环境
spark-1.6
python3.5
一、python开发spark原理
使用python api编写pyspark代码提交运行时,为了不破坏spark原有的运行架构,会将写好的代码首先在python解析器中运行(cpython),Spark代码归根结底是运行在JVM中的,这里python借助Py4j实现Python和Java的交互,即通过Py4j将pyspark代码“解析”到JVM中去运行。例如,在pyspark代码中实例化一个SparkContext对象,那么通过py4j最终在JVM中会创建scala的SparkContext对象及后期对象的调用、在JVM中数据处理消息的日志会返回到python进程中、如果在代码中会回收大量结果数据到Driver端中,也会通过socket通信返回到python进程中。这样在python进程和JVM进程之间就有大量通信。
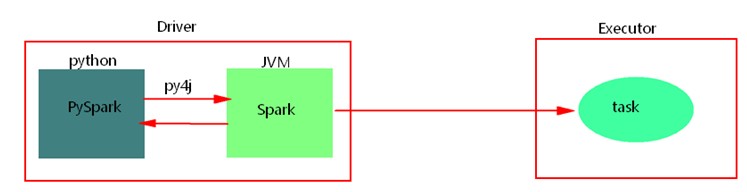
python开发spark,需要进行大量的进程间的通信,如果通信量过大,会出现“socket write error”错误,应尽量少使用回收数据类算子,也可以调节回收日志的级别,降低进程之间的通信。
二、搭建
这里使用Spark1.6版本,由于Spark2.1以下版本不支持python3.6版本,所以我们使用兼容性比较好的Python3.5版本。
步骤一:搭建python3.5环境
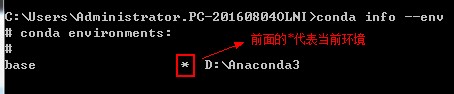
(1)conda info --env可以看到所有python环境,前面有个‘*’的代表当前环境
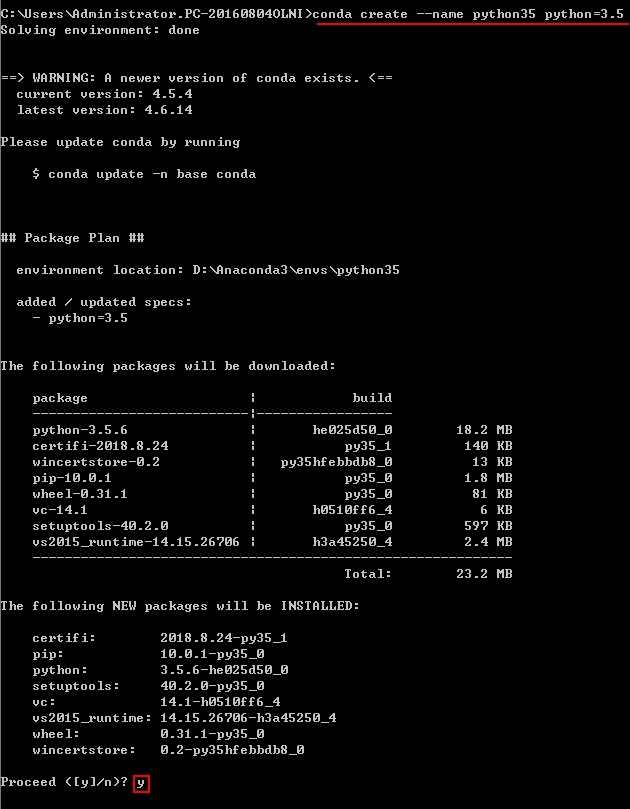
(2)创建Python3.5环境
conda create --name python35 python=3.5
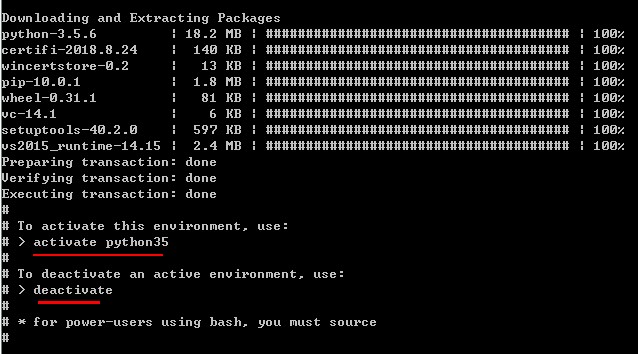
创建成功之后:

