一、概念
Hadoop是一个能够对大量数据进行分布式处理的软件框架,充分利用集群的威力进行高速运算和存储。
二、主要模块
Hadoop Common:支持其他Hadoop模块的常用实用程序。
Hadoop分布式文件系统(HDFS™):一种分布式文件系统,可提供对应用程序数据的高吞吐量访问。
Hadoop YARN:作业调度和集群资源管理的框架。
Hadoop MapReduce:基于YARN的系统,用于并行处理大型数据集。
Hadoop Ozone: Hadoop的对象存储。
Hadoop的框架最核心的设计就是:HDFS和MapReduce。HDFS为海量的数据提供了存储,而MapReduce则为海量的数据提供了计算。
三、存储模型(化整为零 并行计算 分而治之)
1、Block:
将文件按照确定大小(除最后一块)的字节(byte)线性切割,切出来的每一块叫Block;
不同文件可以按照不同长度切割;
Hadoop2.X以上,大小可以设置为1M-128M;默认3个副本,大小和副本数都可以设置;
Block支持一次写入多次读取,同一时刻只有一个写入者(即:不允许修改)
2、偏移量offset:被切割成的Block的线性标识,比如第一个Block偏移量是0,第二Block就是0+第一个Block字节数,...
3、副本:Block可以设置副本数(默认3个),副本数不多于节点数;
副本分散于不同节点上,避免单点故障;
副本之间优先级相同;
四、副本放置策略
第一个副本:放置在上传文件的DN;如果是集群外提交,则随机挑选一台磁盘不太满,CPU不太忙的节点。
第二个副本:放置在于第一个副本不同的 机架的节点上。
第三个副本:与第二个副本相同机架的节点。
更多副本:随机节点

五、架构模型
1、元数据metaData:描述文件属性信息(stat file)
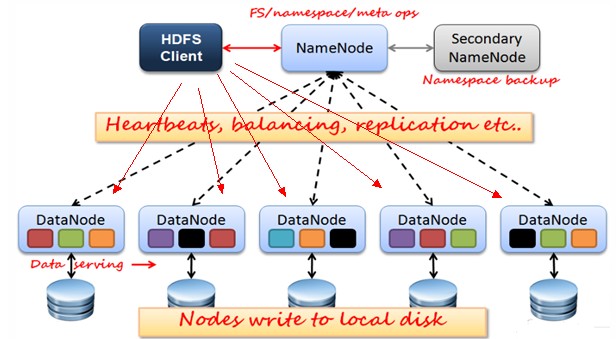
2、NameNode节点(主:单节点):保存和管理文件元数据
3、DataNode节点(从:集群):保存和处理文件内容数据,利用服务武器本地文件系统存储数据
4、DataNode与NameNode保持心跳,提交Block列表
5、HdfsClient与NameNode交互元数据信息
6、HdfsClient与DataNode交互文件Block数据
六、NameNode、DataNode、SecondaryNameNode
1、区分NN、DN、SNN
NameNode:是Master节点,是大领导。管理数据块映射;处理客户端的读写请求;配置副本策略;管理HDFS的名称空间;
SecondaryNameNode:是一个小弟,分担大哥namenode的工作量;是NameNode的冷备份;合并fsimage和fsedits然后再发给namenode。
DataNode:Slave节点,奴隶,干活的。负责存储client发来的数据块block;执行数据块的读写操作。
热备份:b是a的热备份,如果a坏掉。那么b马上运行代替a的工作。
冷备份:b是a的冷备份,如果a坏掉。那么b不能马上代替a工作。但是b上存储a的一些信息,减少a坏掉之后的损失。
fsimage:元数据镜像文件(文件系统的目录树。)
edits:元数据的操作日志(针对文件系统做的修改操作记录)
namenode内存中存储的是=fsimage+edits。
SecondaryNameNode负责定时默认1小时,从namenode上,获取fsimage和edits来进行合并,然后再发送给namenode。减少namenode的工作量。
2、客户端读取数据流程
读取文件时候,读取文件时Namenode尽量让用户先读取最近的副本,降低带块消耗和读取延时
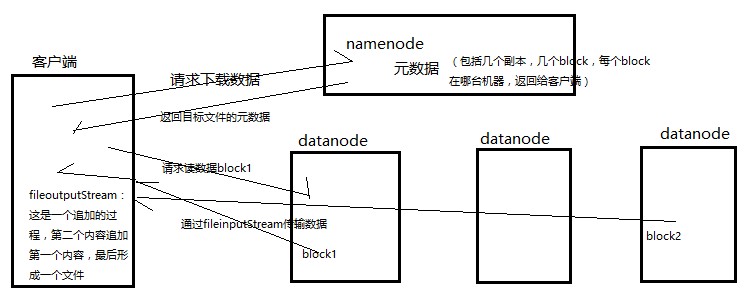
3、客户端写数据流程

