1.前言
太久没有在数据库做一些复杂的sql了,基本上将数据库的查询逻辑全放在了Java里做,
一来呢,可以减轻数据库的负担,二来呢,在java写,逻辑感会更强,数据类型更丰富也容易操作。
然而。。。面试却喜欢靠复杂的sql ,好吧,即便我不想,但复习一波还是免不了的。
常用的关系型数据库有 MySQL和Oracle 。Oracle 比较喜欢使用存储过程做业务 ,当然,MySQL也可以,但是没怎么用,
自从工程使用mybatis框架,就不再使用存储过程了,业务基本是增删改查,查询数据的逻辑都是从数据库取相应数据出来后用Java计算,
再从数据库获取最终想要的数据,本来是本着减轻数据库负担才这样做的,并发操作会用上积极锁【乐观锁】,因此也就不需要担心 脏数据问题。
MySQL和Oracle的语法部分是不同的,有时候用着MySQL,写着写着就用上了Oracle的语法,还一脸懵逼的查了半天到底哪里错,不常使用的东西就是容易忘。
总结: (1)Oracle 使用nvl() 函数,MySQL使用 ifnull() 函数 来对数据进行判断是否为空, 如果是空则使用替代的数据 ,参数一样 ,如if(x.age,0),意思是如果年龄字段为空则 输出 0 . (2)sum()函数是运算函数,允许 加减乘除计算 ,如果要使用,则必须使用 group by 分组 ,限定好分组 sum获取的计算数据才不会错,否则将会导致全表计算在一起。 (3)avg()函数是计算平均数的,用法根据需要与 group by 分组配合使用, 如果是计算全表某字段的平均分,则不要使用。
(4)having 关键字可以筛选分组后的各组数据,也就是说可对分组完成后的数据做逻辑条件判断 ,与where类似,但是where无法这样使用,因为where关键字无法与聚合函数一起使用
2.复习题
数据库源码


/* Navicat MySQL Data Transfer Source Server : cen Source Server Version : 50528 Source Host : localhost:3306 Source Database : kktest Target Server Type : MYSQL Target Server Version : 50528 File Encoding : 65001 Date: 2020-06-17 08:21:15 */ SET FOREIGN_KEY_CHECKS=0; -- ---------------------------- -- Table structure for bjb -- ---------------------------- DROP TABLE IF EXISTS `bjb`; CREATE TABLE `bjb` ( `id` int(11) NOT NULL AUTO_INCREMENT, `name` varchar(20) DEFAULT NULL, PRIMARY KEY (`id`) ) ENGINE=InnoDB AUTO_INCREMENT=5 DEFAULT CHARSET=utf8; -- ---------------------------- -- Records of bjb -- ---------------------------- INSERT INTO `bjb` VALUES ('1', '一班'); INSERT INTO `bjb` VALUES ('2', '2班'); INSERT INTO `bjb` VALUES ('3', '3班'); -- ---------------------------- -- Table structure for cjb -- ---------------------------- DROP TABLE IF EXISTS `cjb`; CREATE TABLE `cjb` ( `id` int(11) NOT NULL AUTO_INCREMENT, `id_sx` int(11) DEFAULT NULL, `yw` int(11) DEFAULT NULL, `sx` int(11) DEFAULT NULL, PRIMARY KEY (`id`) ) ENGINE=InnoDB AUTO_INCREMENT=11 DEFAULT CHARSET=utf8; -- ---------------------------- -- Records of cjb -- ---------------------------- INSERT INTO `cjb` VALUES ('1', '1', '77', '67'); INSERT INTO `cjb` VALUES ('2', '2', '32', '27'); INSERT INTO `cjb` VALUES ('3', '3', '98', '78'); INSERT INTO `cjb` VALUES ('4', '4', '68', '63'); INSERT INTO `cjb` VALUES ('5', '5', '66', '77'); INSERT INTO `cjb` VALUES ('6', '6', '99', '88'); INSERT INTO `cjb` VALUES ('7', '7', '75', '45'); INSERT INTO `cjb` VALUES ('8', '8', '77', '88'); INSERT INTO `cjb` VALUES ('9', '9', '65', '81'); INSERT INTO `cjb` VALUES ('10', '10', '83', '89'); -- ---------------------------- -- Table structure for xsb -- ---------------------------- DROP TABLE IF EXISTS `xsb`; CREATE TABLE `xsb` ( `id` int(11) NOT NULL AUTO_INCREMENT, `name` varchar(20) DEFAULT NULL, `id_banji` int(11) DEFAULT NULL, PRIMARY KEY (`id`) ) ENGINE=InnoDB AUTO_INCREMENT=12 DEFAULT CHARSET=utf8; -- ---------------------------- -- Records of xsb -- ---------------------------- INSERT INTO `xsb` VALUES ('1', '岑', '1'); INSERT INTO `xsb` VALUES ('2', 'cen', '1'); INSERT INTO `xsb` VALUES ('3', 'y', '2'); INSERT INTO `xsb` VALUES ('4', 'u', '3'); INSERT INTO `xsb` VALUES ('5', 'yue', '2'); INSERT INTO `xsb` VALUES ('6', 'kk', '2'); INSERT INTO `xsb` VALUES ('7', 'tom', '1'); INSERT INTO `xsb` VALUES ('8', 'lili', '1'); INSERT INTO `xsb` VALUES ('9', 'kile', '3'); INSERT INTO `xsb` VALUES ('10', 'jack', '2'); INSERT INTO `xsb` VALUES ('11', 'hh', '2'); -- ---------------------------- -- Procedure structure for sp_add3 -- ---------------------------- DROP PROCEDURE IF EXISTS `sp_add3`; DELIMITER ;; CREATE DEFINER=`root`@`localhost` PROCEDURE `sp_add3`(a int, b int,out c int) begin set c=a+ b; end ;; DELIMITER ;
学生表【字段意思:学生id、姓名、班级id】
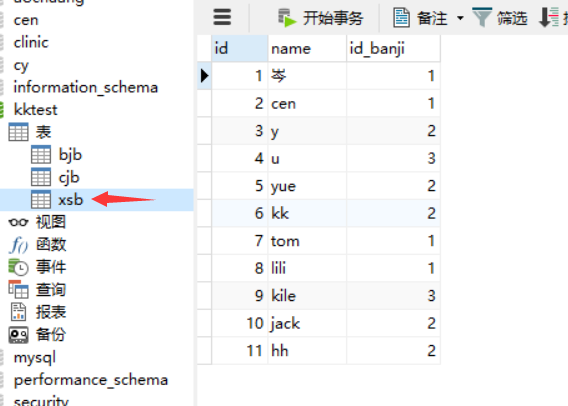
班级表【字段意思:班级id、班级名称】
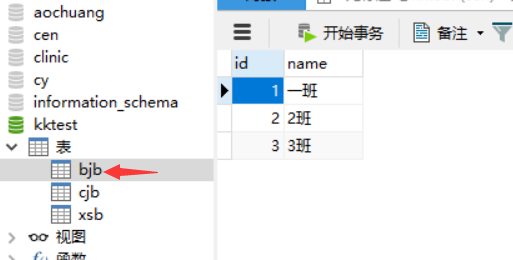
成绩表【字段意思:成绩id、学生id、语文成绩、数学成绩】