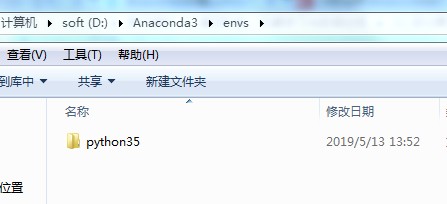
(3)激活python35:

步骤二:安装spark
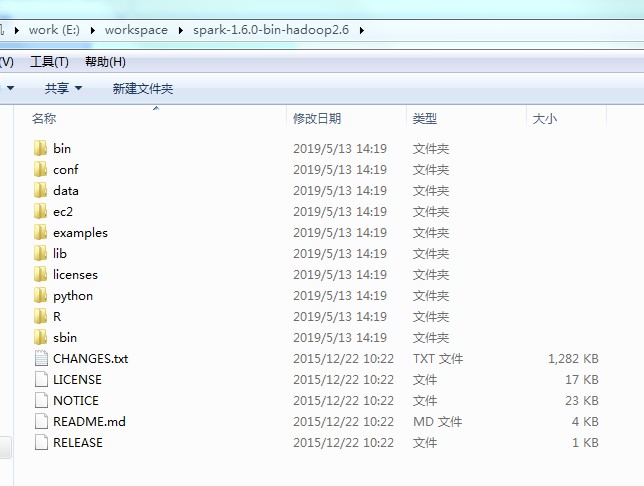
(1)下载spark-1.6.0-bin-hadoop2.6

官网下载:https://archive.apache.org/dist/spark/spark-1.6.3/

(2)解压到本地目录下,这里是:E:workspacespark-1.6.0-bin-hadoop2.6
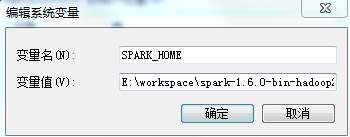
(3)配置环境变量:SPARK_HOME
步骤三:安装py4j、pyspark
★py4j是一个用Python和Java编写的库。通过Py4J,Python程序能够动态访问Java虚拟机中的Java对象,Java程序也能够回调Python对象。
★pyspark是Spark为Python开发者提供的 API。
方式一:可以通过pip安装,但是默认安装最新版本,我们这里需要的是和spark1.6相匹配的版本(不推荐)
安装:
pip install py4j
pip install pyspark
卸载:
pip uninstall py4j
pip uninstall pyspark
方式二:通过spark安装包拷贝(推荐)
进入目录:E:workspacespark-1.6.0-bin-hadoop2.6pythonlib,将py4j-0.9-src.zip、pyspark.zip解压后将py4j、pyspark拷贝到:D:Anaconda3envspython35Libsite-packages
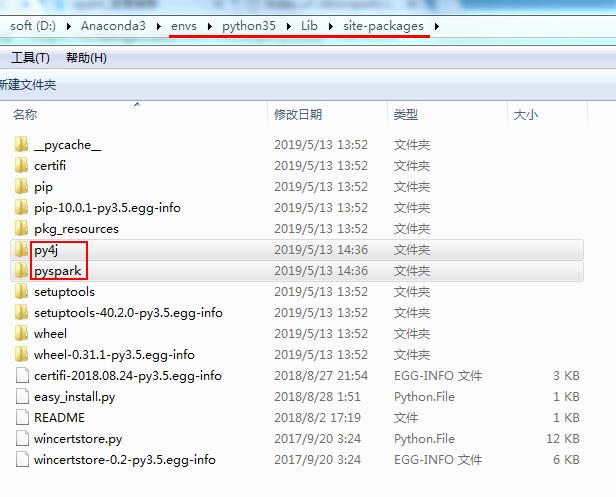
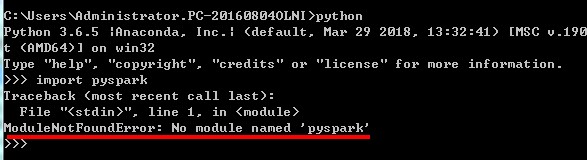
验证:导入包 不报错就OK

否则,会报错:
三、IDE搭建
1、eclipse
(1)eclipse中开发python程序,需要安装pydev插件。eclipse要求4.7以上,下载python插件包PyDev.zip(http://www.pydev.org/download.html),解压后加压拷贝到eclipse的dropins中,重启即可。
(2)配置python35解释器