写流程中注意:
1. 传输通道中以packet为单位传输,一个packet是64K,以packet里的chunk为单位校验;
2. block要有一个成功上传,就算成功了,之后namenode会做异步的同步,每传输一个block都会向namenode请求。
3. 上传数据时,datanode的选择策略:
1)第一个副本先考虑跟client端最近的(同机架)
2)第二个副本再考虑跨机架挑选一个datanode,增加副本的可靠性;
3)第三个副本就在第二个副本同机架另外挑选一个datanode存放;
原理:
NameNode具有RackAware机架感知功能,这个可以配置。
若client为DataNode节点,那存储block时,规则为:副本1,同client的节点上;副本2,不同机架节点上;副本3,同第二个副本机架的另一个节点上;其他副本随机挑选。
若client不为DataNode节点,那存储block时,规则为:副本1,随机选择一个节点上;副本2,不同副本1,机架上;副本3,同副本2相同的另一个节点上;其他副本随机挑选。
4. client向DataNode发送block1;发送过程是以流式写入。
流式写入过程,
1>将64M的block1按64k的package划分;
2>然后将第一个package发送给dn1;
3>dn1接收完后,将第一个package发送给dn2,client想dn1发送第二个package;
4>dn2接收完第一个package后,发送给dn3,同时接收dn1发来的第二个package。
5>以此类推,直到将block1发送完毕。
6>dn1,dn2,dn3向NameNode,dn1向Client发送通知,说“消息发送完了”。
7>client收到dn1发来的消息后,向namenode发送消息,说我写完了。这样就真完成了。
8>发送完block1后,再发送block2。
9>发送完block2后,向Client发送通知
10>client向NameNode发送消息,说我写完了,这样就完毕了。
分析,通过写过程,我们可以了解到:
①写1T文件,我们需要3T的存储,3T的网络流量贷款。
②在执行读或写的过程中,NameNode和DataNode通过HeartBeat进行保存通信,确定DataNode活着。如果发现DataNode死掉了,就将死掉的DataNode上的数据,放到其他节点去。读取时,要读其他节点去。
③挂掉一个节点,没关系,还有其他节点可以备份;甚至,挂掉某一个机架,也没关系;其他机架上,也有备份。
4、SecondaryNameNode合并数据流程

参考:
Hadoop的HDFS中namenode和datenode内容分析
七、Federation
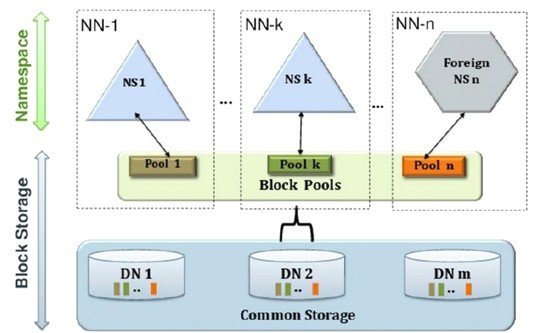
HDFS Federation是解决NameNode单点问题的水平横向扩展方案.
目前HA方式以已经满足绝大多数需求,HDFS Federation用的比较少。
总结三点:
(1)多个 NN 共用一个集群里的存储资源,每个 NN 都可以单独对外提供服务。
(2)每个 NN 都会定义一个存储池,有单独的 id,每个 DN 都为所有存储池提供存储。
(3)DN 会按照存储池 id 向其对应的 NN 汇报块信息,同时,DN 会向所有 NN 汇报本地存储可用资源情况。
优点:
第一点,命名空间的扩展.因为随着集群使用时间的加长,HDFS上存放的数据也将会越来越多.这个时候如果还是将所有的数据都往一个NameNode上存放,这个文件系统会显得非常的庞大.这时候我们可以进行横向扩展,把一些大的目录分离出去.使得每个NameNode下的数据看起来更加的精简.
第二点,性能的提升.这个也很好理解.当NameNode所持有的数据量达到了一个非常大规模的量级的时候(比如超过1亿个文件),这个时候NameNode的处理效率可能就会有影响,它可能比较容易的会陷入一个繁忙的状态.而整个集群将会受限于一个单点NameNode的处理效率,从而影响集群整体的吞吐量.这个时候多NameNode机制显然可以减轻很多这部分的压力.
第三点,资源的隔离.这一点考虑的就比较深了.通过多个命名空间,我们可以将关键数据文件目录移到不同的NameNode上,以此不让这些关键数据的读写操作受到其他普通文件读写操作的影响.也就是说这些NameNode将会只处理特定的关键的任务所发来的请求,而屏蔽了其他普通任务的文件读写请求,以此做到了资源的隔离.千万不要小看这一点,当你发现NameNode正在处理某个不良任务的大规模的请求操作导致响应速度极慢时,你一定会非常的懊恼.
https://blog.csdn.net/androidlushangderen/article/details/52135506
http://www.cnblogs.com/jifengblog/p/9307702.html