【注意:11号同学hh ,他没有成绩,他作弊被取消了考试资格,因此成绩表没有他的信息】
(1)查询所有学生的信息
写法一:
select x.id,x.name,b.name n from xsb x
left join bjb b on b.id = x.id_banji;
查询结果

写法二:
select x.id,x.name,b.name n2 from xsb x,bjb b
where b.id = x.id_banji;
查询结果与上图一样
(2)查询所有人的课程分数
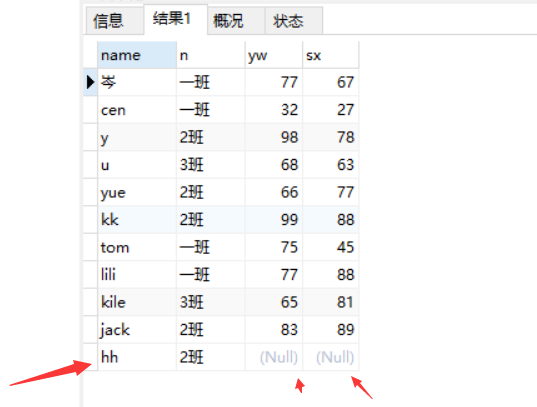
写法一:【查询11号同学为null】
select x.name,b.name n ,c.yw ,c.sx from xsb x left join bjb b on b.id = x.id_banji left join cjb c on c.id_sx = x.id ;
查询结果
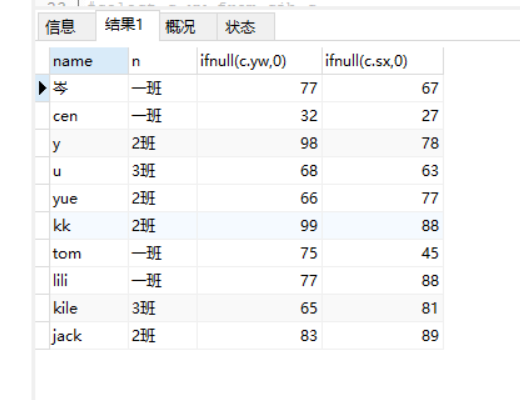
写法二:【查询11号同学为0】
select x.name,b.name n , ifnull(c.yw,0) , ifnull(c.sx,0) from xsb x left join bjb b on b.id = x.id_banji left join cjb c on c.id_sx = x.id ;
查询结果