(3)配置SPARK_HOME,设置环境变量,需要重启eclipse
否则报错:KeyError: 'SPARK_HOME'
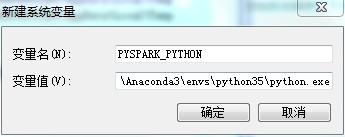
(4)配置PYSPARK_PYTHON
如果使用的anaconda更换了python3.5.x版本,之后在开发工具中指定了python解析器为3.5.x版本之后,运行python spark 代码时spark默认的使用的python版本可能使环境变量中指定的版本。会导致与指定的python解析器的python版本不一致。这时需要在环境变量中指定下PYSPARK_PYTHON环境变量即可,值为指定的python3.5.x python解析器。
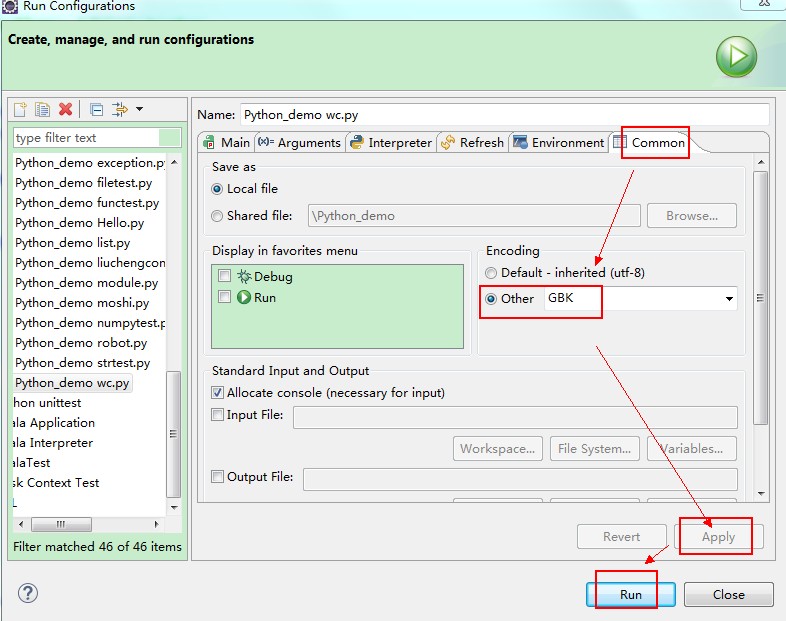
(5)配置控制台编码
eclipse控制台只支持GBK编码。运行时需要修改编码,运行python文件时,右键->Run As->Run Configurations->Common->Encoding 改为GBK
乱码:
�ɹ�: ����ֹ PID 940 (���� PID 2312 �ӽ���)�Ľ��̡� �ɹ�: ����ֹ PID 2312 (���� PID 3992 �ӽ���)�Ľ��̡� �ɹ�: ����ֹ PID 3992 (���� PID 5664 �ӽ���)�Ľ��̡�
设置:
修正后:
成功: 已终止 PID 5796 (属于 PID 6888 子进程)的进程。 成功: 已终止 PID 6888 (属于 PID 1836 子进程)的进程。 成功: 已终止 PID 1836 (属于 PID 2088 子进程)的进程。
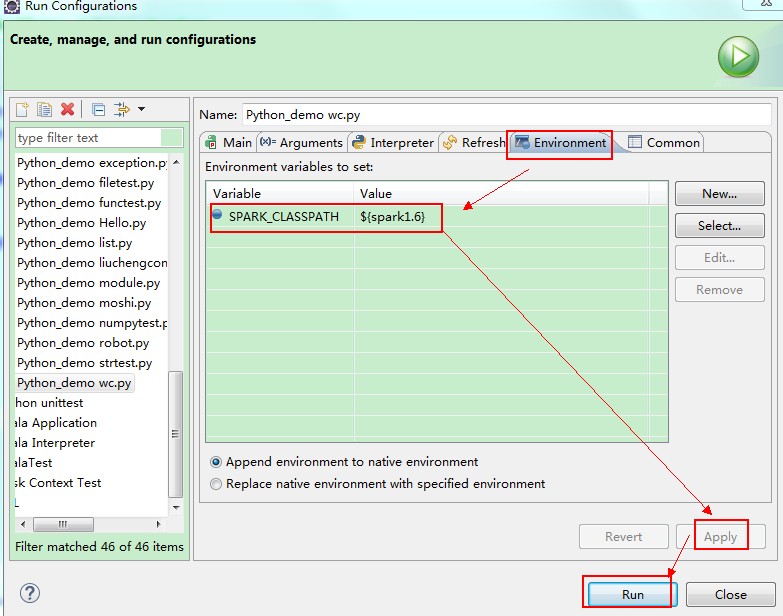
(6)python开发spark设置外部依赖包
<1>本地测试可以通过Run As -> Run Configuration->Environment来设置SPARK_CLASSPATH 指定依赖的jar包:
<2>集群中提交任务,需要指定依赖的jar包,可以通过--jars或者—driver-class-path来指定依赖的jar包。也可以在集群spark中../conf/spark-defaults.conf中设置变量spark.driver.extraClassPath或者spark.executor.extraClassPath来指定pySpark依赖的jar包。
例如:如果使用python来开发SparkStreaming Application 还需要在进行如下配置:
在conf目录的spark-default.conf目录下添加两行配置信息
spark.driver.extraClassPath F:/spark-1.6.0-bin-hadoop2.6/lib/spark-streaming-kafka-assembly_2.10-1.6.0.jar spark.executor.extraClassPath F:/spark-1.6.0-bin-hadoop2.6/lib/spark-streaming-kafka-assembly_2.10-1.6.0.jar
2、PyCharm
PyCharm2018破解:https://blog.csdn.net/u012278016/article/details/81738676
(1)创建新的python项目

