ELK6.5.4安装文档
1.本地环境介绍
|
IP |
用户 |
组件 |
|
192.168.10.124 |
elk |
elasticsearch ,head |
|
192.168.10.184 |
elk |
kibana,kibana汉化 |
|
192.168.10.116 |
elk |
logstash,测试日志 |
2. Elasticsearch
2.1 elasticsearch基本概念
Index
类似于mysql数据库中的database
Type
类似于mysql数据库中的table表,es中可以在Index中建立type(table),通过mapping进行映射。
Document
由于es存储的数据是文档型的,一条数据对应一篇文档即相当于mysql数据库中的一行数据row,一个文档中可以有多个字段也就是mysql数据库一行可以有多列。
Field
es中一个文档中对应的多个列与mysql数据库中每一列对应
Mapping
可以理解为mysql或者solr中对应的schema,只不过有些时候es中的mapping增加了动态识别功能,感觉很强大的样子,其实实际生产环境上不建议使用,最好还是开始制定好了对应的schema为主。
indexed
就是名义上的建立索引。mysql中一般会对经常使用的列增加相应的索引用于提高查询速度,而在es中默认都是会加上索引的,除非你特殊制定不建立索引只是进行存储用于展示,这个需要看你具体的需求和业务进行设定了。
Query DSL
类似于mysql的sql语句,只不过在es中是使用的json格式的查询语句,专业术语就叫:QueryDSL
GET/PUT/POST/DELETE
分别类似与mysql中的select/update/delete......
2.2 JDK安装
需要jdk1.8以上版本,网上下载
配置环境变量:
***************************************************
JAVA_HOME=/root/baiyang/jdk1.7.0_80 #jdk安装路径
PATH=$JAVA_HOME/bin:$PATH
CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export JAVA_HOME
export PATH
export CLASSPATH
***************************************************
2.3 Elasticsearch6.5.4 安装
2.3.1 安装
下载地址:https://www.elastic.co/cn/downloads
#Elasticsearch 默认不允许用root用户登录,会报错,如果真想用root需要进行配置
1.创建用户useradd ekl
2.修改密码:root 用户下 passwd elk
3.上传压缩包到/home/elk
4.Tar -zxvf elasticsearch-6.5.4.tar.gz
5.系统启动:[elk@myhost bin]$ ./elasticsearch ,
后台启动 nohup ./elasticsearch &
- 配置文件修改
*****************************************************
#集群地址
discovery.zen.ping.unicast.hosts: ["192.168.10.124", "127.0.0.1"]
#主节点数
discovery.zen.minimum_master_nodes: 1
#集群名称
cluster.name: my-application
#节点名称
node.name: node-1
#日志路径
path.data: /home/elk/elasticsearch-6.5.4/data
path.logs: /home/elk/elasticsearch-6.5.4/log
#监听ip端口
network.host: 192.168.10.124
http.port: 9200
bootstrap.memory_lock: false
bootstrap.system_call_filter: false
http.cors.enabled: true
http.cors.allow-origin: "*"
*****************************************************
2.3.2 主机参数修改
修改参数是为了解决es启动时的这三个报错
[1]: max file descriptors [4096] for elasticsearch process is too low, increase to at least [65536]
[2]: memory locking requested for elasticsearch process but memory is not locked
[3]: system call filters failed to install; check the logs and fix your configuration or disable system call filters at your own risk
vi /etc/sysctl.conf
添加下面配置:
*********************************
vm.max_map_count=655360
*********************************
并执行命令:
sysctl -p
vi /etc/security/limits.con
#正常只需要修改此文件就OK,elk soft nofile 65536,此处elk可以改为*,但是部分系统如unbuntu会有bug,*不好使,所以可以指定用户
*********************************
* soft nproc 4096
* hard nproc 4096
root soft nproc unlimited
elk soft nofile 65536
elk hard nofile 65536
*********************************
#如果上面修改没有生效,那么修改下面文件,系统会优先加载下面文件,并且会覆盖上面文件,如果使上面文件生效,可以直接清空下面文件
Vi /etc/security/limits.d/90-nproc.conf
*********************************
* soft nproc 65535
elk soft nproc 65535
*********************************
2.4 head插件安装
2.4.1 Head 插件简介
就是一个界面化的es集群调试工具,没有这个也可以通过命令调试,但是非常非常麻烦
2.4.2 head插件安装
手动下载:下载地址:https://github.com/mobz/elasticsearch-head;点击clone or download按钮,点击download zip进行下载。下载完毕后解压放在elasticsearch平级路径上。
说明:5.6版本不能用/bin/plugin -install mobz/elasticsearch-head安装了(好像5.x之前的版本可以这么安装)
也可以在命令下载:

2.4.3 node.js安装
这个比较容易,下载后除路径自己填写外,其他直接next就OK了。下载地址:https://nodejs.org/en/download/ 。
源码安装方法:
yum -y install gcc make gcc-c++ openssl-devel wget
下载源码及解压: wget http://nodejs.org/dist/v0.10.26/node-v0.10.26.tar.gz
tar -zvxf node-v0.10.26.tar.gz
编译及安装: cd node-v0.10.26
make && make install
验证是否安装配置成功: node -v
2.4.3 grunt安装
cd elasticsearch-head-master
npm install -g grunt-cli //执行后会生成node_modules文件夹
npm install
修改 vim _site/app.js 文件:修改head的连接地址:
this.base_uri = this.config.base_uri || this.prefs.get(“app-base_uri”) || “http://localhost:9200“;
修改成ElasticSearch的机器地址
this.base_uri = this.config.base_uri || this.prefs.get(“app-base_uri”) || “http://192.168.0.153:9200“;
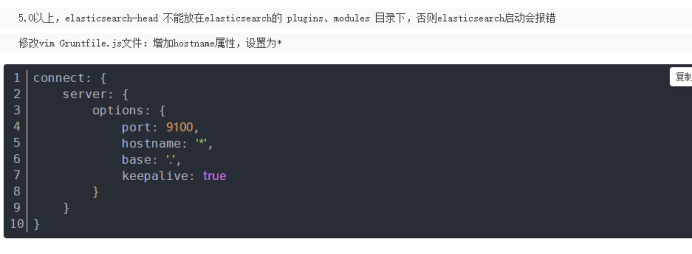
修改完成你就可以启动head插件了:在 elasticsearch-head-master下启动服务
cd elasticsearch-head-master
grunt server & #后台启动
3. Logstash
3.1安装
下载,上传,解压,无特殊说明
3.2配置
*************************************************
node.name: logstash.node1
#path.data: /home/elk/elk/logstash-6.5.4/data
#pipeline.workers: 2
#pipeline.output.workers: 1
#pipeline.batch.size: 125
#path.config: /
#config.reload.automatic: true
#onfig.reload.interval: 60
#path.logs: /home/elk/elk/logstash-6.5.4/log
#http.host: 192.168.10.170
#http.port: 5000-9700
#log.level: info
#log.format: * plain*
#path.plugins
*************************************************
3.3调试
屏幕调试模式:
单机调试:logstash -e 'input{stdin{}}output{stdout{codec=>rubydebug}}'
连接远程elasticsearch调试:
[elk@myhost bin]$ ./logstash -e 'input {
stdin{}
}
output{
elasticsearch{ hosts=>["http://192.168.10.124:9200"]}
}'
------------------------------------------------------------------------------------------
input {
beats {
port => 5044
}
file {
#日志路径
path => ["/data/*"]
#日志类型 kibana能用到,logstash也能用到这个参数
type => "system"
start_position => "beginning"
}
}
output {
elasticsearch {
hosts =>["http://192.168.10.124:9200"]
index =>"data_log-%{+YYYY.MM.dd}"
}
stdout {
codec=>"rubydebug"
}
}
------------------------------------------------------------------------------------------
可以将上面配置写入一个配置文件 xxx.conf
Logstash/Bin 下 ./logstash -f xxx.comf
3.4.插件简解
3.4.1File插件
使用,输入,读取日志位置
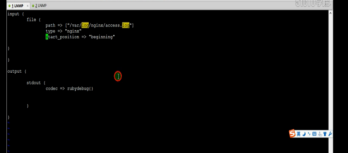
File插件讲解:beginning ,会从path 路径文件头开始读取,会把读取位置存储到本地数据库
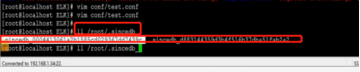
/home/elk/elk/logstash-6.5.4/data/plugins/inputs/file
下次继续从该位置开始读取
想要从新读取,删除数据库文件
3.4.2multline插件
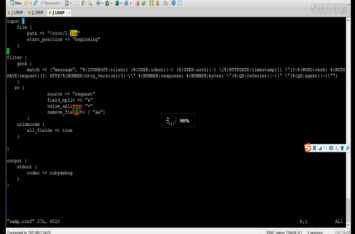
正则表达式过滤,将 [ 开头视为一行的开始
3.4.3Grop ,kv插件
过滤,拆分
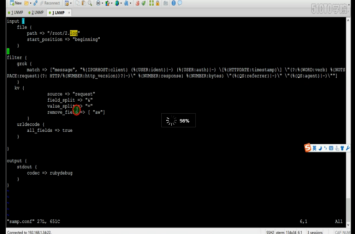
Filter 过滤器参数和在线调试工具
3.4.4Json 插件
读取json格式文件
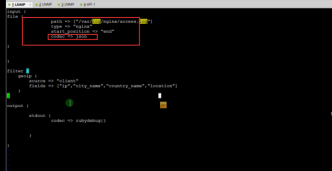
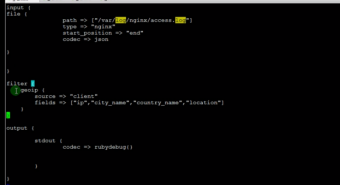
3.4.5Geoip 插件
通过ip,判断ip来源,属于哪个地方,哪个城市
4、Kibana
4.1安装
启动 bin目录下 ./kabana
配置文件修改conf目录下,kibana.yml
server.port : 5601
server.host : 192.168.10.184 #本机
elasticsearch.url : http://192.168.10.124:9200
下面配置测试未生效
********************************
#解决页面访问Kibana server is not ready yet
kibana.index: ".newkibana"
xpack.security.enabled: false
npm update caniuse-lite browserslist
********************************
启动报错:如报错末尾出现[waring] 具体内容忘了,提示等待或者重启kinaba
需要在elasticsearch -head 插件界面上 删除kinaba的索引并重启kibana,
命令行应该也能删除,可惜不会
4.2 Kibana汉化
启动:bin目录下./kibana
kibana [kɪbana]
需要安装python环境
# 下载并解压 wget https://github.com/anbai-inc/Kibana_Hanization/archive/master.zip
unzip master.zip
cd master
# 汉化 python main.py Kibana目录
将索引变为非只读,解决kibana启动时报错,报错具体内容忘了,大概意思就是索引加载失败
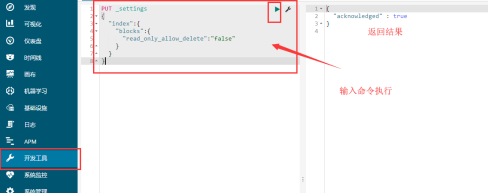

5.ELK的访问认证
建议用ng代理实现,找人配置
6.ELK环境信息收集
1.ELK主机环境,cpu,内存,磁盘,主机个数
2.日志收集方式,文件,端口。。。
3.日志类别,系统日志,服务日志,ng日志。。。
4.日志服务器个数,cpu,内存
5.日志过滤规则
6.日志收集规则,全部收集,部分收集
7.ELK 目标要求,具体做什么
8.日志大小,单位时间大小
9.日志留存规则,留存时间,备份数目
7.ELK性能优化,参数配置
以下为网上搜索来的,原链接都在下面
------------------------------------------------ES优化-----------------------------------------------
参考文档https://blog.csdn.net/cjfeii/article/details/79771409