写法三:【查询无11号同学】不使用left join会导致没有成绩的那个同学不显示,因为直接连表查询只会保留所有关联条件成立的数据
select x.name,b.name n , ifnull(c.yw,0) , ifnull(c.sx,0) from xsb x,bjb b,cjb c WHERE b.id = x.id_banji and c.id_sx = x.id ;
查询结果
(3)查询语文分数比“yue”的高的学生,【 如果是查询比“yue”的低, 不使用ifnull那么没有成绩的同学无法查看到】
select x.name,b.name n , ifnull(c.yw,0) from xsb x left join bjb b on b.id = x.id_banji left join cjb c on c.id_sx = x.id where ifnull(c.yw,0) > ( select c.yw from cjb c left join xsb x on c.id_sx = x.id where x.name= "yue" )
查询结果
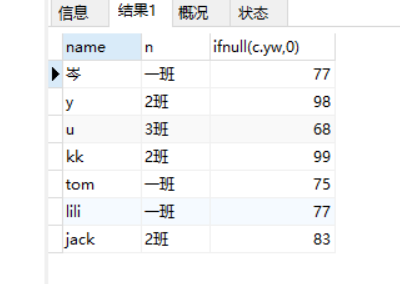
(4)查询各科都合格【分数>=60分】的学生(姓名、语文分数、数学分数)
select x.name , c.yw ,c.sx from xsb x left join cjb c on c.id_sx =x.id WHERE c.yw>60 and c.sx >60
打印结果
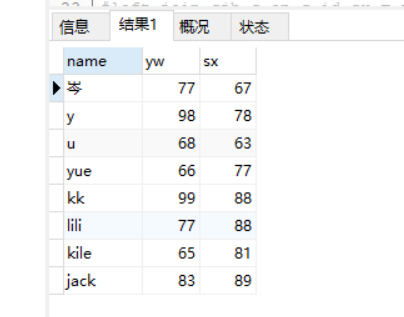
(5)查询总分数(语文+数学)>=150的学生信息(姓名、班级名称、总分数)
select x.name,b.name n , ifnull(c.yw,0) as "语文",ifnull(c.sx,0) as "数学", #sum是运算函数 ,在里面可以做加减乘除 sum(ifnull(c.yw,0) + ifnull(c.sx,0)) as "总分" from xsb x left join bjb b on b.id = x.id_banji left join cjb c on c.id_sx = x.id where (ifnull(c.yw,0) +ifnull(c.sx,0)) >=150 #计算总分必须要分组,加上这个GROUP BY x.id,表示以一位学生为一组计算总分,否则会全部加在一起 GROUP BY x.id
查询结果
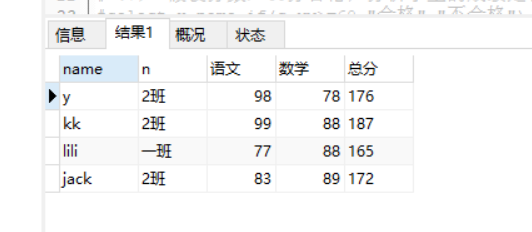
(6)查询没有参加考试【没有成绩表】的学生(姓名、班级名称)
写法一:
select x.name,b.name n from xsb x left join bjb b on b.id = x.id_banji left join cjb c on c.id_sx = x.id where x.id not in (select id_sx from cjb);
查询结果
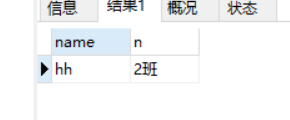
写法二:
select x.name,b.name n from xsb x ,bjb b ,cjb c WHERE x.id_banji = b.id and x.id not in (select id_sx from cjb) GROUP BY x.name,b.name ;
查询结果与上图一样
(7)假设分数>=60分合格,分析学生的成绩是否合格
select x.name,if(c.yw>=60,"合格","不合格") as "语文成绩" , if(c.sx>=60,"合格","不合格") as "数学成绩" from xsb x left join cjb c on c.id_sx = x.id
查询结果

(8)查询有挂科【分数<60分】现象的学生(姓名、语文分数、数学分数)
select x.name ,ifnull( c.yw ,0),ifnull(c.sx,0) from xsb x left join cjb c on c.id_sx =x.id WHERE ifnull( c.yw ,0) <60 or ifnull(c.sx,0)<60;
查询结果
(9)查询所有班级的平均分数(班级编号、班级名称、语文平均分数、数学平均分数)
写法一:
select b.name , AVG(c.yw) as "语文平均分数" ,AVG(c.sx) as "数学平均分数" from xsb x left join bjb b on b.id = x.id_banji left join cjb c on c.id_sx = x.id GROUP BY b.id ;
查询结果

写法二:【主从表换了没影响】
select b.name , AVG(c.yw) as "语文平均分数" ,AVG(c.sx) as "数学平均分数" from bjb b left join xsb x on b.id = x.id_banji left join cjb c on c.id_sx = x.id GROUP BY b.id
查询结果与上图一样
(10)查询班级人数>=3的班级(班级编号、班级名称、人数)
select b.id ,b.name , count(x.id) as "人数" from bjb b left join xsb x on b.id = x.id_banji #HAVING 子句可以让我们筛选分组后的各组数据。 group by b.id having count(x.id) >=3
查询结果