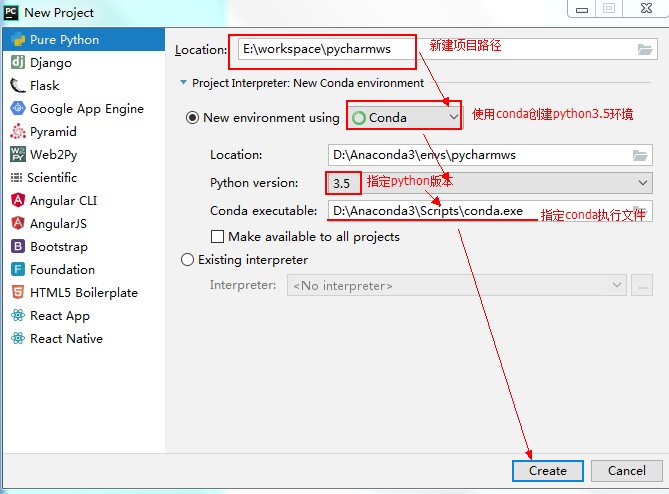
(2)使用PyCharm创建python3.5环境
不同的python项目,可能需要不同的python版本
第一种:使用conda创建新环境
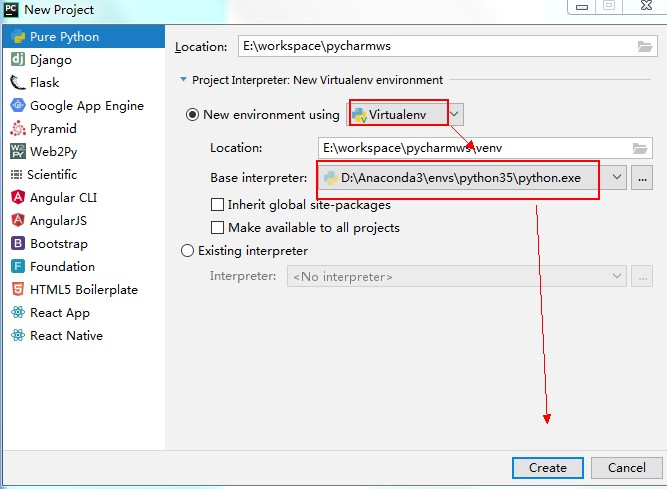
第二种:使用已有虚拟环境
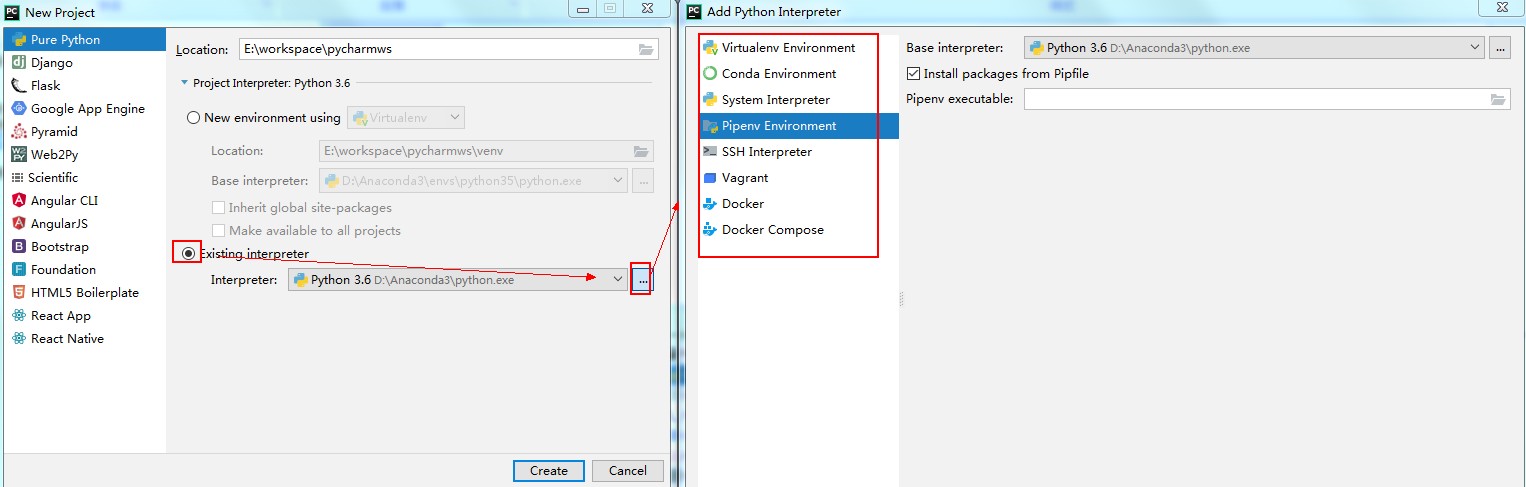
第三种:使用已有其他的环境
(2)配置python对spark的依赖包
选中项目,然后选择点击File->Settings…->点击 Project:xxx:->Project Structure