Index 月为单位做索引
Cluster 3
index.number_of_shards 分片大小32G(预估一下)左右,数量<50
index.number_of_replicas 2(2个副本加上自己就三个)
index.translog.durability:async 异步持久化
index.translog.sync_interval:60s 1分钟一写入
index.refresh_interval 索引刷新时间,默认1s,写入慢可以加长
client: Bulk write
4. ElasticSearch
index.number_of_shards:36
index.number_of_replicas:0
index.refresh_interval:60s
index.translog.durability:async
index.translog.sync_interval:60s
Mapping.all.enabled:false
client: Bulk write
bulk写入能成倍的提升写入性能
建议的bulk大小是:5-15MB,这个写入能力是根据logstash 日志大小,单位写入数量来计算
--------------------------------logstash优化-------------------------------------------------
worker: 40
batch_size: 150
Input.consumer_threads:5
Output.flush_size:1500
Output.idle_flush_time:30
Output.workers: 20
Filter.grok
单机写入提升: 2000/s -> 18000/s
worker
logstash worker的数量,默认是机器cpu的核心数
logstash的瓶颈一般都在filter上,增大worker的数量,可以有效提升filter的效率
可以设置为略高于CPU核心数
./bin/logstash -w 48 ...
batch_size
表示worker一次批量处理的数据条数,默认是150
和ES的bulk写入有关系:worker * batch_size / flush_size = ES bulk index api 调用次数
./bin/logstash -w 48 -b 300 ...
Input.consumer_threads
该参数用于标识消费者的线程数,是在logstash.conf中指定的
该参数标识至少会占用kafka的partition的数目
配置的时候需要注意,避免占用过多的partition,导致其他logstash进程饿死
Output.flush_size&Output.idle_flush_time
用来表示flush的大小以及频率
控制着bulk的大小
Filter.grok
grok是logstash的filter插件中的功能,用来对日志数据进行正则匹配实现各个字段的切割
增加锚点可以有效提升性能,比如:^、$等
使用合适的类型去分割字段,尽量避免使用DATA
------------------------------------------------------------------------------------------
ElasticSearch配置文件说明
1、cluster.name:elasticsearch
配置es的集群名称,默认是elasticsearch,es会自动发现在同一网段下的es,如果在同一网段下有多个集群,就可以用这个属性来区分不同的集群。
2、node.name:”FranzKafka”
节点名,默认随机指定一个name列表中名字,该列表在es的jar包中config文件夹里name.txt文件中,其中有很多作者添加的有趣名字。
3、node.master:true
指定该节点是否有资格被选举成为node,默认是true,es是默认集群中的第一台机器为master,如果这台机挂了就会重新选举master。
4、node.data:true
指定该节点是否存储索引数据,默认为true。
5、index.number_of_shards:5
设置默认索引分片个数,默认为5片。
6、index.number_of_replicas:1
设置默认索引副本个数,默认为1个副本。
7、path.conf:/path/to/conf
设置配置文件的存储路径,默认是es根目录下的config文件夹。
8、path.data:/path/to/data
设置索引数据的存储路径,默认是es根目录下的data文件夹,可以设置多个存储路径,用逗号隔开,例:path.data:/path/to/data1,/path/to/data2
9、path.work:/path/to/work
设置临时文件的存储路径,默认是es根目录下的work文件夹。
10、path.logs:/path/to/logs
设置日志文件的存储路径,默认是es根目录下的logs文件夹
11、path.plugins:/path/to/plugins
设置插件的存放路径,默认是es根目录下的plugins文件夹
12、bootstrap.mlockall:true
