一、定位慢查询
可以通过mysql 日志记录慢查询,一旦有sql 执行时间超过了设定的慢查询时间,就会被记录到慢查询日志中,这样我们就可以从慢查询日志中定位慢查询 sql ,然后进行分析优化
判断数据库是否开启慢查询功能、以及慢查询日志保存路径
show variables like 'slow_query%';

mysql 默认的满查询是关闭的,现在通过命令行开启(不推荐,建议使用修改 my.ini)
SET global slow_query_log='ON';
set global slow_query_log_file='D:\mysql-8.0.21-winx64\slowlog\slow.log';
SET global long_query_time=3
flush privileges
配置好发现sql 查询没有生效,参考https://my.oschina.net/u/3495789/blog/4346542
因为缺少一个配置: log_queries_not_using_indexes ,该配置必须打开才能生效
此处命令行配置,数据库重启就失效,如果需要永久生效,则需要修改my.ini 配置
[mysqld]
slow-query-log= on
slow_query_log_file =D:/mysql-8.0.21-winx64/slowlog/slow.log
long_query_time = 1
log_queries_not_using_indexes = on
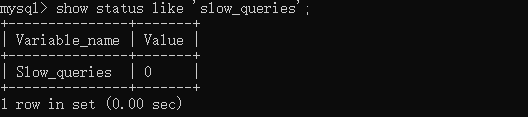
显示慢查询次数
show status like 'slow_queries';
查看慢查询默认的时间
SHOW VARIABLES LIKE 'long_query_time'

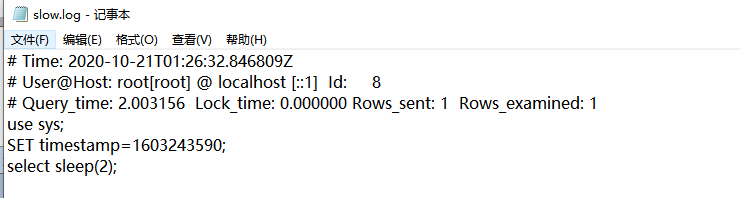
测试慢查询是否生效
select sleep(2);

此处开启了非索引记录慢查询日志


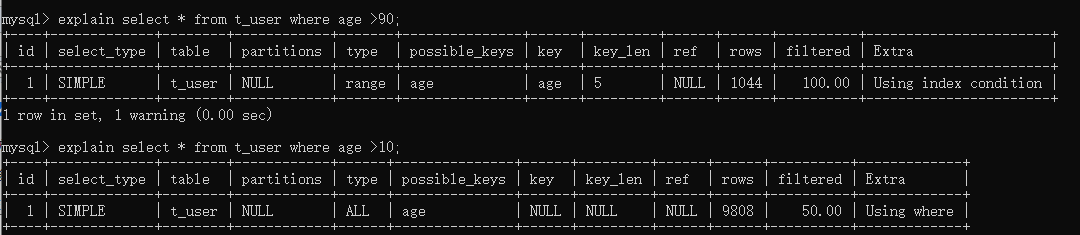
使用了索引字段作为条件不一定走索引:得分析具体的数据,选择效率最高的
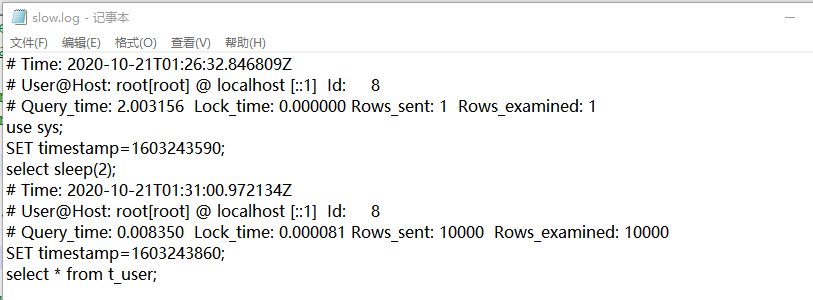
都执行后(时间都大于 1s),但是只记录了非索引的满查询
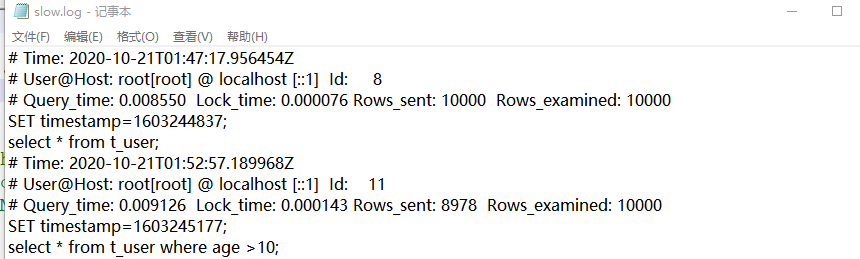
那么走索引的慢查询如何记录?
经过查询相关资料,发现自己的一个小错误,以及没有注意到的点

