环境
虚拟机:VMware 10
Linux版本:CentOS-6.5-x86_64
客户端:Xshell4
FTP:Xftp4
jdk8
redis-2.8.18
什么是持久化?
将数据从掉电易失的内存存放到能够永久存储的设备上
Redis持久化方式:
RDB(Redis DB) 类似 hdfs:fsimage 快照
AOF(AppendOnlyFile) 类似 hdfs :edit logs 关闭的
一、RDB
在默认情况下,Redis 将数据库快照保存在名字为dump.rdb的二进制文件中
方式:
(1)阻塞方式:客户端中执行save命令,无法响应客户端请求,创建新的dump.rdb替代旧文件
SAVE不用创建新的进程,速度略快;适合停机维护,服务低谷时段
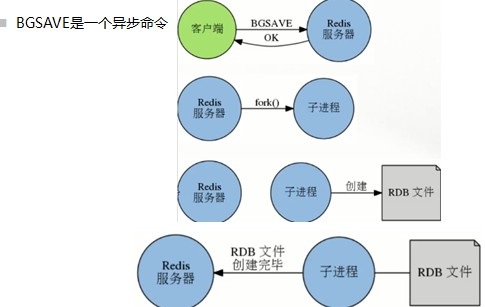
(2)非阻塞方式:bgsave
非阻塞,Redis服务正常接收处理客户端请求;BGSAVE需要创建子进程,消耗额外的内存;适合线上执行
Redis会fork()一个新的子进程来创建RDB文件,子进程处理完后会向父进程发送一个信号,通知它处理完毕
父进程用新的dump.rdb替代旧文件
策略
手动:客户端发起SAVE、BGSAVE命令
自动:按照配置文件中的条件满足就执行BGSAVE
save 60 1000,Redis要满足在60秒内至少有1000个键被改动,会自动保存一次
默认配置
save 900 1 save 300 10 save 60 10000 dbfilename dump.rdb dir /var/lib/redis/6379
只要上面三个条件满足一个,就自动执行备份。
创建RDB文件之后,时间计数器和次数计数器会清零。所以多个条件的效果不是叠加的
优点
完全备份,不同时间的数据集备份可以做到多版本恢复
紧凑的单一文件,方便网络传输,适合灾难恢复
恢复大数据集速度较AOF快
缺点
会丢失最近写入、修改的而未能持久化的数据
fork过程非常耗时,会造成毫秒级不能响应客户端请求
生产环境
创建一个定时任务cron job,每小时或者每天将dump.rdb复制到指定目录
确保备份文件名称带有日期时间信息,便于管理和还原对应的时间点的快照版本
定时任务删除过期的备份
如果有必要,跨物理主机、跨机架、异地备份
二、AOF
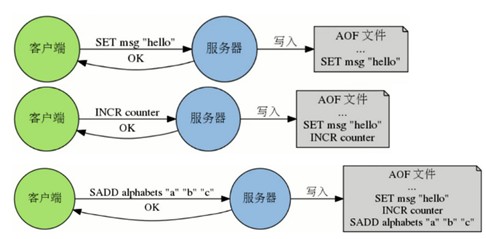
Append only file,采用追加的方式保存;
默认文件appendonly.aof;
调整AOF持久化策略,可以在服务出现故障时,不丢失任何数据,也可以丢失一秒的数据。相对于RDB损失小得多;
记录所有的写操作命令,在服务启动的时候使用这些命令就可以还原数据库;
(1)AOF写入机制
AOF方式不能保证绝对不丢失数据
目前常见的操作系统中,执行系统调用write函数,将一些内容写入到某个文件里面时,为了提高效率,系统通常不会直接将内容写入硬盘里面,而是先将内容放入一个内存缓冲区(buffer)里面,等到缓冲区被填满,或者用户执行fsync调用和fdatasync调用时才将储存在缓冲区里的内容真正的写入到硬盘里,未写入磁盘之前,数据可能会丢失
(2)写入磁盘的策略
appendfsync选项,这个选项的值可以是always、everysec或者no
Always:服务器每写入一个命令,就调用一次fdatasync,将缓冲区里面的命令写入到硬盘。这种模式下,服务器出现故障,也不会丢失任何已经成功执行的命令数据
Everysec(默认):服务器每一秒重调用一次fdatasync,将缓冲区里面的命令写入到硬盘。这种模式下,服务器出现故障,最多只丢失一秒钟内的执行的命令数据
No:服务器不主动调用fdatasync,由操作系统决定何时将缓冲区里面的命令写入到硬盘。这种模式下,服务器遭遇意外停机时,丢失命令的数量是不确定的
运行速度:always的速度慢,everysec和no都很快
(3)AOF重写机制
AOF文件过大,合并重复的操作,AOF会使用尽可能少的命令来记录
重写过程
fork一个子进程负责重写AOF文件
子进程会创建一个临时文件写入AOF信息
父进程会开辟一个内存缓冲区接收新的写命令
子进程重写完成后,父进程会获得一个信号,将父进程接收到的新的写操作由子进程写入到临时文件中
新文件替代旧文件
注:如果写入操作的时候出现故障导致命令写半截,可以使用redis-check-aof工具修复

AOF重写触发
手动:客户端向服务器发送BGREWRITEAOF命令
自动:配置文件中的选项,自动执行BGREWRITEAOF命令
auto-aof-rewrite-min-size <size>,触发AOF重写所需的最小体积:只要在AOF文件的体积大于等于size时,才会考虑是否需要进行AOF重写,这个选项用于避免对体积过小的AOF文件进行重写
auto-aof-rewrite-percentage <percent>,指定触发重写所需的AOF文件体积百分比:当AOF文件的体积大于auto-aof-rewrite-min-size指定的体积,并且超过上一次重写之后的AOF文件体积的percent %时,就会触发AOF重写。(如果服务器刚刚启动不久,还没有进行过AOF重写,那么使用服务器启动时载入的AOF文件的体积来作为基准值)。将这个值设置为0表示关闭自动AOF重写
举例
auto-aof-rewrite-percentage 100
auto-aof-rewrite-min-size 64mb
appendonly yes #默认关闭no,请开启 yes
当AOF文件大于64MB时候,可以考虑重写AOF文件
只有当AOF文件的增量大于起始size的100%时(就是文件大小翻了一倍),启动重写
优点
写入机制,默认fysnc每秒执行,性能很好不阻塞服务,最多丢失一秒的数据
重写机制,优化AOF文件
如果误操作了(FLUSHALL等),只要AOF未被重写,停止服务移除AOF文件尾部FLUSHALL命令,重启Redis,可以将数据集恢复到 FLUSHALL 执行之前的状态
缺点
相同数据集,AOF文件体积较RDB大了很多
恢复数据库速度叫RDB慢(文本,命令重演)