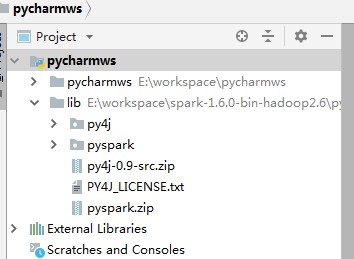
(3)配置SPAKR_HOME,否则报错:KeyError: 'SPARK_HOME'
方式一:设置某个python文件运行变量


方式二:设置所有文件默认运行变量

方式三:配置系统环境变量SPAKR_HOME,设置后需要重启PyCharm
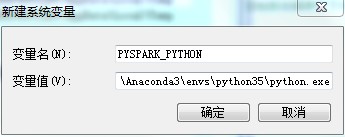
(4)配置PYSPARK_PYTHON
配置spark使用的python版本,否则有可能报错

方式一:代码中设置
import os os.environ["PYSPARK_PYTHON"] = "D:\Anaconda3\envs\python35\python.exe"
方式二:设置PyCharm运行变量

方式三:设置操作系统环境变量 需要重启PyCharm
(5)设置 python代码模板
File->Setting->File and Code Templates

PyCharm中的文件模版变量:
${PROJECT_NAME} - 当前的项目名
${NAME} - 在文件创建过程中,新文件对话框的命名
${USER} - 当前的登录用户
${DATE} - 现在的系统日期
${TIME} - 现在的系统时间
${YEAR} - 当前年份
${MONTH} - 当前月份
${DAY} - 当前月份中的第几日
${HOUR} - 现在的小时
${MINUTE} - 现在的分钟
${PRODUCT_NAME} - IDE创建文件的名称
${MONTH_NAME_SHORT} - 月份的前三个字母缩写
${MONTH_NAME_FULL} - 完整的月份名
注意:
jdk、Anaconda、python、Spark的安装路径中不能有空格和中文。