设置为true来锁住内存。因为当jvm开始swapping时es的效率会降低,所以要保证它不swap,可以把ES_MIN_MEM和ES_MAX_MEM两个环境变量设置成同一个值,并且保证机器有足够的内存分配给es。同时也要允许elasticsearch的进程可以锁住内存,linux下可以通过ulimit-l unlimited命令。
13、network.bind_host:192.168.0.1
设置绑定的ip地址,可以是ipv4或ipv6的,默认为0.0.0.0。
14、network.publish_host:192.168.0.1
设置其它节点和该节点交互的ip地址,如果不设置它会自动判断,值必须是个真实的ip地址。
15、network.host:192.168.0.1
这个参数是用来同时设置bind_host和publish_host上面两个参数。
16、transport.tcp.port:9300
设置节点间交互的tcp端口,默认是9300。
17、transport.tcp.compress:true
设置是否压缩tcp传输时的数据,默认为false,不压缩。
18、http.port:9200
设置对外服务的http端口,默认为9200。
19、http.max_content_length:100mb
设置内容的最大容量,默认100m
20、http.enabled:false
是否使用http协议对外提供服务,默认为true,开启。
21、gateway.type:local
gateway的类型,默认为local即为本地文件系统,可以设置为本地文件系统,分布式文件系统,hadoop的HDFS,和amazon的s3服务器,其它文件系统的设置方法下次再详细说。
22、gateway.recover_after_nodes:1
设置集群中N个节点启动时进行数据恢复,默认为1。
23、gateway.recover_after_time:5m
设置初始化数据恢复进程的超时时间,默认是5分钟。
24、gateway.expected_nodes:2
设置这个集群中节点的数量,默认为2,一旦这N个节点启动,就会立即进行数据恢复。
25、cluster.routing.allocation.node_initial_primaries_recoveries:4
初始化数据恢复时,并发恢复线程的个数,默认为4。
26、cluster.routing.allocation.node_concurrent_recoveries:2
添加删除节点或负载均衡时并发恢复线程的个数,默认为4。
27、indices.recovery.max_size_per_sec:0
设置数据恢复时限制的带宽,如入100mb,默认为0,即无限制。
28、indices.recovery.concurrent_streams:5
设置这个参数来限制从其它分片恢复数据时最大同时打开并发流的个数,默认为5。
29、discovery.zen.minimum_master_nodes:1
设置这个参数来保证集群中的节点可以知道其它N个有master资格的节点。默认为1,对于大的集群来说,可以设置大一点的值(2-4)
30、discovery.zen.ping.timeout:3s
设置集群中自动发现其它节点时ping连接超时时间,默认为3秒,对于比较差的网络环境可以高点的值来防止自动发现时出错。
31、discovery.zen.ping.multicast.enabled:false
设置是否打开多播发现节点,默认是true。
32、discovery.zen.ping.unicast.hosts:[“host1”, “host2:port”,”host3[portX-portY]”]
设置集群中master节点的初始列表,可以通过这些节点来自动发现新加入集群的节点
参考文档
Es分片和副本操作https://blog.csdn.net/jiao_fuyou/article/details/50501717
Es 配置文件中文详解https://blog.csdn.net/baicd1990/article/details/79287517
外部无法访问解决办法
需要修改network.host为实际ip或0.0.0.0,还无法连接应该是端口被防火墙拦截,建议使用方法一开启相关端口
方法一:开始相关端口
- 编辑/etc/sysconfig/iptables文件:vi /etc/sysconfig/iptables
加入内容并保存:-A RH-Firewall-1-INPUT -m state --state NEW -m tcp -p tcp --dport 8080 -j ACCEPT
2.重启服务:/etc/init.d/iptables restart
3.查看端口是否开放:/sbin/iptables -L -n
方法二:命令行开启防火墙
1.开启防火墙:systemctl start firewalld.service
2.开启5601端口:firewall-cmd --permanent --zone=public --add-port=5601/tcp
3.重启防火墙:firewall-cmd –reload
方法三:关闭防火墙
1) 重启后生效
开启: chkconfig iptables on
关闭: chkconfig iptables off
2) 即时生效,重启后失效
开启: service iptables start
关闭: service iptables stop