此处查询的 0.03 sec 表示查询的时间的 0.03秒,只是全部显示出来消耗较多的时间。MySQL 慢查询记录的是查询,并非返回时间。所以可以将慢日志的时间改为: 0.001 ,记录大于 1 毫秒的查询

Query_time 显示的是妙,转换为毫秒是26 毫秒,而显示出来却是0.03 秒(30毫秒),这里就产生了显示的误差
此外还发现有趣的问题,全表扫描查询 时间是0.03秒,却记录的(此处以及将满时间修改为1s),而sleep 却不记录?
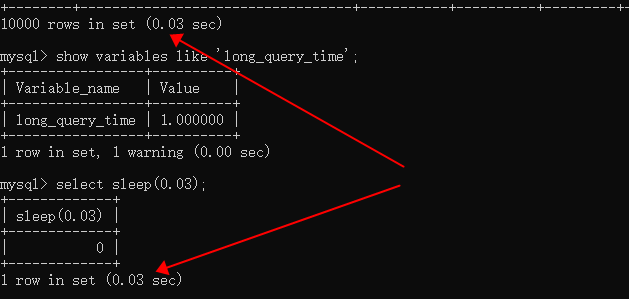

其实这里控制层显示的时间并不准确,都是四舍五入得到的
# Time: 2020-10-22T02:08:43.204364Z # User@Host: root[root] @ localhost [::1] Id: 8 # Query_time: 0.008021 Lock_time: 0.000083 Rows_sent: 10000 Rows_examined: 10000 SET timestamp=1603332523; select * from t_user;
这条慢日志太奇怪了,设置的慢查询时间是 1S ,这里远远不足1秒也记录到慢日志?
测试查询一条空数据(不走索引)


这里就基本得出结论, 可能是开启了log_queries_not_using_indexes ,之前得出结论不开启不显示是因为时间不够标准,所以未显示。这里开启不管是否满足慢日志,都会记录
现在将该配置关闭,慢日志时间修改为 1ms ,测试是否预期的结果?完全是预期的结果
配置为:
[mysqld] slow-query-log = on slow_query_log_file = D:/mysql-8.0.21-winx64/slowlog/slow.log # 单位为 s #long_query_time = 1 long_query_time = 0.001 log_queries_not_using_indexes = off
慢日志如下:
# Time: 2020-10-22T02:18:46.141286Z # User@Host: root[root] @ localhost [::1] Id: 8 # Query_time: 0.002123 Lock_time: 0.000111 Rows_sent: 19 Rows_examined: 601 SET timestamp=1603333126; show variables like 'log_%'; # Time: 2020-10-22T02:18:58.001322Z # User@Host: root[root] @ localhost [::1] Id: 8 # Query_time: 0.029329 Lock_time: 0.000330 Rows_sent: 10000 Rows_examined: 10000 SET timestamp=1603333137; select * from t_user; # Time: 2020-10-22T02:20:05.445874Z # User@Host: root[root] @ localhost [::1] Id: 8 # Query_time: 0.001510 Lock_time: 0.000113 Rows_sent: 1 Rows_examined: 0 SET timestamp=1603333205; explain select * from t_user where age >80; # Time: 2020-10-22T02:20:15.217001Z # User@Host: root[root] @ localhost [::1] Id: 8 # Query_time: 0.004319 Lock_time: 0.000082 Rows_sent: 2043 Rows_examined: 2043 SET timestamp=1603333215; select * from t_user where age >80;
二、explain 分析sql 执行过程

