370)
baidu
BLEU = 76.96, 92.4/82.4/73.1/64.4 (BP=0.995, ratio=0.995, hyp_len=369, ref_len=371)
从分值排名来看,这次更符合实际了,因此用同样的方法处理了剩余的,最终得到了如下结果(注意这里的结果采取的是去掉和引擎相关的ref计算的BLEU,因此是两两比较):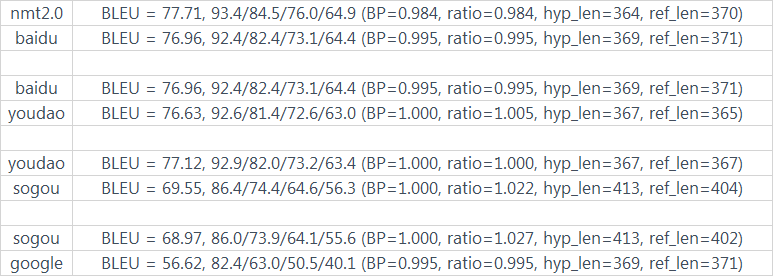
根据分值,我们简单看下和人工评价的相关性
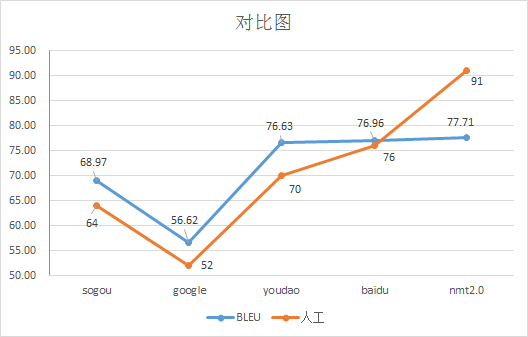
很明显,在百度和nmt2.0的比较重相关性不是高,于是我在想,是不是当时在中文分词的时候影响了最终的数据结果,于是我决定用分词代替中文单词切词的方式,再计算一次BLEU。
这次分词效果和之前不一样的是:
例如:“这个月的18号,我要去一趟Atlanta。” 转化后为 “ 这个月 的 18号 , 我 要去 一趟 Atlanta 。 ”
计算的BLEU结果为:
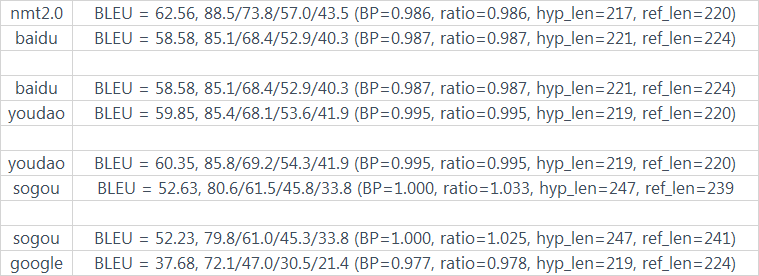
这次可以看到nmt2.0和百度的分值已经稍微有些拉开了,但是有道和百度的排名却换了一个位置。于是针对有道和百度,我对每个句子又进行了单句BLEU的分析,以及将人工评价的打分也列到这里进行对比:

我们单看上图中标注的这句话,这句话应该被正确翻译为 “ 我希望天气能一直保持温暖 ” ,因此人工评价的时候,考虑到“天气”这个重要的词没有被翻译出来,因此给打了2分,但是BLEU算法匹配到了大部分的词,只是少了天气,因此BLEU给出的分值不会很低,要比人工评价的结果高。因此我们看出BLEU算法针对翻译的流畅度评价是一个比较好的打分,但是对于一些核心词语的翻译的重视度,BLEU算法却忽略了,因此我觉得百度和有道的差距应该就在这里了 。
至此我们就算完成了一份偏流畅度的关于天气口语评测的评测集。(所有数据)