使用 explain 执行计划分析 SQL
id :查询序列号,值越大越优先执行
select_type:
- simple :简单查询
- primary :主查询
- subquery :子查询
- derived :导出表/衍生表,表示 from 后的查询
- union : 表示 union 后的的查询
- union result : 获取union 后的结果查询
table : 查询用到的表
type:
- system : 表示系统表,数据通常加载到内存中,不需要磁盘 io
- const :直接按主键或者唯一键值处理,最多只有一行
- eq_ref :使用唯一索引,对于每个索引键值,标志一条记录匹配(主键关联查询)
- ref :使用非唯一索引,可能返回多行
- range : 只检索指定范围的行,如 > , < ,= , between
- index : 索引全扫描,遍历整个索引来匹配
- all :全表扫描,性能最差
- NULL : 不用访问表/索引,可直接得出结果
possible_keys 与 key
possible_keys表示可能用到的所有,key 表示实际使用的索引
ken_len
使用到的索引字段长度
ref :
该张表的字段关联了哪张表的哪个字段
row:
表示扫描行的数量
Extra:
表示执行情况的说明和描述
- using index :使用覆盖索引的时候会出现
- using where :需要回表查询数据
- using index condition 查找使用了索引
- using filesort :使用了文件排序
- using yemporary : 使用了临时表来保存中间结果
三、使用 show profile 分析 sql
有时候通过 explain 分析执行计划并不能很快的定位 sql 的问题,这时候需要选择 profile 联合分析, mysql 5.x 开始增加 show profiles 和 show profile 语句的支持
默认profile 是关闭的 , 通过set 开启 session 级别的支持
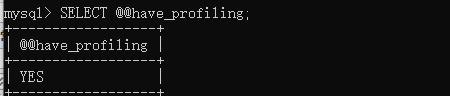
3.1 查看是否支持 profile
SELECT @@have_profiling
3.2 开启 profile session 级别的支持
set profiling=1;
3.3 执行 sql 语句
select * from t_user where age >95;
3.4 通过 show profiles 查询该sql 的 query id

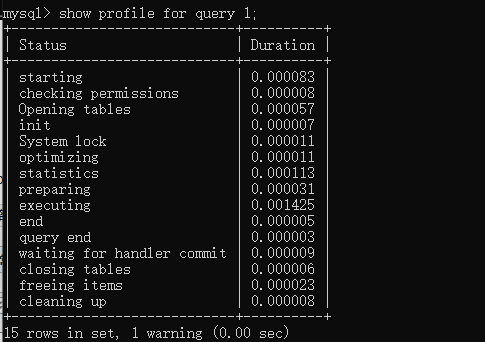
3.5 通过 show profile for query ID ,查看执行语句每个状态的消耗时间
show profile for query 1;
四、通过 trace 分析优化器如何选择执行过程
官方文档:https://dev.mysql.com/doc/internals/en/optimizer-tracing.html
MySQL 在5.6提供了对 sql 的跟踪 trace ,通过 trace 文件能够进一步了解优化器选择执行A计划而不选择执行B计划,帮助我们更好的理解优化器的行为
4.1 开启优化器,设置未 json 格式(默认关闭的)
SET OPTIMIZER_TRACE="enabled=on",END_MARKERS_IN_JSON=on;
4.2 设置内存,避免解析过程内存不足
SET OPTIMIZER_TRACE_MAX_MEM_SIZE=1000000;
4.3 执行 sql
select * from t_user where age >95;
4.4 检查INFORMATION_SCHEMA.OPTIMIZER_TRACE就知道mysql是如何执行sql的了
SELECT * FROM INFORMATION_SCHEMA.OPTIMIZER_TRACE;
4.5 完成后,关闭 trace
SET optimizer_trace="enabled=off";